Video Learning Hub
Master multimodal AI concepts through comprehensive tutorials, guides, and best practices from our expert team.
Trusted by engineers at

Done watching? Point Mixpeek at your own video, image, audio, and document storage and make it searchable: free.
Search your own data
Quantisation Scrambles What Is Near What
Generative recommendation turns items into discrete tokens so a model can generate the next item the way a language model generates the next word, and making those tokens means quantising each item embedding into a short code. In the pretrained embedding space similar items sit near each other, and that adjacency is the signal; after quantisation the intrinsic structure is disrupted, so the model's perception of item similarity is distorted before training begins. TopoTok (RecSys 2026) measures that distortion and repairs it with multi level distillation, coarse to fine: inter group for global cluster relations, intra group for local structure, inter item for fine grained alignment, reporting up to 9.42% better Recall@5. One distinction matters: this is not index-time vector compression, where you rescore the shortlist at full precision to recover accuracy. Here the structure is gone before the model trains, so there is nothing to rescore. Paper: arxiv.org/abs/2607.18600
Your Embedding Is a Point. It Should Be a Cloud.
Every retrieval system treats an embedding as a point: one vector, one location, one distance to the query. That assumption hides something, because content is not equally specific. A five second clip of someone walking is unambiguous; a two minute clip of a wedding is many things at once. Both collapse to a single point, and the system ends up exactly as confident about each. The Distribution-Alignment Bridge (Chae, Lee, Ahn, ECCV 2026) models text and video embeddings as Gaussians defined by a mean and a variance, so a vague caption becomes a wide distribution and a precise one becomes tight. Matching becomes distribution alignment rather than point distance, trained with a KL based distribution aware contrastive loss and a deterministic diffusion style bridge that refines the text distribution toward the video distribution over a truncated number of steps, evaluated on MSR-VTT, MSVD and VATEX. The payoff is calibrated uncertainty in the ranking. Paper: arxiv.org/abs/2607.20984
PLAID-PRF: Query Expansion That Reuses What Your Index Already Stores
Pseudo relevance feedback has been known since the 1970s: run the search, assume the top results are roughly right, pull useful terms out of them, and search again with a better query. It reliably improves ranking, and almost nobody runs it on modern multi-vector retrieval because the second pass costs more than the first. ColBERT keeps one vector per token and scores every query token against every document token, and PLAID makes that affordable by quantising each token vector to its nearest centroid so the index stores centroid identifiers rather than full vectors. PLAID-PRF (Wang, MacAvaney, Macdonald, SIGIR 2026) notices those centroids are already in the index and behave like tokens, so feedback can run on them directly: select a small diverse high utility set and append it to the query, for up to 4.3% better nDCG at 10 without query time clustering. Paper: arxiv.org/abs/2607.18626

Your Agent Can Read Everything. It Cannot Watch Anything.
A short vision piece on the asymmetry at the centre of enterprise data. An AI agent can read every document you own and cannot watch a single one of your videos. The meeting where the decision got made, the demo that closed the deal, the incident review, the customer interview: recorded, stored, and effectively not retrievable by what is inside them. Text got a fifty year head start, since the relational model dates to 1970 and full text retrieval is about as old, so querying structured text is a solved problem with mature tooling at every layer. Everything else piled up unindexed. Mixpeek indexes video, images, audio and documents together, decomposing objects into features so a retriever can reach inside them, which is how agents get eyes and ears through one API. Explore: mixpeek.com/glossary/multimodal-data-warehouse
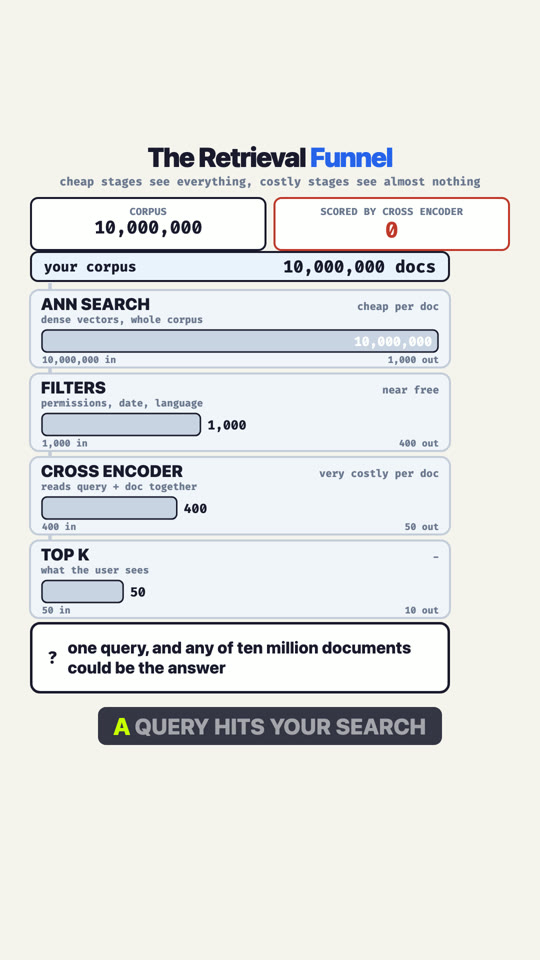
The Retrieval Funnel: Why Your Reranker Sees 400 of 10 Million
Ten million documents could answer one query, and the model best qualified to judge them, a cross encoder that reads query and document together, is the one you can least afford to run across a corpus. That single constraint is why production retrieval is a ladder rather than a model. ANN search over embeddings goes first because it is cheap per document, so it runs against everything and returns a shortlist. Filters cut further, and the order matters: filtering after scoring and filtering before scoring are different operations with different recall. Only then does the cross encoder run, affordable precisely because it inherits a shortlist. Cheap stages absorb the volume, costly stages inherit a shortlist. Full breakdown: mixpeek.com/glossary/multi-stage-retrieval-pipeline

HNSW: How Vector Search Skips 10 Million Comparisons
Ten million vectors sit in an index and a query arrives. Comparing against every one is exact and unusable, so vector databases run HNSW instead. This video is a live simulation of the algorithm: build a proximity graph, walk it greedily toward the query, then watch why a single flat graph makes that walk cross the entire space. HNSW stacks the graph into layers, so a thin top layer with long links covers enormous ground in a couple of hops and the best node found becomes the entry point one level down. Coarse to fine, logarithmic rather than linear. It is approximate, and widening the candidate list raises recall and latency together, which is the real operating decision. Full breakdown: mixpeek.com/guides/approximate-nearest-neighbor-algorithms
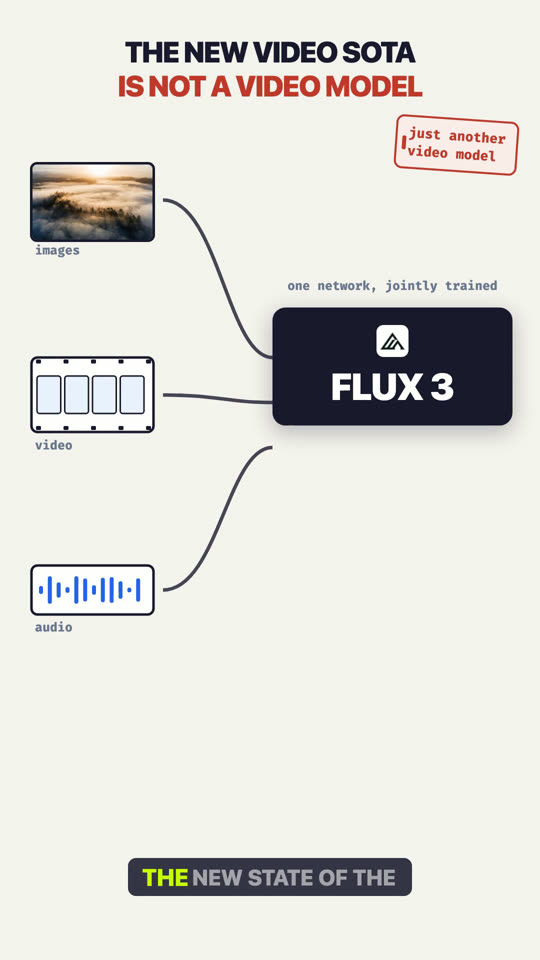
FLUX 3: Generation Unified. Storage Didn't.
Black Forest Labs' FLUX 3 is one network that jointly learns images, video, and audio: 20 second clips with sound in a single pass, preference wins over Runway Gen-4.5 (77%) and Luma Ray 3.2 (93%), and the same backbone powers FLUX-mimic, a video-action model for robots built with mimic robotics. This video walks the announcement, then the downstream gap: generation collapsed into one architecture while most storage stacks still split video, audio, and images into three systems that cannot search each other. Mixpeek is the warehouse side of that pipe: every modality indexed together, so generated media stays findable. Announcement: bfl.ai/blog/flux-3
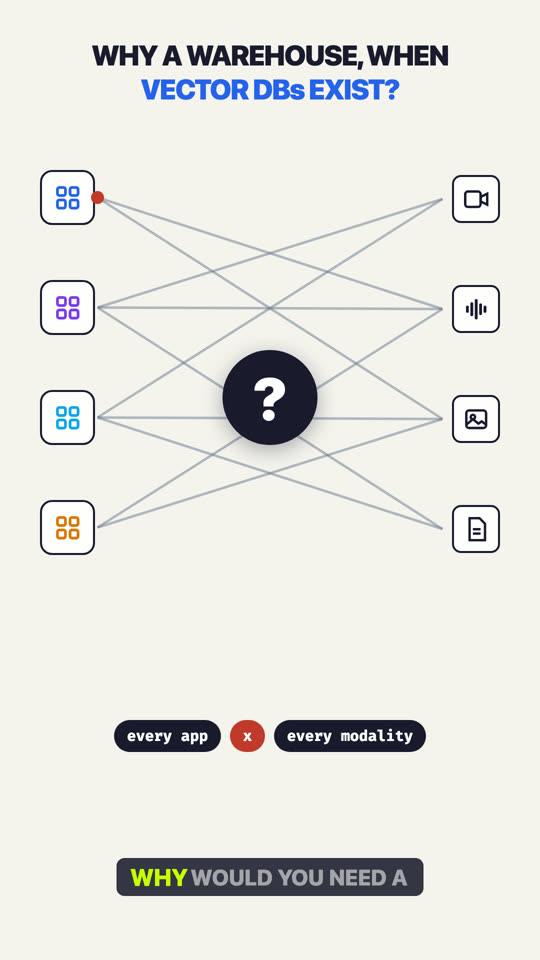
Why a Multimodal Warehouse When Vector DBs Already Exist?
One app searching one modality is easy: embed, store, done. But every app needs every modality, so teams rebuild the same chunk-extract-embed-index pipeline until 5 apps x 4 modalities is 20 pipelines processing the same footage, with every copy drifting out of sync. The gap: a vector database stores vectors, while extraction (how raw video becomes vectors) is the expensive part everyone duplicates. A multimodal data warehouse extracts once, upstream of every app: scenes, transcripts, faces, OCR, and embeddings become queryable timestamped features, indexes build from them, and retrievers compose search, filter, and rerank on top, so a new app is a query, not a pipeline. Explore: mixpeek.com/comparisons/multimodal-data-warehouse-vs-vector-database

Introducing Claude for S3 (Point It at a Bucket, Walk Away)
A launch-card parody with a true story underneath: point Claude at an S3 bucket and it infers what you are storing (12,000 videos, 3,000 podcasts, 9,000 PDFs), infers the queries you will ask before you ask them, then constructs the collections, feature extractors, vector indexes, and retriever pipelines itself. When you finally type 'find the clip where the CEO says the Q3 number,' it was already indexed. Claude belongs to Anthropic; the S3 part is Mixpeek: bucket ingestion, multimodal extraction, and 43 MCP tools that let Claude drive the warehouse. Explore: mixpeek.com/guides/vector-database-on-s3-object-storage