Multimodal Monday #30: Smarter Agents, Real-Time 3D
Multimodal Monday #30: WALT and UltraCUA make websites API-smart, Seed3D 1.0 builds 3D assets from one image, DeepSeek-OCR compresses docs 10x with 97% accuracy via optical mapping and AGILE lifts VLM accuracy from 9.5% to 82.8% with interactive puzzles.

Week of October 20-26, 2025
📢 Quick Hits (TL;DR)
Web Agents Stop Clicking, Start Understanding - Salesforce and Apple both released frameworks this week that teach agents to reverse-engineer websites into reusable tools. No more brittle click-and-type scripts. These agents now extract the underlying functionality and call it like an API.
3D Generation Picks up Speed - Tencent, ByteDance, Ant Group, and Krea AI all shipped major updates focused on real production use: video-to-3D conversion, multi-shot narratives, and real-time generation on single GPUs.
Learning by Doing Beats Passive Training - New research shows VLMs improve dramatically when they learn interactively. One model jumped from 9.5% to 82.8% accuracy on a task just by solving jigsaw puzzles through trial and error.
🧠 Research Highlights
WALT: Web Agents that Learn Tools
Salesforce built WALT to make browser agents stop clicking around like lost tourists. Instead, agents now reverse-engineer website features into structured APIs through a demonstrate-generate-validate loop, turning messy UI interactions into clean function calls like search(query).

Why It Matters: You get agents that understand what a website does, not just where to click, making automation 10x more reliable.
Links: Paper | GitHub | Announcement
AGILE: Agentic Jigsaw Interaction Learning
Researchers trained a VLM by making it solve jigsaw puzzles through trial and error. The model observes the puzzle, generates code to swap pieces, sees the result, and tries again. This simple interactive loop took accuracy from 9.5% to 82.8% and improved performance on nine other vision tasks by an average of 3.1%.
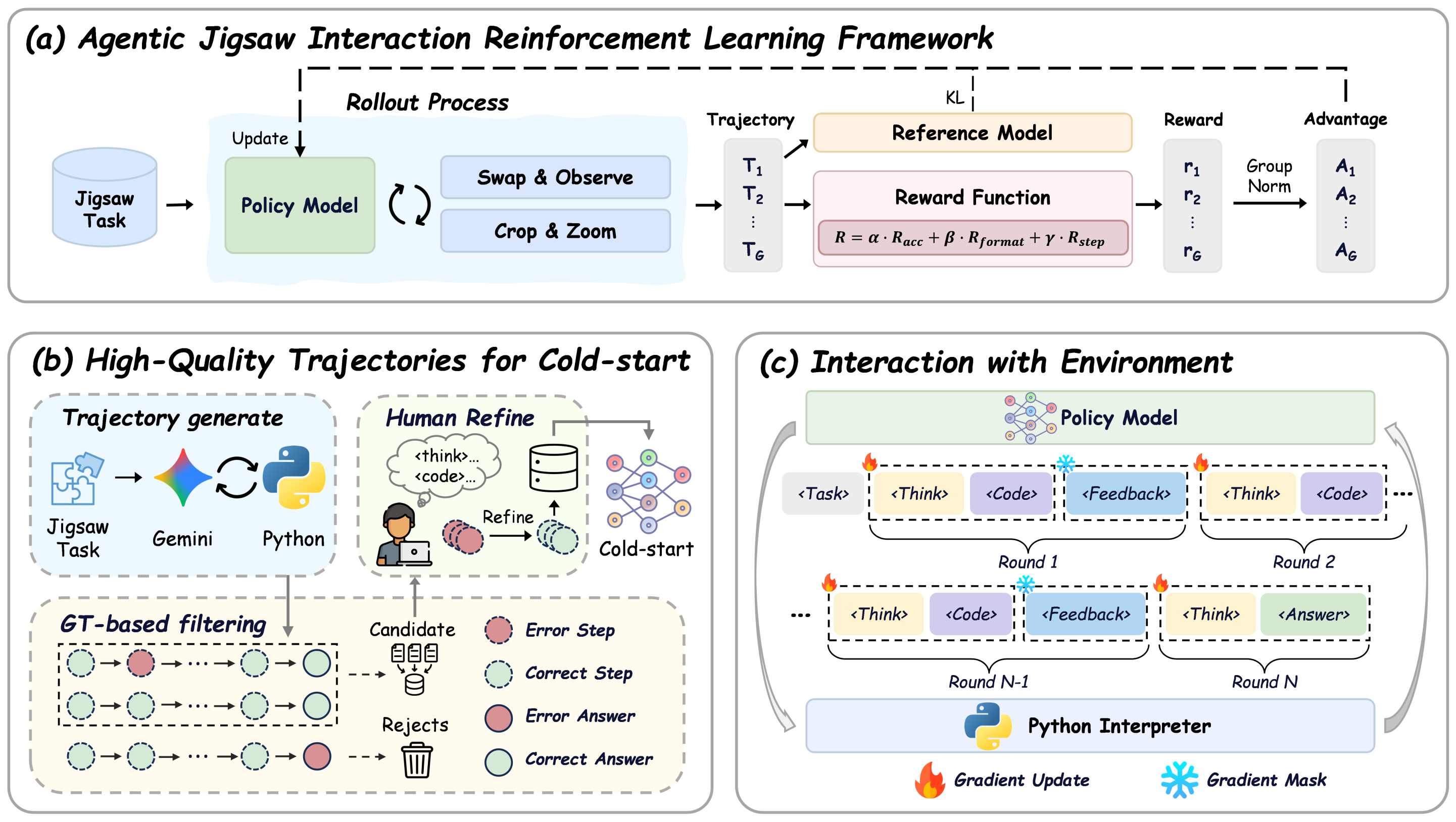
Why It Matters: We can generate unlimited training data by building interactive environments where models learn by doing, not just watching.
Links: Project Page | Paper | GitHub
Sa2VA: Dense Grounded Understanding of Images and Videos
ByteDance combined SAM-2’s segmentation with LLaVA’s vision-language understanding into one unified model. Sa2VA handles both images and videos, producing pixel-precise masks for any object you ask about through conversational prompts.

Why It Matters: You get both high-level understanding and pixel-level precision in one model for video editing, robotics, and visual search applications.
Links: Paper | Hugging Face
UltraCUA: A Foundation Model for Computer Use Agents with Hybrid Action
Apple’s UltraCUA mixes low-level GUI actions with high-level API calls in one model. Train it with supervised learning, then online RL on hybrid action trajectories. The result beats baselines by 22% while running 11% faster.

Why It Matters: Agents now pick the most efficient method for each task, clicking buttons when needed and making API calls when possible.
Links: Paper | Announcement
Grasp Any Region (GAR): Precise Pixel-Level Understanding for MLLMs
GAR lets you ask detailed questions about any specific region of an image. It uses global context plus a region-of-interest replay mechanism to beat a 78B-parameter baseline with a much smaller model, and works zero-shot on video tasks.
Why It Matters: You can now have detailed conversations about specific parts of images for product inspection, medical analysis, or robotics applications.
Links: Paper
Text or Pixels? It Takes Half: A new study investigates the token efficiency of visual text inputs in Multimodal LLMs. Links: Paper | GitHub
Glyph: Scaling Context Windows via Visual-Text Compression introduces a method for scaling context windows. Links: Paper
VISTA: A Test-Time Self-Improving Video Generation Agent from Google presents a new agent for video generation. Links: Paper
Nyx: a new mixed-modal retriever for Universal RAG is a unified retriever tailored for queries and documents containing a mix of text and images. Links: Paper | Collection
Inpaint4Drag repurposes inpainting models for drag-based editing by decomposing the task into pixel-space bidirectional warping and inpainting. Links: Project Page | Paper
MMAO-Bench: MultiModal All-in-One Benchmark for “Omnimodels” proposes a unified evaluation suite for multimodal foundation models that handle text, vision, and audio together. Links: Paper
🛠️ Tools & Techniques
DeepSeek OCR
DeepSeek’s OCR reads text in 100 languages and parses complex structures like charts and tables into HTML. It combines CLIP and SAM features for better grounding and a more efficient performance-to-vision-token ratio.

Why It Matters: The model understands document structure and semantics, not just text, which transforms how you digitize financial reports and scientific papers.
Links: GitHub | Hugging Face | Paper
Tencent Hunyuan World 1.1 (WorldMirror)
Tencent open-sourced WorldMirror, a feed-forward 3D reconstruction model that now handles video-to-3D and multi-view-to-3D. It runs on a single GPU and delivers complete 3D attributes in one forward pass within seconds.
Why It Matters: You can now quickly create digital twins of real objects from video for e-commerce, gaming, and VR applications.
Links: Project Page | GitHub | Hugging Face
ByteDance Seed3D 1.0
ByteDance released Seed3D 1.0, which generates high-fidelity, simulation-ready 3D assets from a single image. The output works directly in physics simulations without additional processing.
Why It Matters: You can rapidly create diverse training environments for autonomous vehicles and robots from simple images.
Links: Paper | Announcement
HoloCine by Ant Group
Generates complete cinematic narratives from text prompts. The model maintains global consistency across multiple shots, creating coherent stories instead of disconnected clips.
Why It Matters: You now get actual narratives with a beginning, middle, and end instead of random video clips.
Links: Paper | Hugging Face
Krea Realtime by Krea AI
Krea AI released a 14B autoregressive model that generates video at 11 fps on a single B200 GPU. It’s 10x larger than any open-source alternative and handles long-form video generation in real time.
Why It Matters: Real-time video generation opens up interactive applications where you generate content on the fly in conversations or games.
Links: Hugging Face | Announcement
OpenAI Atlas AI Browser is a new AI browser from OpenAI. Links: Website
LightOnOCR-1B is a new efficient multimodal OCR model. Links: Hugging Face
Video-As-Prompt from ByteDance provides unified semantic control for video generation, animating images with the style and motion of a reference video. Links: Project Page | Paper
Ctrl-World is a controllable world model that generalizes zero-shot to new environments, cameras, and objects. Links: GitHub
World-in-World is the first open benchmark that ranks world models by closed-loop task success, not pixels. Links: Project Page | GitHub
BADAS 1.0 from Nexar is a new incident prediction model built on real-world data and FAIR’s V-JEPA 2. Links: Website
Embody 3D Dataset from Meta’s Codec Avatars Lab is a large-scale dataset of 3D tracked human motion with audio and text annotations. Links: Project Page | GitHub
BLIP3o-NEXT is a new model with a project page and paper. Links: Project Page | Paper
📈 Trends & Predictions
Web Agents Learn to Think in Functions, Not Pixels
Salesforce and Apple both shipped the same insight this week: stop teaching agents to click buttons and start teaching them to extract functionality. WALT and UltraCUA both move from pixel-level automation to API-level understanding.
Here’s why pixel-clicking fails. You train an agent to navigate a website by clicking specific coordinates or finding specific UI elements. Then the site updates its design. Or it loads slower than expected. Or a popup appears. Your agent breaks. Every edge case becomes a new failure mode. You’re essentially teaching the agent to memorize a choreographed dance routine on a stage that keeps changing. WALT and UltraCUA flip this. Instead of “click the search button at these coordinates,” the agent learns “this website has a search function that takes a query parameter.” The agent demonstrates an action through the UI once, then generates a reusable tool from it. Search becomes search(query). Filtering becomes filter(category, value). The agent now reasons about capabilities, not pixel locations. When the UI changes, the agent adapts because it understands the function, not just the button.
This makes automation fundamentally more robust. You’re no longer fighting with UI variations. The agent doesn’t care if the search button is blue or green, top or bottom, 200 pixels or 250 pixels from the edge. It knows the site can search and it knows how to invoke that capability. The browser becomes an API surface the agent can reason about, not a maze of buttons to navigate.
🧩 Community + Shoutouts
Hugging Face OCR Open Model Breakdown Hugging Face has updated their comprehensive breakdown of open-source OCR models, a great resource for anyone working with document AI. Links: Blog Post
Video Generation Prompting Guide Shout out to Mitch Leeuwe for sharing an excellent resource for upgrading your video generation prompting skills. Links: Post

That’s a wrap for Multimodal Monday #30! From WALT and UltraCUA turning websites into smart APIs, to Seed3D 1.0 and WorldMirror delivering production-ready 3D assets in seconds, to AGILE boosting VLM accuracy through interactive learning, this week highlights multimodal AI’s shift toward practical, real-time solutions for automation, creation, and understanding.
Ready to build multimodal solutions that actually work? Let's talk.