Multimodal Monday #19: Chinese AI Surge, Open Source Wins
Multimodal Monday #19: Wan 2.2 rolls out with a week of daily feature releases, HairCUP refines 3D avatars, and E-FineR boosts recognition. Open Source Chinese AI surges ahead!

📢 Quick Take (TL;DR)
Chinese AI labs dominate the week - While the West debates safety, China ships at breakneck speed: Alibaba's Wan 2.2 drops daily features like it's a software startup, StepFun unleashes a 321B parameter open-source giant, and DeepSeek's Janus-Pro hits vision benchmarks that make GPT-4V sweat. The pace is unprecedented.
VLMs are surprisingly fragile - New research exposes an uncomfortable truth: GPT-4o, Claude-3.5-Sonnet, and Gemini-1.5-Flash all stumble when you phrase questions slightly oddly. Turns out our multimodal AIs are great at benchmarks but terrible at handling real humans who don't speak in perfect prompts.
Composability is eating holistic AI - Meta's HairCUP lets you swap hairstyles between 3D avatars like LEGO pieces, while E-FineR ditches predefined categories entirely. The future isn't one giant model doing everything—it's modular systems you can mix, match, and extend without retraining.
🧠 Research Highlights
Analyzing the Sensitivity of Vision Language Models in Visual Question Answering
Researchers tested whether VLMs can handle conversational quirks by adding modifiers to questions from VQA v2.0. All three tested models (GPT-4o, Claude-3.5-Sonnet, Gemini-1.5-Flash) showed consistent performance drops when questions violated Grice's conversational maxims—basically, they fail when humans don't ask "perfect" questions.

Why It Matters: This reveals that production VLMs might fail on real user queries that don't match their training distribution, making reliable deployment harder than benchmarks suggest.
Links: Paper
HairCUP: Hair Compositional Universal Prior for 3D Gaussian Avatars
Meta's HairCUP treats hair and face as separate entities in 3D avatars, learning distinct latent spaces for each component. The system can seamlessly transfer hairstyles between different avatars while preserving identity, enabled by a synthetic pipeline that removes hair from captured data.
Why It Matters: Compositional approaches like this enable content systems to index and search visual elements independently, moving beyond treating images as monolithic blobs.
Links: Project Page | Paper
Vocabulary-free Fine-grained Visual Recognition via Enriched Contextually Grounded VLM
E-FineR eliminates the need for predefined class vocabularies in visual recognition, combining LLMs with VLMs for open-set recognition. The training-free method achieves SOTA results while supporting zero-shot and few-shot classification without human intervention.

Why It Matters: This solves the critical limitation of current systems that break when encountering new categories, enabling truly adaptive content analysis pipelines.
Links: Paper
Application of Vision-Language Model to Pedestrians Behavior and Scene Understanding in Autonomous Driving
This work distills knowledge from large VLMs into efficient vision networks for autonomous driving, focusing on pedestrian behavior prediction. The method uses ensemble techniques to boost performance in open-vocabulary perception and trajectory prediction tasks.

Why It Matters: Knowledge distillation makes sophisticated multimodal understanding feasible for real-time applications where computational efficiency is critical.
Links: Paper
🛠️ Tools & Techniques
Wan 2.2 Released with Daily Feature Rollouts
Alibaba shocked the AI world by shipping new Wan 2.2 features every single day for a week: dynamic lighting (Day 1), shot types (Day 2), cinematic angles (Day 3), camera movements (Day 4), composition controls (Day 5), and subject movement (Day 6). The 27B parameter model (14B active) runs on consumer GPUs and produces cinematic-quality video with fine-grained control.
Why It Matters: This daily release cadence sets a new standard for AI development speed and shows how quickly controllable video generation is becoming accessible to everyone.
Links: Wan Video | Announcement
Black Forest Lab FLUX.1-Krea-[dev]
Black Forest Lab releases FLUX.1-Krea-[dev], their latest developer-focused image generation model with enhanced capabilities for creative applications and research integration.
Why It Matters: Developer editions enable researchers to experiment with cutting-edge generation techniques that inform better content indexing approaches.
Links: Announcement | Black Forest Lab
Google DeepMind AlphaEarth Foundations
Google DeepMind launches AlphaEarth Foundations, a comprehensive foundation model for earth science that integrates multimodal data for environmental monitoring and climate research.
Why It Matters: Domain-specific foundation models show how general multimodal capabilities can be specialized for scientific applications requiring deep expertise.
Links: Announcement | Google DeepMind
Cohere Command-A-Vision-07-2025: 112B Dense VLM for 6 Languages
Cohere's new 112B dense (non-MoE) vision-language model supports 6 languages, targeting enterprise multimodal applications. The dense architecture ensures consistent performance across all parameters without the routing complexities of mixture-of-experts models.
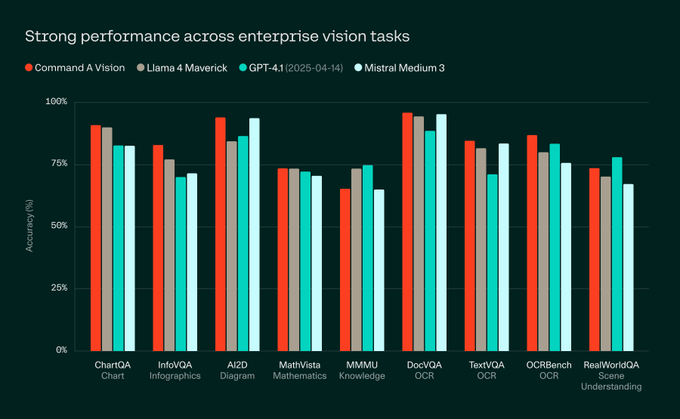
Why It Matters: Multilingual VLMs with dense architectures provide reliable performance for global content analysis without the unpredictability of sparse models.
Links: Announcement | Cohere
StepFun-AI Step3: Open Source 321B MoE VLM
StepFun-AI open-sources Step3, a massive 321B parameter Mixture of Experts VLM, joining DeepSeek's Janus-Pro in the Chinese open-source multimodal revolution. The model matches or beats proprietary alternatives on multiple benchmarks while remaining fully open.
Why It Matters: Open-source models at this scale democratize advanced multimodal AI, letting any organization build sophisticated content understanding systems.
Links: Announcement | StepFun AI
Skywork UniPic-1.5B: Any-to-Any Multimodal Model
Skywork's UniPic-1.5B handles image+text → image+text generation in just 1.5B parameters, proving that effective multimodal capabilities don't always require massive scale.
Why It Matters: Compact any-to-any models enable multimodal processing on edge devices and resource-constrained environments.
Links: HuggingFace | Skywork
OWL Eval: Open-Source Human Evaluation Platform
Wayfarer Labs open-sources OWL Eval, a standardized platform for human evaluation of video and world models, addressing the lack of consistent evaluation frameworks in multimodal AI.
Why It Matters: Standardized evaluation tools help the community measure real progress beyond cherry-picked demos.
Links: Announcement | Wayfarer Labs
📈 Trends & Predictions
The Great Chinese AI Acceleration
The sheer velocity of Chinese AI development this week signals a fundamental shift in the global AI landscape. Alibaba's daily feature drops for Wan 2.2 aren't just a marketing stunt, they represent a new development philosophy where continuous deployment replaces quarterly releases. Combined with StepFun's 321B open-source model and DeepSeek's benchmark-crushing Janus-Pro, Chinese labs are proving they can match Western capabilities while moving significantly faster.
This acceleration has immediate implications: the traditional advantages of Western AI labs (compute, talent, data) matter less when competitors ship improvements daily rather than quarterly. For practitioners, this means the tools and capabilities available for multimodal applications will evolve continuously. Organizations need to build flexible systems that can integrate new models and features as they emerge, not rigid pipelines tied to specific model versions.
VLM Fragility: The Gap Between Demos and Deployment
The research exposing how easily VLMs break when questions aren't phrased "correctly" highlights a critical deployment challenge. These models excel at benchmarks where questions follow predictable patterns but struggle with the messy reality of human communication. This isn't just an academic concern, it directly impacts whether multimodal systems can be trusted in production.
The implications are sobering: current evaluation metrics dramatically overstate real-world reliability. Organizations deploying VLMs need robust fallback mechanisms and shouldn't assume benchmark performance translates to handling actual user queries. The path forward requires training on more diverse, realistic data that includes all the ways humans actually communicate, not just clean question-answer pairs.
Modular Multimodal: The End of Monolithic Models
Meta's HairCUP and E-FineR represent a broader shift from "one model to rule them all" toward composable, modular systems. Just as software moved from monolithic applications to microservices, multimodal AI is discovering that specialized components working together outperform giant models trying to do everything.
This modularity enables entirely new workflows: imagine searching for "all images with this hairstyle but different faces" or "products with this texture but different shapes." Content doesn't need to be indexed as indivisible units anymore. For developers, this means thinking in terms of multimodal APIs and components rather than end-to-end models. The winning systems will be those that can flexibly combine specialized modules for specific tasks.
🧩 Community + Shoutouts
Builder of the Week: @multimodalart for HunyuanWorld Viewer Demo
@multimodalart created an intuitive viewer for exploring 3D worlds generated by Tencent's HunyuanWorld model. The demo transforms complex 3D generation outputs into an accessible, navigable experience that anyone can explore.
Links: Announcement | HuggingFace Demo
That's a wrap for Multimodal Monday #19! This week proved that the multimodal AI landscape can shift dramatically in just seven days. Chinese labs are setting a blistering pace, our best models are more fragile than we thought, and the future looks increasingly modular and open.
Ready to build multimodal solutions that actually work? Let's talk