Small models destroy giants - ModernVBERT's 250M parameters match models 10x larger while DocPruner cuts storage by 60%. Smart architecture wins.
AI agents work for days straight - Claude Sonnet 4.5 codes for 30+ hours without stopping. Alibaba's Qwen3-VL matches GPT-5 with just 3B active parameters. Autonomous systems that actually work are almost here.
Commercial AI gets real - Sora 2 launches with revenue sharing for creators. Claude ships with enterprise controls. The research phase is over. This is business now.
🧠 Research Highlights
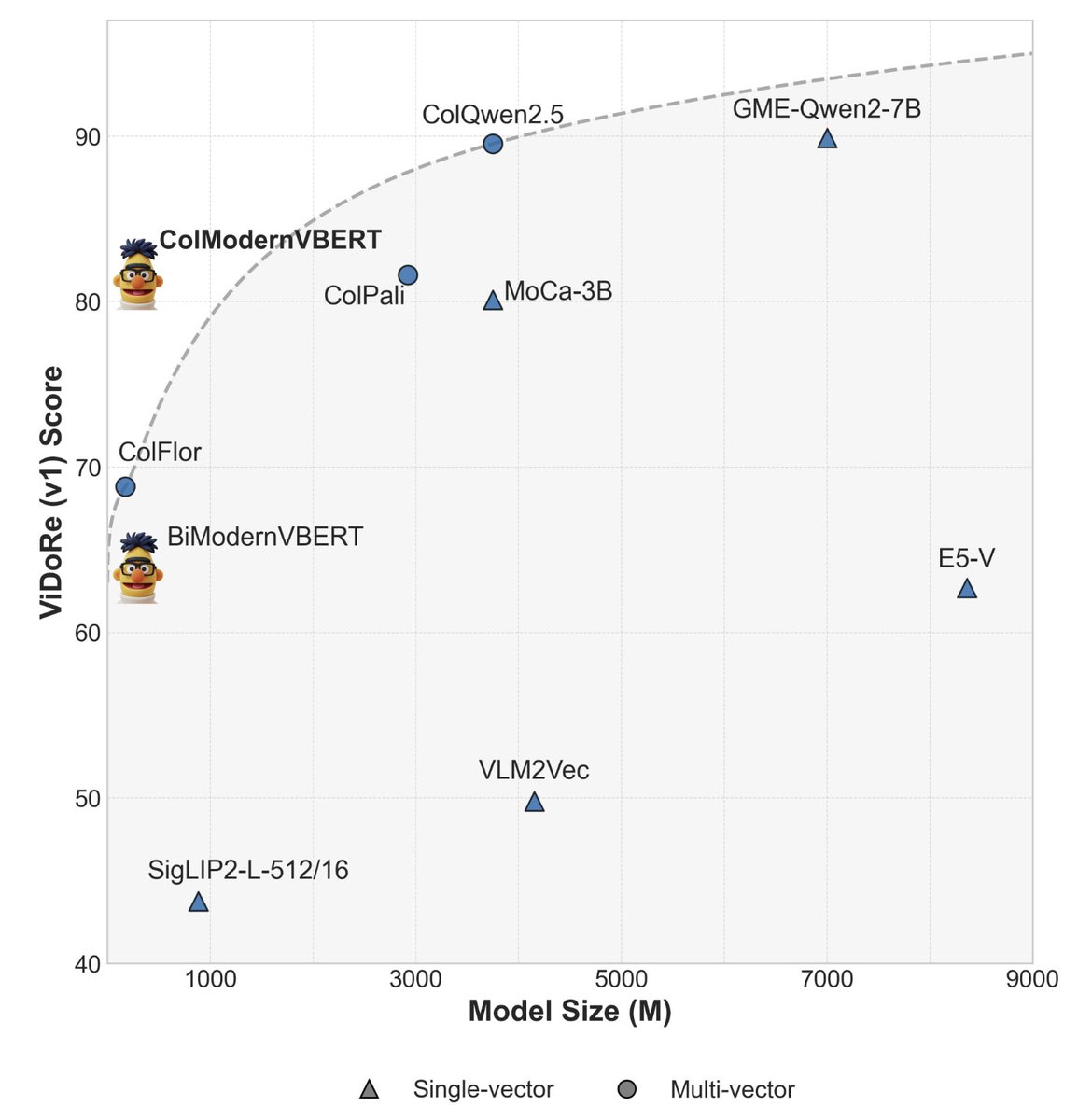
ModernVBERT: Towards Smaller Visual Document Retrievers
EPFL researchers built a 250M parameter model that matches systems 10x larger on document retrieval. They discovered bidirectional attention beats causal attention by +10.6 nDCG@5 for retrieval, and that mixing text-only pairs with image-text during training fixes data scarcity through cross-modal transfer.
Why It Matters: You can now run state-of-the-art document retrieval on devices that couldn't even load traditional models. Links:Twitter | Paper | HuggingFace | Colab
DocPruner: A Storage-Efficient Framework for Multi-Vector Visual Document Retrieval
DocPruner slashes storage for visual document retrieval by 50-60% without hurting performance. The system analyzes attention scores to identify which patches matter, then adapts pruning intensity per document—aggressively cutting sparse pages while preserving dense ones.
The illustration of comparison between OCR-based (a) & LVLM-based (b) paradigms for VDR, and DocPruner (c), a novel framework to adaptively prune the patch-level embeddings for diverse document types.
Why It Matters: Multi-vector retrieval becomes affordable at scale when you cut storage costs in half. Links:Paper
LEAML: Label-Efficient Adaptation to Out-of-Distribution Visual Tasks
LEAML adapts multimodal models to specialized domains like medical imaging using minimal labeled data plus unlabeled samples. The framework turns abundant unlabeled visual content into useful training signal when expert annotations are expensive or impossible to obtain.
Overview of the proposed two-stage LEAML framework for OOD VQA adaptation. In Pseudo QA Generation, the QA Generator is trained using a small set of labeled question-answer pairs and then used to generate pseudo QA pairs for a large collection of unlabeled images. In OOD VQA Finetuning, the VQA model is fine-tuned with both the original labeled data and the produced pseudo QA pairs of unlabeled data, enabling label-efficient adaptation to out-of-distribution visual-question answering.
CCDD enables joint generation across continuous (images, audio) and discrete (text) modalities in one unified process. The coevolutionary approach lets models reason across different representation types simultaneously rather than processing them separately.
Why It Matters: Generate content where text, images, and audio actually understand each other instead of just coexisting. Links:Paper
GraphSearch: An Agentic Deep Searching Workflow
DataArc's GraphSearch fixes GraphRAG's shallow retrieval problem through six-stage deep searching: decomposition, refinement, grounding, drafting, verification, and expansion. The dual-channel approach queries both text chunks and graph structure simultaneously, beating single-round GraphRAG on all benchmarks.
Comparison of using graph data only, text data only, or all data as commonly adopted in GraphRAG approaches. The metric is SubEM. The contribution of retrieved graph data is marginal.
Why It Matters: Complex multi-hop questions finally get accurate answers from knowledge graphs. Links:Paper | GitHub
Fathom-DeepResearch delivers evidence-based web investigation with two 4B models achieving SOTA among open-weights through DuetQA dataset and RAPO optimization. Links:Paper | GitHub
VLM-Lens provides unified benchmarking for 16 base VLMs and 30+ variants with YAML-configurable extraction from any layer. Links:Twitter | Paper | GitHub
Fast Reconstruction of Yourself creates personalized avatars from random photo collections without controlled capture setups.
Aligning Visual Foundation Encoders to Tokenizers turns pretrained visual encoders into diffusion model tokenizers through three-stage alignment. Links:Project Page | Paper
Tencent DA2: Depth Anything in Any Direction ships the first depth model working in any direction using sphere-aware ViT with 10x more training data. Links:Twitter | Paper | Project Page
Nvidia + MIT LongLive enables real-time interactive long video generation with user control during generation. Links:Paper | GitHub
🛠️ Tools & Techniques
OpenAI Sora 2
Sora 2 ships with rightsholder controls and revenue sharing. Sam Altman says users are generating way more content than expected, so they're building opt-in controls where creators get paid when their characters appear in user-generated content—basically "interactive fan fiction" that pays the original creators.
Why It Matters: Video generation becomes a real business when creators get paid and IP owners have control. Links:Official Release | Sam Altman's Update
Anthropic Claude Sonnet 4.5
Claude Sonnet 4.5 breaks records: 77.2% on SWE-bench, 61.4% on OSWorld, and can code for 30+ hours straight. Ships with checkpoints in Claude Code, VS Code extension, memory tools for longer agent runs, and the Claude Agent SDK powering it all.
Why It Matters: AI agents that can actually complete complex projects without constant babysitting. Links:Official Release
Alibaba Qwen3-VL-30B-A3B-Instruct
Alibaba's Qwen3-VL uses just 3B active parameters to match GPT-5-Mini and Claude4-Sonnet on STEM, VQA, OCR, video, and agent tasks. Available in standard and FP8 versions, plus a massive 235B-A22B variant for maximum capability.
Why It Matters: State-of-the-art multimodal AI that runs on hardware you actually have. Links:Twitter | GitHub | Blog Post | HuggingFace
Tencent HunyuanImage-3.0
HunyuanImage-3.0 improves text-to-image generation across the board: better prompt understanding, higher quality, more consistent styles. Handles complex scenes, detailed characters, and maintains coherence across artistic styles.
Why It Matters: Generate images that actually match what you asked for. Links:HuggingFace | Paper
Ovi: Twin Backbone Cross-Modal Fusion
Ovi generates synchronized audio and video simultaneously using twin backbone architecture. Creates 5-second 720×720 videos at 24 FPS with matched audio, supporting 9:16, 16:9, and 1:1 aspect ratios from text or text+image inputs.
Why It Matters: Audio and video that actually sync instead of just playing at the same time. Links:HuggingFace Model | Paper | Demo Space
Code2Video generates educational videos from code for automated programming tutorials.
Ant Group MingTok releases continuous tokenizers without quantization preserving semantic fidelity, plus Ming-UniVision and Ming-UniAudio for unified processing.
ModernVBERT proves 250M parameters can match 2.5B parameter models. Qwen3-VL delivers GPT-5 performance with 3B active parameters. The pattern is clear: brute force scaling lost.
Here's what actually works: bidirectional attention for retrieval, cross-modal transfer learning, adaptive pruning based on content density. These architectural choices matter more than parameter count. ModernVBERT runs 7x faster on CPU than models it outperforms. That changes everything.
Your phone can now run document retrieval that required a data center last year. Edge devices get semantic search. IoT gains real understanding. The cost of deploying AI just collapsed by 90%. Every startup can now compete with tech giants using commodity hardware.
Storage Costs Kill Deployments (Until Now)
DocPruner cuts storage by 60% with less than 1% performance drop. This solves multimodal AI's dirty secret: storage costs more than compute for production systems. Multi-vector retrieval needs hundreds of embeddings per document. A million documents means billions of vectors. That's terabytes of storage before you even start. DocPruner's adaptive pruning changes the math. Dense pages keep their detail. Sparse pages get aggressively pruned. The system decides automatically.
This makes large-scale deployment actually affordable. Companies can now index entire document libraries without breaking the bank. Real-time multimodal analysis across massive content becomes economically viable. These efficiency gains become particularly valuable in applications like contextual advertising, where real-time multimodal analysis across vast content libraries requires both sophisticated understanding and cost-effective storage solutions to operate at scale.
🧩 Community + Shoutouts
Creator Spotlight: Shoutout to Rory Flynn for the creative Sora 2 Remix → Mario's Escape workflow.
Shoutout to Reddit user Important-Respect-12 for their comprehensive comparison of the 9 leading AI video models, providing valuable insights for the community to understand the current landscape and capabilities across different video generation systems.
That's a wrap on this week's multimodal developments! Small models beating giants. Storage costs collapsing. AI agents working autonomously for days. Commercial models with real business models. The research phase is over.
Ready to build multimodal solutions that actually work? Let's talk.