•7 min read
Multimodal Monday #6: Retrieval Refined, Reach Expanded
A weekly pulse on everything multimodal—models, data, tools & community.

Multimodal Monday
📢 Quick Takes (TL;DR)
- Safety First: Meta Bolsters Multimodal Security - Meta released Llama Guard 4, a multimodal safety model to filter text and image inputs/outputs for LLMs/VLMs.
- Pinpoint Understanding: Nvidia's DAM Describes the Details - New Nvidia model generates detailed descriptions for specific image/video regions indicated via points, boxes, scribbles, or masks.
- Omni Goes Lightweight: Qwen2.5-Omni-3B Democratizes Multimodal - Alibaba launched a lightweight 3B Omni model, reducing VRAM needs by 50%+ for long context and enabling audio-video interaction on consumer GPUs.
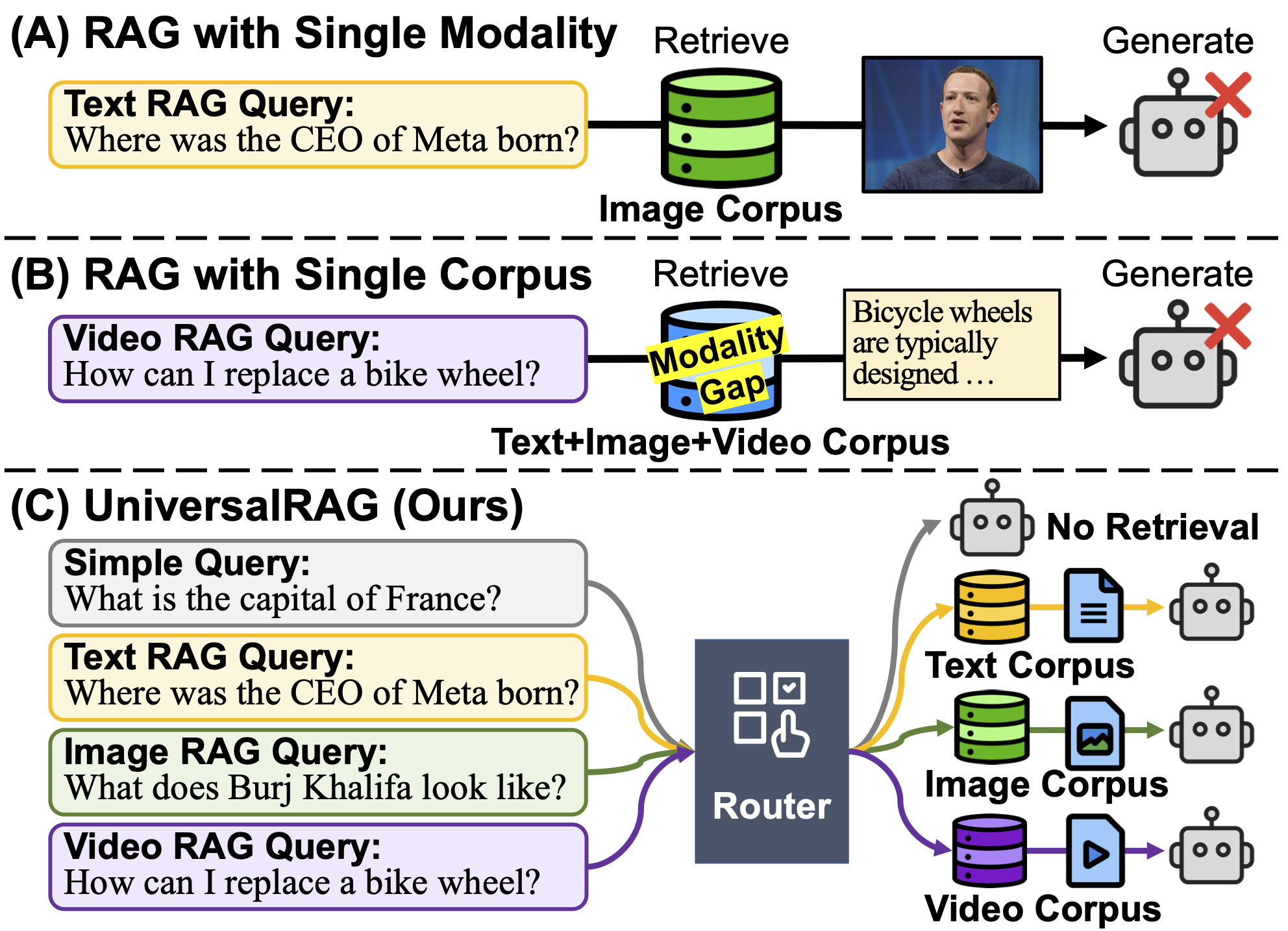
- Beyond Text: UniversalRAG Unifies Multimodal Retrieval - KAIST researchers proposed UniversalRAG, using modality-aware routing to retrieve from diverse sources (text, image, video) at multiple granularities.
🧠 Research Highlights
- UniversalRAG Framework: KAIST researchers propose UniversalRAG, a framework using modality-aware routing to retrieve from heterogeneous sources (text, image, video) at multiple granularities, outperforming single-modality/unified RAG. Why It Matters: This framework directly tackles core challenges in multimodal retrieval by dynamically routing queries to the best modality and granularity, improving the relevance and accuracy of retrieved information from diverse data sources. Project Paper
- YoChameleon Personalized VLM: Researchers introduced YoChameleon, personalizing VLMs (like Chameleon) with 3-5 images of a concept for tailored vision/language generation. Why It Matters: Personalization techniques like this could enable more relevant retrieval and interaction by allowing systems to index and understand user-specific visual concepts from minimal data. Project Paper
- TesserAct 4D Embodied World Models: TesserAct learns 4D embodied world models, predicting dynamic 3D scene evolution from images/text to generate RGB, depth, and normal videos. Why It Matters: Learning 4D world models is crucial for understanding and indexing dynamic scenes over time, enabling retrieval based on temporal events and object interactions within video or simulated environments. Project Paper
- RayZer Self-Supervised 3D Model: RayZer is a self-supervised 3D model trained using only RGB images (no 3D labels/camera info), reportedly outperforming supervised methods. Why It Matters: Self-supervised methods for 3D understanding reduce reliance on labeled data, potentially enabling more scalable indexing and retrieval of 3D assets or environments based on their geometric properties. Tweet Project
- LightEMMA VLM Driving Benchmark: Open framework evaluates VLMs (GPT-4, Gemini) for end-to-end driving, finding practical performance lags scene understanding. Why It Matters: Benchmarking VLMs in complex, dynamic domains like driving highlights the need for robust multimodal understanding and retrieval to interpret and react to real-world visual and textual cues effectively. Paper Code
- MLLM-Bench for Subjective Evaluation: New benchmark evaluates MLLMs using potent models (GPT-4V) as judges with per-sample criteria across six cognitive levels. Why It Matters: Evaluating subjective understanding is key for retrieval systems that need to go beyond factual matching, enabling indexing and searching based on nuanced qualities like sentiment or style. Paper Code
- SIMA Self-Improves LVLM Alignment: Framework uses self-generated responses and in-context self-critique to enhance visual-language alignment in LVLMs without external dependencies or fine-tuning. Why It Matters: Improving visual-language alignment directly enhances the ability of models to accurately connect textual queries with relevant visual data, crucial for effective cross-modal retrieval and indexing. Paper
- Surgical Video Summarization Pipeline: Multimodal pipeline uses visual transformers and LLMs to auto-generate structured reports from surgical videos, improving documentation. Why It Matters: Applying multimodal AI to summarize surgical videos requires effective indexing and retrieval of key events and visual information from complex video data for generating structured reports. Paper

🛠️ Tools & Techniques
- Nvidia Describe Anything Model (DAM): Nvidia released DAM, generating detailed descriptions for specific image/video regions indicated by points, boxes, scribbles, or masks. Why It Matters: DAM allows for generating descriptions tied to specific regions, enabling fine-grained indexing and retrieval of visual content based on localized objects or areas within images and videos. Project Demo
0:00
/3:21
- Meta Llama Guard 4: Meta released Llama Guard 4, a multimodal safety model to filter text and image inputs/outputs for LLMs/VLMs. Why It Matters: Safety filters are essential for deploying multimodal retrieval systems responsibly, ensuring that indexed visual/textual content and generated responses are appropriate and safe. Tweet
- Qwen2.5-Omni-3B Released: Alibaba released a lightweight 3B version of its Omni multimodal model, offering 50%+ less VRAM use and supporting audio-video interactions on consumer GPUs. Why It Matters: More efficient and accessible multimodal models lower the barrier for implementing sophisticated indexing and retrieval systems capable of handling diverse data types like audio and video. Tweet HF
- Microsoft Phi-4-multimodal-instruct: Lightweight open model processes text (24 langs), image (EN), audio (8 langs) with 128k context, strong on speech tasks. Why It Matters: Efficient models capable of processing text, image, and audio facilitate the development of unified systems for indexing and retrieving information across these modalities. Hugging Face
- LightEMMA Framework: Open-source baseline workflow for end-to-end autonomous driving planning, designed for easy integration and evaluation of VLMs. Why It Matters: Frameworks for evaluating VLMs in specific applications help drive progress in areas requiring complex multimodal understanding, which underpins advanced retrieval capabilities in those domains. Code

- Google Cloud Next Demo (Gemini+Imagen+Veo): Google showcased a video creation workflow using Gemini, Imagen, and Veo on Vertex AI at Google Cloud Next. Why It Matters: Integrating models for understanding (Gemini), image generation (Imagen), and video generation (Veo) showcases workflows where retrieval and understanding across modalities fuel creative generation. Tweet
0:00
/1:16
Gemini + Imagen + Veo = Cinematic Magic
🏗️ Real-World Applications
- Yelp Deploys AI Voice Agents: Yelp is rolling out AI-powered voice agents, leveraging the OpenAI API combined with Yelp's extensive business data (including its knowledge graph). These agents are designed to handle customer calls for restaurants and service providers, answering common questions, providing business information, and managing tasks like waitlist additions or booking inquiries. This deployment showcases how multimodal information (structured business data, unstructured reviews, conversational context) can be retrieved and synthesized in real-time to create more efficient and informative customer service interactions, reducing wait times and freeing up staff.
Why It Matters: This practical application highlights the value of combining large language models with domain-specific knowledge graphs for retrieval. It demonstrates how multimodal indexing (linking conversational context to structured business data) enables sophisticated, real-world AI agents capable of understanding and responding to complex user needs in specific verticals like local services. Article - Hikvision Guanlan AI Models Power AIoT: Hikvision, a major provider of video surveillance products, announced the deployment of its large multimodal Guanlan AI models within its AIoT (Artificial Intelligence of Things) product lines, including Network Video Recorders (NVRs) and cameras. This integration aims to enhance video analysis capabilities directly on the edge devices, enabling features like natural language search across video footage and more sophisticated event detection. The models are designed to understand complex scenes and relationships within video data.
Why It Matters: Embedding large multimodal models directly into edge devices like cameras and NVRs signifies a major step towards real-time, on-device multimodal indexing and analysis. This approach is crucial for applications requiring low latency and data privacy, such as security and industrial monitoring, enabling efficient search and retrieval of events directly from sensor data streams without constant cloud dependency. Announcement
📈 Trends & Predictions
- Advanced Multimodal RAG is Key for Contextual Understanding: Even as context windows expand, the need for sophisticated Retrieval-Augmented Generation (RAG) across diverse data types is becoming more apparent. This week highlighted frameworks like UniversalRAG, which directly addresses challenges in retrieving information from heterogeneous sources (text, image, video) by using modality-aware routing and handling multiple granularities. Simultaneously, advancements in embedding models like LightOn's GTE-ModernColBERT aim to improve the core semantic understanding needed for accurate retrieval. The trend suggests a move towards smarter retrieval systems that can intelligently select, process, and synthesize information from the most relevant modality and source, rather than relying solely on massive context dumps. For multimodal indexing, this means developing representations that capture cross-modal relationships effectively.
- Granularity and Personalization Drive Deeper Indexing: The field is pushing beyond generic, whole-asset understanding towards more nuanced, localized, and personalized indexing. Nvidia's Describe Anything Model (DAM) exemplifies this by generating detailed text descriptions for user-specified regions within images and videos, enabling indexing and retrieval based on specific objects or areas of interest. Similarly, research like YoChameleon explores personalizing models with minimal user data, paving the way for indexing systems that understand and retrieve content relevant to specific user concepts or subjects. This focus on granularity and personalization is crucial for unlocking value in large, unstructured multimodal datasets, allowing users to find precisely what they need.
- Accessible Foundations & Open Ecosystems Lower Barriers: The proliferation of efficient, open-weight multimodal models like Alibaba's Qwen2.5-Omni-3B and Microsoft's Phi-4-multimodal, alongside community curation efforts (e.g., InternVL3 collections on Hugging Face) and tools (Unsloth notebooks for synthetic data), is significantly lowering the barrier to entry for building sophisticated multimodal systems. This democratization extends to foundational capabilities like Automatic Speech Recognition (ASR), with releases like Nvidia's Parakeet TDT. This trend empowers developers and organizations outside large tech companies to build custom, domain-specific multimodal indexing and retrieval solutions, accelerating innovation and tailoring applications to specific use cases.
🧩 Community + Shoutouts
- TTS Arena V2 Launched: A new version of TTS Arena is available for blind A/B voting on text-to-speech models (open & closed), featuring a conversational arena and personal leaderboards. Benchmarking tools like TTS Arena help assess the quality of speech synthesis, which is relevant for applications involving retrieving information and presenting it via voice. Announcment
- Unsloth+Meta Synthetic Data Notebook: A Colab notebook demonstrates using Unsloth and Meta's synthetic-data-kit to generate question-answer pairs locally from documents for fine-tuning Llama 3.2 3B. Generating synthetic data can augment training sets for retrieval models, potentially improving their ability to index and understand specific types of documents or visual information. Notebook
- InternVL3 HF Collection: Merve from HuggingFace is back at it with a curated collection of InternVL3 models, providing easy access for the community to explore these vision LMs. Community efforts in organizing models like InternVL3 make powerful vision-language capabilities, essential for multimodal indexing and retrieval, more accessible to developers. HF Collection
- IEEE GRSS Data Fusion Contest: Newly announced global competition invites participants to leverage multimodal Earth observation data for environmental challenges like air quality and climate monitoring. Sponsored by IEEE’s Geoscience and Remote Sensing Society, it offers a platform for researchers to apply vision-language models (VLMs) to real-world geospatial problems. Learn more
Mixpeek helps teams drop any of the above models (segmentation, video gen, color analysis) into production by wiring feature extractors and retrieval pipelines—so next week’s breakthroughs plug‑in, not rewrite.