Multimodal Monday #34: Visuals Coherence, Semantic Vision
Week of Nov 17-23, 2025: Nano Banana Pro creates coherent visualizations, SAM 3 segments by concept not pixels, HunyuanVideo 1.5 leads open-source video, and Step-Audio-R1 matches Gemini 3 Pro on audio reasoning.

📢 Quick Hits (TL;DR)
Complex visuals and visualizations that actually work - Nano Banana Pro generates professional infographics where text, diagrams, and relationships all work correctly. Ask for detailed scientific diagrams or technical schematics with multiple text elements and get publication-ready output, not artistic gibberish.
Segmentation by concept, not description - SAM 3 understands what you mean, not just what you describe. Point at something and say "the concept behind this interaction" and it detects, segments, and tracks objects across images and video using ideas instead of visual features.
Neural retrieval meets classical search - Microsoft's Weighted Chamfer adds BM25-style token weighting to ColBERT's multi-vector retrieval. Some words matter more than others when you search, and this simple addition boosts performance without architectural changes.
🧠 Research Highlights
Mixture of States: Routing Token-Level Dynamics for Multimodal Generation
Meta routes different tokens through different processing pathways in their Mixture of States architecture. This routing mechanism improves output quality and diversity in their SAM 3 model.

Why it matters: Token-level routing gives models more flexibility to handle different types of content within a single generation.
Links: Paper
Incorporating Token Importance in Multi-Vector Retrieval
Microsoft's Weighted Chamfer enhances ColBERT by weighting tokens based on their importance, similar to BM25's term weighting. The method improves retrieval performance without adding computational overhead.
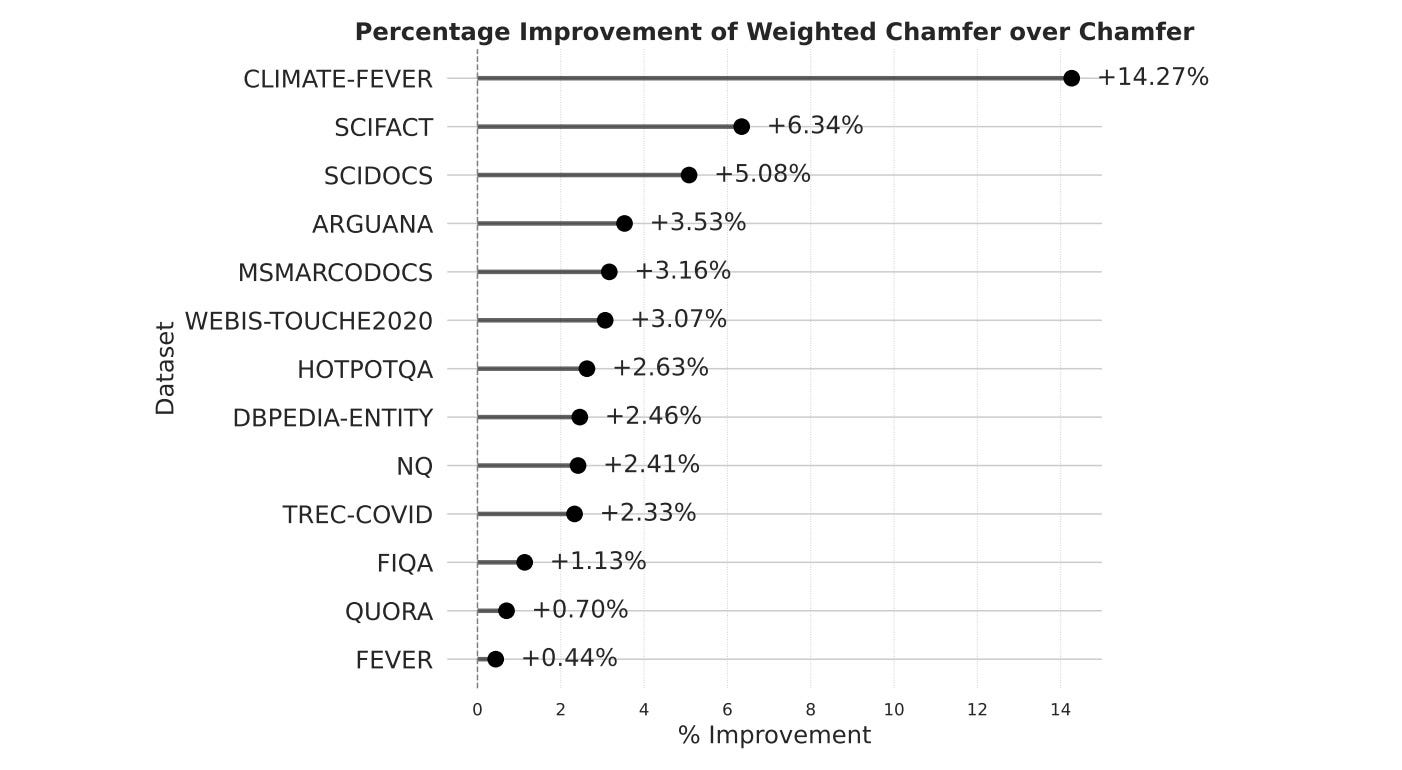
Why it matters: You get better search results by recognizing that not all tokens contribute equally to meaning.
Links: Paper | GitHub
LEMUR: Large-Scale End-to-End Multimodal Recommendation
ByteDance deployed LEMUR on Douyin as an end-to-end multimodal recommendation system. The framework jointly optimizes multimodal encoders and ranking models in unified training.
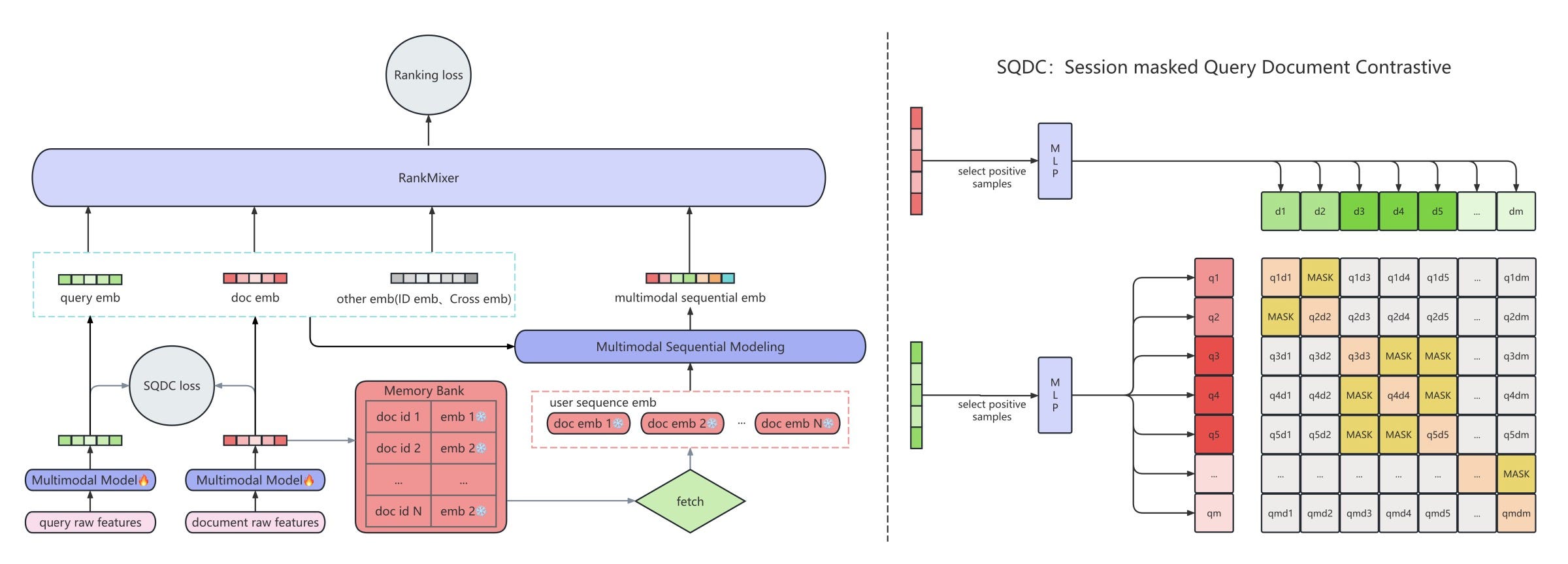
Why it matters: This shows how to build recommendation systems that handle multiple data types without separate pipelines.
Links: Paper
Graph Retrieval-Augmented Generation: A Survey
This survey covers how structured graph data enhances LLM responses through GraphRAG. The approach enables precise multi-hop reasoning and comprehensive information retrieval beyond keyword matching.
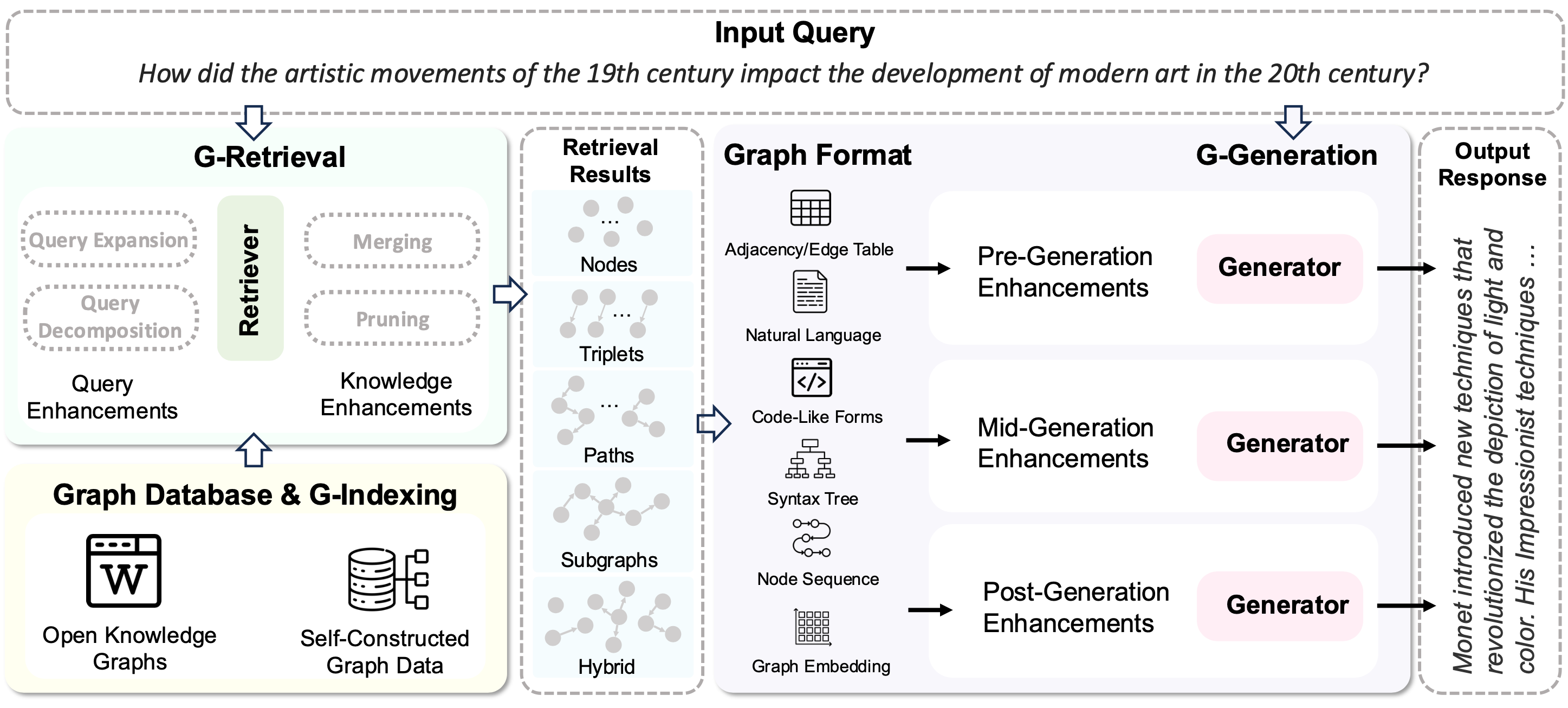
Why it matters: Graphs capture relationships that flat text misses, making your RAG systems smarter about connections.
Links: Paper | GitHub
Orion: A Unified Visual Agent
Orion integrates vision-based reasoning with tool-augmented execution. The agent orchestrates specialized computer vision tools to execute complex multi-step visual workflows.
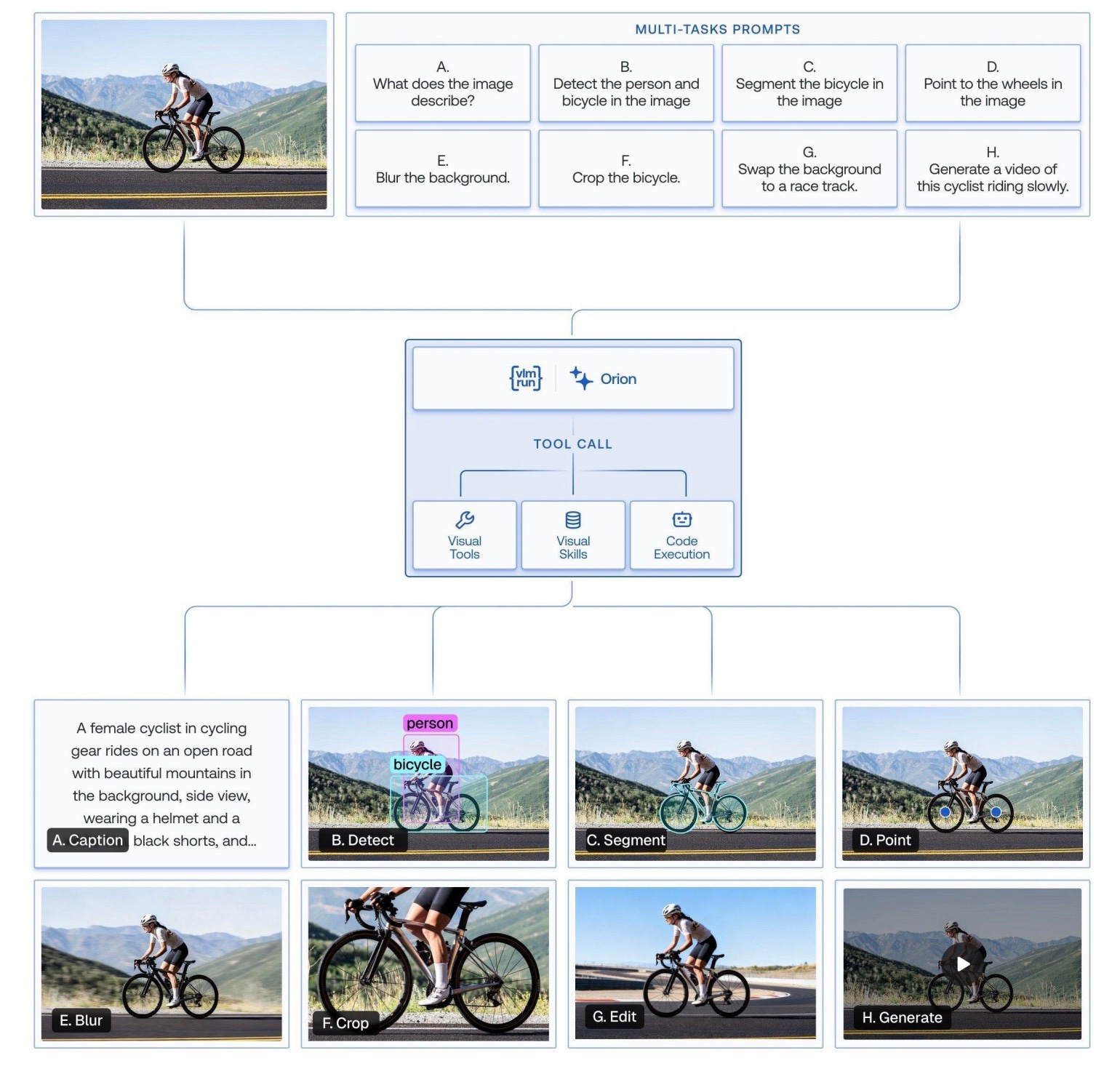
Why it matters: Visual agents can now plan and execute tasks using multiple tools, not just answer questions about images.
Links: Paper
Think, Speak, Decide - Language-augmented multi-agent reinforcement learning for economic decision-making.
Links: Paper
Joint-Embedding vs Reconstruction - This paper formalizes why latent space prediction outperforms input space prediction for certain modalities.
Links: Blog Post | Paper | Announcment
First Frame Is the Place to Go for Video Content Customization - Video models implicitly treat the first frame as a conceptual memory buffer.
Links: Project Page | Paper | GitHub
VisPlay - A self-evolving RL framework for VLMs to autonomously improve reasoning from unlabeled image data.
Links: Project Page | Paper
VIRAL - Visual Sim-to-Real at Scale.
Links: Website | Paper
REVISOR - Multimodal reflection for long-form video understanding.
Links: Paper
MMaDA-Parallel - A parallel multimodal diffusion framework for thinking-aware image editing and generation.
Links: Paper | Models
WEAVE - A 100K-sample interleaved multimodal dataset and benchmark for visual memory and multi-turn editing.
Links: Paper | GitHub | Hugging Face
🛠️ Tools, Models and Techniques
Gemini 3 and Nano Banana Pro
Gemini 3 is Google's universal translator, accepting any input type and outputting whatever format your task demands. Nano Banana Pro is where complex visualization generation finally works: Request infographics about quantum computing, DNA replication, financial market dynamics, or engineering systems and receive coherent professional output. Text reads correctly. Diagrams connect logically. Mathematical notation renders properly. The model understands what should be emphasized, how elements relate, and what makes a visualization useful versus decorative.
Why it matters: The pipeline: Gemini 3 for concept development → Nano Banana Pro for visualization → Veo 3.1 for animation, replaces weeks of specialized work with minutes of prompting. Teachers generate custom diagrams for every concept. Journalists create data visualizations in real-time. Anyone with domain knowledge can produce professional visual content.
Links: Gemini 3 | Nano Banana Pro | Announcement
SAM 3 and SAM 3D
Meta's SAM 3 detects, segments, and tracks objects across images and videos using conceptual prompts. SAM 3D extends this to 3D human mesh recovery.
Why it matters: You can now identify and track objects by describing concepts, not just visual features.
Links: SAM 3 | SAM 3D | ComfyUI-SAM3DBody
HunyuanVideo 1.5
Tencent released HunyuanVideo 1.5, the strongest open-source video generation model. Built on the DiT architecture, it sets a new standard for open-source video quality and accessibility.
Why it matters: You get high-quality video generation without commercial licensing fees.
Links: Project Page | GitHub | Hugging Face | Technical Report
Jan-v2-VL
Jan-v2-VL executes 49 steps in long-horizon tasks without failure. The base model stops at 5 steps, similar-scale VLMs stop between 1 and 2.
Why it matters: This model handles extended task sequences that break other vision-language models.
Links: Hugging Face | Announcement
Step-Audio-R1
StepFun-Audio released Step-Audio-R1, the first audio reasoning model with chain-of-thought capabilities. It outperforms Gemini 2.5 Pro and matches Gemini 3 Pro on audio tasks.
Why it matters: Audio AI can now reason through problems step by step, like text models do.
Links: Project Page | Paper | GitHub
Supertonic TTS - A fast speech model that runs on-device.
Links: Demo | GitHub
📈 Trends & Predictions
When Text in Images Actually Reads Right
Image generators have struggled with text for years. You'd get something that looked decent from across the room. Zoom in and the letters dissolved into gibberish. Numbers made no sense. Diagrams contradicted themselves. This kept generative AI locked into artistic images and simple graphics.
Nano Banana Pro changes this. The model generates infographics with multiple text elements at different sizes, all readable. Diagrams connect logically. Structured visualizations communicate information instead of just looking busy.
The model understands relationships between elements. A chart's title corresponds to its data. Labels point to the right things. Text hierarchy makes sense. This wasn't possible before. Here's what you can do now. Use Gemini 3 to draft your visualization concept. Feed that to Nano Banana Pro for generation. Take the output to Veo 3.1 for animation. You go from idea to polished explainer video in minutes.
Build applications that generate custom visualizations on demand. Create dynamic infographics that adapt to user queries. Produce visual content at scale without hiring designers. The workflow becomes: describe what you need, get a professional result. Education changes when teachers generate custom diagrams for every concept. Journalism shifts when reporters create data visualizations in real time. Marketing teams produce hundreds of variants to test messaging. Anyone with an idea can create professional visual content.
The technical barrier vanished. You don't need design skills anymore. You need clear thinking about what information matters and how to present it. The model handles execution.
Retrieval Learns From Search's Old Tricks
ColBERT represented a leap in retrieval technology by encoding queries and documents as multiple vectors instead of single embeddings. This captured more nuanced meaning. But it treated every token equally, which doesn't match how language works. Microsoft's Weighted Chamfer borrows from BM25, the search algorithm that dominated information retrieval for decades. BM25 recognized that "algorithm" matters more than "the" when you search. Weighted Chamfer applies this insight to ColBERT's multi-vector approach. The implementation is straightforward. Weight tokens based on their importance to meaning. "Quantum computing applications" gets different weights for each word. "Applications" and "quantum" score high. "Computing" matters less because it's implied. The model learns these weights from data.
This simple addition improves retrieval performance measurably. You get better results without redesigning the architecture or adding computational overhead. The insight: newer isn't always better. Sometimes you take what worked in older systems and apply it to new approaches.
The pattern repeats across AI development. Attention mechanisms borrowed from neuroscience. Residual connections came from signal processing. Batch normalization adapted techniques from statistics. Progress comes from combining proven ideas in new contexts, not just inventing from scratch.For your retrieval systems, this means looking at what worked before neural networks. Term weighting, document frequency, position encoding. These concepts still matter. Modern architectures give you new ways to implement old wisdom.
GraphRAG takes this further by adding structure to retrieval. Instead of treating documents as flat text, map relationships between concepts. When someone asks a complex question, traverse the graph to gather connected information. Multi-hop reasoning becomes possible because you encoded how ideas relate.
The combination of weighted tokens and graph structure gives you retrieval systems that handle complex queries. You can answer "How does X affect Y, and what are the implications for Z?" by following edges through your knowledge graph, weighting information by relevance as you go.
Community + Shoutouts
Awesome-Spatial-Intelligence-in-VLM: MLL Lab curated a collection of recent papers on Spatial Intelligence for researchers and engineers.
Links: GitHub
FaceFusion ComfyUI: Shoutout to Github user huygiatrng who built FaceFusion ComfyUI, an advanced face swapping tool with local ONNX inference.
Links: GitHub | Reddit
ComfyUI-SAM3DBody: Shoutout to PozzettiAndrea who created ComfyUI-SAM3DBody for single-image full-body 3D human mesh recovery.
Links: GitHub
Nano Banana Pro to 3D Printable Model Workflow: Shoutout to Travis Davids who shared his Nano Banana Pro to 3D printable models workflow.
Links: Post
FFGO Workflow: Shoutout to Reddit user ZorakTheMantis123 shared a working FFGO workflow.
Links: Reddit
Boreal LoRA: Shoutout to kudzueye for "Boreal," an experimental LoRA for realistic photography.
Links: Hugging Face

That's a wrap for Multimodal Monday #33! Nano Banana Pro generates complex visualizations with readable text and coherent diagrams. SAM 3 segments by concept, not pixels. Weighted Chamfer adds BM25-style token weighting to ColBERT. HunyuanVideo 1.5 sets new open-source video standards. Jan-v2-VL executes 49-step tasks where other VLMs fail at step 5. Step-Audio-R1 brings chain-of-thought reasoning to audio.
Ready to build multimodal solutions that actually work? Let's talk.