Why the future of AI isn’t about bigger models — it’s about better data.
Industry
“Everyone wants to talk about the model. No one wants to talk about the dataset.” – Basically every ML engineer ever
It’s no secret that AI is booming. New models are dropping every month, some with trillions of parameters, billions of tokens, and wild capabilities. But here’s the part you don’t hear as often:
Most of the heavy lifting in AI happens before (and after) the model is trained.
The unsung hero behind every AI breakthrough? 🧠 The Dataset Engineer.
Let’s unpack why.
🛠️ What Even Is Dataset Engineering?
Dataset engineering is everything that happens to data before it gets fed into a model — and everything that happens after to keep the model useful.
It includes:
Collecting raw data (text, video, audio, images)
Cleaning, filtering, labeling
Deduplicating redundant samples
Segmenting and structuring it
Monitoring model failures to generate new training data
It’s not just janitorial work. It’s data strategy — and it makes or breaks the model.
🔍 Think: less “clean this data” and more “what data is worth learning from?”
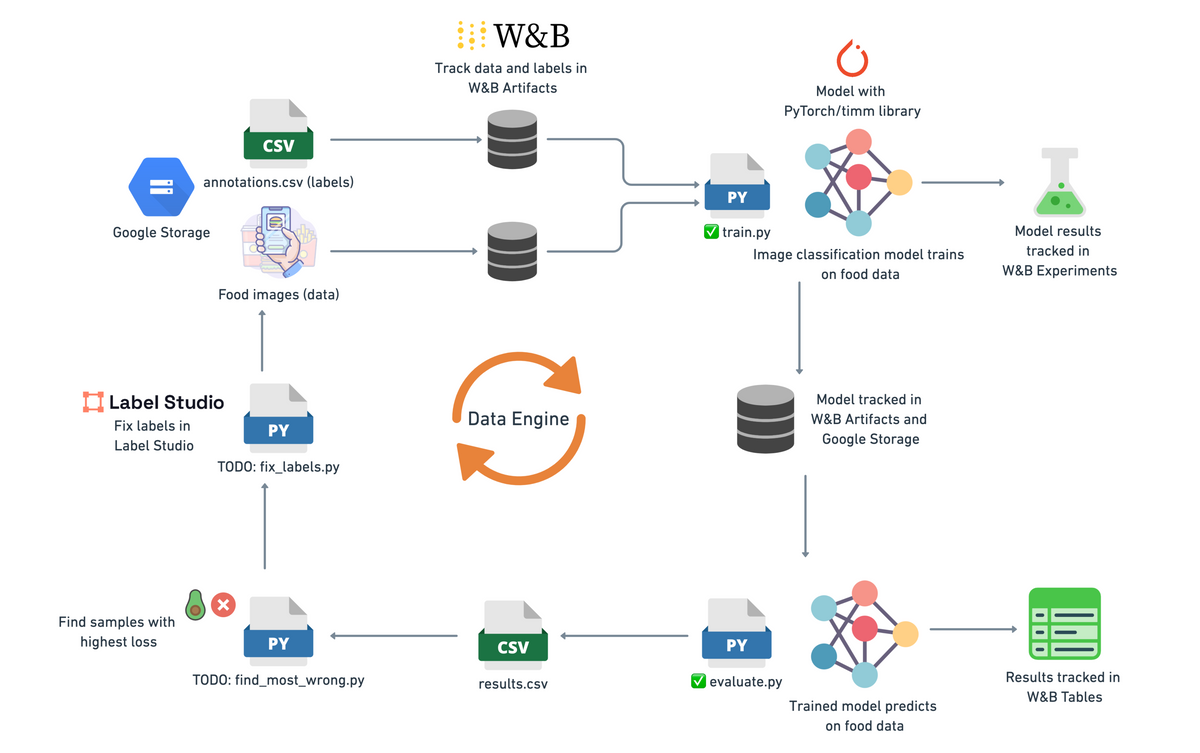
🎬 Case Study: Cosmos and the 20M-Hour Video Diet
NVIDIA recently trained a massive AI called Cosmos to understand physics… by watching 20 million hours of video. But here’s the kicker: they didn’t just dump all that raw footage into the model.
Tesla’s Autopilot team runs a “data engine” — it spots model failures on real roads, searches the fleet for more of those cases, labels them, and retrains.
Car confused by a bike on a rack? → Find 500 more of those, label them, retrain.
Weird new intersection? → Add it to the dataset, improve behavior.
This feedback loop is powered by world-class dataset engineering.
It’s easy to get caught up in model size — GPT-3, Gemini, Claude… we’re talking billions of parameters. But in reality?
📈 Better data often beats bigger models.
Here’s why:
Data defines what the model can learn
Diverse and well-curated samples reduce bias
Cleaner datasets reduce hallucinations and failures
💡 Fun fact: OpenAI filtered and deduped massive parts of the web before training GPT-3. They even weighted better sources like Wikipedia more heavily. Smart.
🧰 So… Do I Need a Whole Data Team?
If you’re Google or Tesla? Probably. But if you’re a growing company building AI-powered features, dataset engineering still matters — and you don’t need a 20-person team to pull it off.
✅ Ingest your videos, images, audio, text ✅ Extract rich features (objects, faces, speech, etc.) ✅ Filter, dedupe, and structure your data ✅ Deliver it as an indexed, searchable, clean dataset ✅ Continuously monitor for new data signals or failures
You tell us what insights or features you want, and we build the data engine around it.
🧪 Example: Want to search “customers interacting with shelves” in your store footage? Mixpeek can slice, filter, and index that behavior for you.
→ You focus on building. We handle the messy stuff.
🎯 TL;DR – Don’t Just Train Models. Train on the Right Data.
The next wave of AI innovation isn’t about who has the flashiest model. It’s about who feeds their models the best-curated, highest-signal data.
Dataset engineers are quietly becoming the most valuable players in AI — and the smartest teams are the ones investing in them (or working with partners who do).