Multimodal Monday #14: Dynamic Fusion, Contextual Evolution
Multimodal Monday #14: FlashDepth streams 2K depth, Vision-guided chunking redefines docs, Antares AI-GO secures pharma, and WAP aids robots. A new standard emerges.

📢 Quick Take (TL;DR)
Netflix just deployed AI that sees depth in real-time - FlashDepth processes 2K video at 24 FPS and is already creating visual effects on actual movie sets, proving multimodal AI is ready for Hollywood's demanding standards.
Your PDFs finally make sense to AI - Vision-guided chunking lets AI understand documents the way humans do - seeing how text, images, and tables relate to each other, making that 500-page technical manual actually searchable.
Pharma factories now trust AI eyes - Antares Vision's AI-GO platform inspects pills and vials in pharmaceutical plants where a single defect could be catastrophic, marking multimodal AI's leap from demos to life-critical applications.
🧠 Research Highlights
World-Aware Planning Narrative Enhancement (WAP)
WAP gives vision-language models the ability to understand environments like humans do - recognizing not just objects but their spatial relationships and functions. The framework combines visual modeling with spatial reasoning to enable robots and AI agents to plan complex tasks in real-world settings.
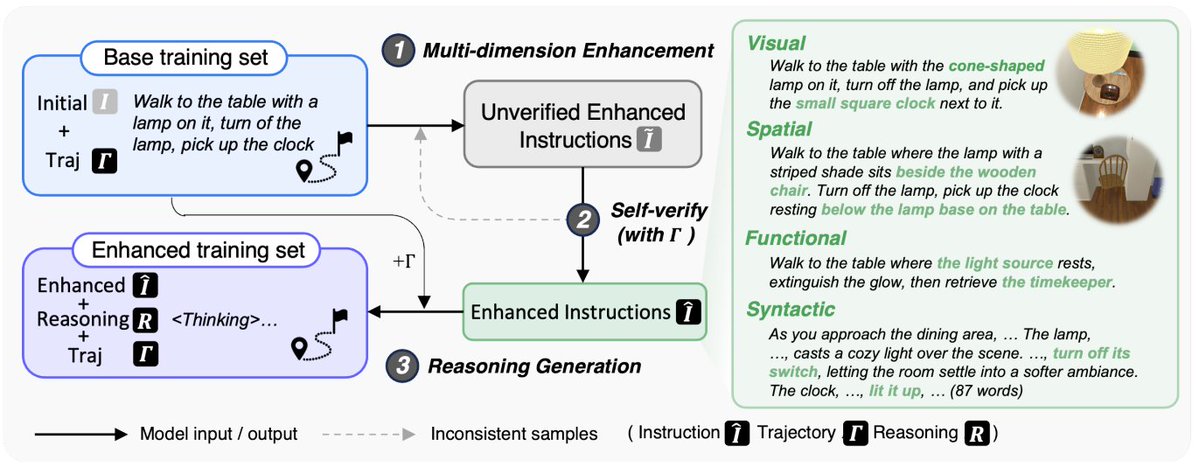
Why It Matters: Finally, AI can understand that a coffee mug on a high shelf requires finding a step stool first - crucial for robotics and smart home applications.
Links: Announcement
Vision-Guided Chunking Is All You Need: Enhancing RAG with Multimodal Document Understanding
This breakthrough uses Large Multimodal Models to intelligently split PDFs by understanding visual context - preserving tables that span pages and maintaining relationships between diagrams and their descriptions. The system processes documents in batches while keeping semantic connections intact.

Why It Matters: No more search results that return half a table or diagrams without their explanations - documents finally stay coherent in AI systems.
Links: Paper
FlashDepth: Real-time Streaming Video Depth Estimation at 2K Resolution
FlashDepth achieves cinema-quality depth estimation at 2K resolution running 24 FPS, capturing fine details like individual hairs while maintaining smooth frame-to-frame consistency. Netflix already uses it on movie sets for live visual effects previews.
Why It Matters: Real-time 3D understanding of video enables instant special effects, better AR/VR, and video search based on spatial relationships.
Links: Announcement | Project Page | GitHub
MMSearch-R1: Incentivizing LMMs to Search
ByteDance's reinforcement learning framework teaches AI when to search versus when to use existing knowledge, reducing unnecessary searches by 30% while improving accuracy. The system learns to balance search costs against information quality through outcome-based rewards.

Why It Matters: AI that knows when it doesn't know something saves computing costs and delivers faster, more relevant results.
Links: Paper
Unlocking Rich Genetic Insights Through Multimodal AI with M-REGLE
Google's M-REGLE combines multiple biological data types - gene sequences, protein structures, and clinical data - to unlock patterns invisible when analyzing each separately. The framework demonstrates multimodal AI's power beyond traditional vision-language tasks.
Why It Matters: Multimodal AI isn't just for images and text anymore - it's accelerating scientific discovery by connecting diverse data types.
Links: Blog
Diffusion Tree Sampling (DTS)
Advanced technique for steering diffusion models at inference time, enabling more controlled generation and improved quality in multimodal content creation.
Links: Announcement
OmniGen 2
Next-generation unified multimodal generation model with enhanced capabilities for cross-modal content creation and understanding.
Links: Project Page | Demo
Multimodal Anomaly Detection with a Mixture-of-Experts
Novel approach using mixture-of-experts architecture for detecting anomalies across multiple modalities, improving robustness and accuracy in anomaly detection tasks.
Links: Paper
SiM3D: Single-instance Multiview Multimodal and Multisetup 3D Anomaly Detection Benchmark
Comprehensive benchmark for integrating multiview and multimodal data for 3D anomaly detection, particularly crucial for manufacturing applications and quality control.
Links: Paper
ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Advances audio-visual integration for generating and editing soundscapes using multimodal LLMs with chain-of-thought reasoning capabilities.

Links: Paper
Baidu: Towards AI Search Paradigm
Research exploring new paradigms for AI-powered search systems, focusing on improving search effectiveness and user experience through advanced AI techniques.

Links: Paper
🛠️ Tools & Techniques
Moondream 2B Release with Visual Reasoning
Moondream packs powerful visual reasoning into just 2 billion parameters - small enough for phones yet smart enough for complex visual tasks. The model proves that advanced multimodal AI doesn't require massive computing resources.
Why It Matters: Finally, sophisticated visual AI that runs on your device instead of the cloud, enabling privacy-preserving applications everywhere.
Links: Announcement | Model
Alibaba Qwen-VLo Release
Alibaba's Qwen-VLo extends their model family with production-ready vision-language capabilities optimized for enterprise scale. The model balances strong multimodal understanding with the efficiency needed for real-world deployment.
Why It Matters: Major tech companies are racing to make multimodal AI practical for business - this release shows the technology is ready for prime time.
Links: Announcement | Model
ShareGPT-4o-Image: Aligning Multimodal Models with GPT-4o-Level Image Generation
ShareGPT-4o-Image achieves GPT-4o-level image generation while maintaining strong understanding capabilities through advanced alignment techniques. The Janus-4o-7B model demonstrates that understanding and generation can excel together.

Why It Matters: AI that both understands and creates images opens doors for interactive creative tools and better visual search results.
Links: Paper | Model
NVIDIA Cosmos-Predict2: World Foundation Model for Physical AI
NVIDIA open-sources Cosmos-Predict2, enabling AI to understand and predict how objects move and interact in the physical world. The model provides the foundation for robots and autonomous systems to navigate complex environments.
Why It Matters: Open-source physics understanding democratizes advanced robotics - your robot vacuum might soon navigate like a human.
Links: Announcement | GitHub
Google Gemma 3n Release
Google releases Gemma 3n, the latest iteration in the Gemma model family with enhanced capabilities and improved performance across various tasks.
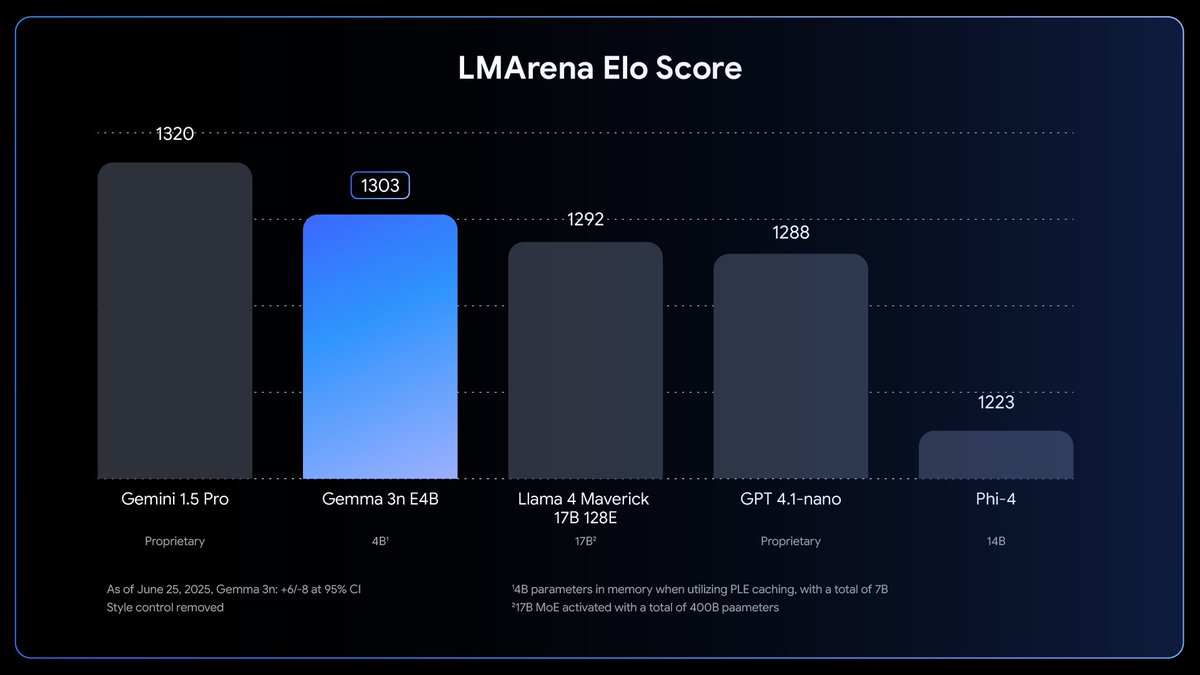
Links: Announcement | Developer Guide
Flux Kontext Released with Open Weights
Black Forest Labs releases Flux Kontext with open weights, providing the community with access to advanced generative capabilities for research and development.

Links: Announcement
jina-embeddings-v4 Release
Jina AI releases jina-embeddings-v4, a unified embedding model that combines capabilities from jina-embeddings-v3, jina-clip-v2, jina-colbert-v2, colpali, and dse into a comprehensive embedding solution.

Links: Announcement | Model
Google Gemini Robotics On-Device
Google introduces Gemini Robotics On-Device, bringing AI capabilities directly to local robotic devices for improved responsiveness and reduced latency in robotics applications.
Links: Blog
🏗️ Real-World Applications
Antares Vision & Oròbix Launch AI-GO Visual Inspection Platform
Italian pharmaceutical equipment leader Antares Vision deployed AI-GO to inspect pills and vials on production lines where defects could endanger lives. The platform uses multimodal AI to spot microscopic flaws and ensure every medication meets strict safety standards. When AI can be trusted with pharmaceutical quality control, it's ready for any industry's critical operations.
Links: Article
eHealth Deploys AI Voice Agents for Insurance Customer Service
eHealth's AI voice agents now help Medicare customers navigate complex insurance options through natural conversation. The system understands both spoken questions and visual plan comparisons to guide seniors through enrollment decisions. AI handling sensitive healthcare decisions shows multimodal technology has earned consumer trust in high-stakes scenarios.
Links: Article
📈 Trends & Predictions
Real-Time Multimodal Processing Reaches Production Maturity
Netflix's adoption of FlashDepth for live visual effects proves what seemed impossible just months ago - AI can now process high-resolution video in real-time with Hollywood-level quality. This isn't a research demo; it's actively creating movie magic on set.
The implications ripple far beyond entertainment. Live sports broadcasts will overlay real-time 3D graphics that understand player positions and ball trajectories. Security systems will instantly recognize complex scenarios involving multiple people and objects. Video calls will feel three-dimensional as AI understands spatial relationships in real-time.
Most importantly, the 24 FPS barrier has been broken. Once AI can keep up with video frame rates, entirely new categories of applications emerge. Expect to see real-time multimodal AI everywhere from surgical assistance to autonomous vehicle navigation within the next 18 months.
Document Understanding Becomes Truly Multimodal
For decades, we've forced computers to read documents like primitive text scanners - ignoring the rich visual context that makes documents understandable to humans. Vision-guided chunking changes everything by teaching AI to see documents the way we do.
Consider a technical manual where a diagram spans two pages with annotations scattered around it. Traditional systems would split this into meaningless fragments. The new approach keeps related content together, understanding that the diagram, its labels, and the explanatory text form a single concept.
This breakthrough will trigger a massive wave of document reprocessing across enterprises. Companies will race to re-index their knowledge bases with multimodal understanding, finally making decades of accumulated documentation truly searchable. The vendors who can efficiently process millions of legacy documents will capture enormous value in this transition.
That's a wrap for Multimodal Monday #14! From Hollywood sets to pharmaceutical plants, multimodal AI has crossed the chasm from research to revenue. The convergence of real-time processing, intelligent document understanding, and industry-specific deployments signals that we're entering the deployment decade of multimodal AI.
Ready to build multimodal solutions that actually work? Let's talk