Multimodal Monday AI #37: Less-Is-More, Analogical Vision
Week of Dec 9-14, 2025: Apple proves one attention layer beats dozens in diffusion models, MokA shows low-rank adaptation outperforms full fine-tuning, Adobe's relsim captures analogical relationships between images, and X-VLA controls different robot types with one transformer.

📢 Quick Hits (TL;DR)
AI understands analogies between images. Adobe’s new relsim metric helps models grasp deep visual relationships. A peach’s cross-section mirrors Earth’s layers. Your model can finally see these connections.
Apple proves one attention layer can beat dozens. Their new paper shows a single attention layer converts pretrained vision features into SOTA image generators. MokA shows you can adapt multimodal models with fewer parameters and better results.
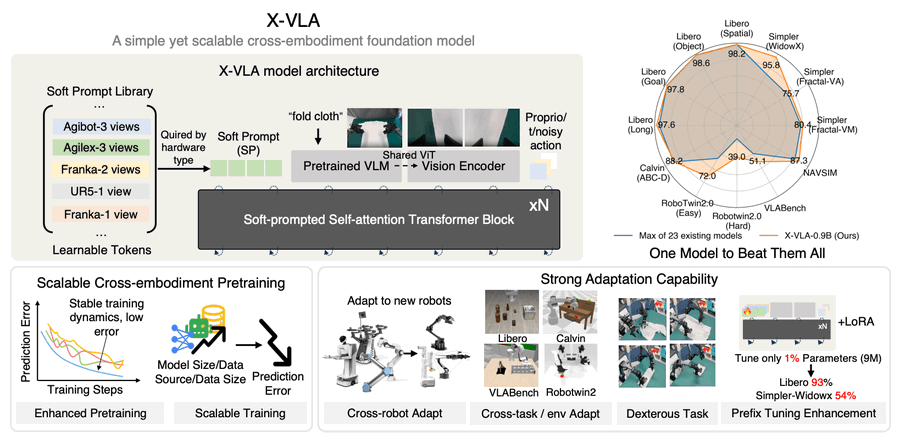
AI gets a body (and a phone). X-VLA is a soft-prompted transformer that controls totally different robots like they’re one species. And AutoGLM, open-source phone agent framework, enables autonomous task completion on Android devices through natural language commands.
🧠 Research Highlights
Relational Visual Similarity
Adobe Research and UW-Madison developed relsim, a metric that captures analogical relationships between images rather than surface-level features. The model understands that a peach’s layers relate to Earth’s structure the same way a key relates to a lock.
Links: Paper
One Attention Layer is Enough
Apple demonstrates that a single attention layer transforms pretrained vision features into state-of-the-art image generators. This approach simplifies diffusion models while maintaining top-tier quality.
Links: Paper
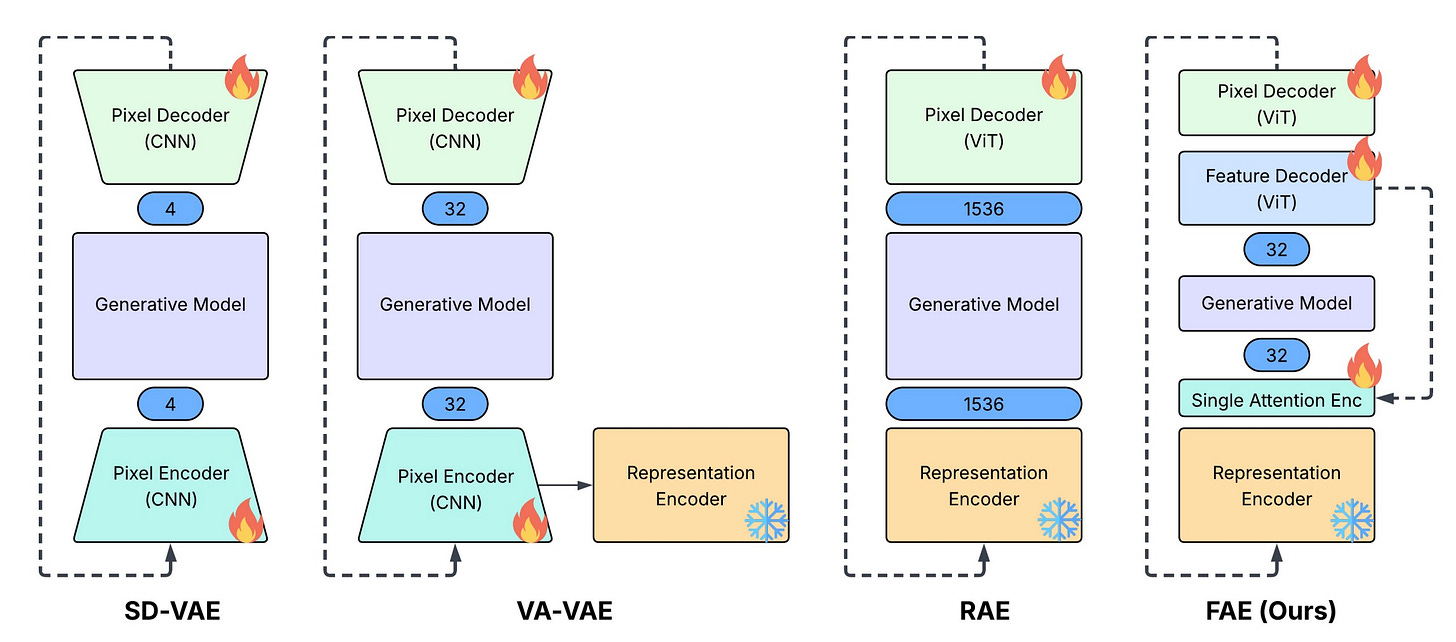
Unison: A Fully Automatic, Task-Universal, and Low-Cost Multimodal Framework
Unison automates multimodal tasks across text, images, and video without task-specific retraining. The framework uses efficient fusion techniques that work across different modalities with minimal computational overhead.
Links: Paper
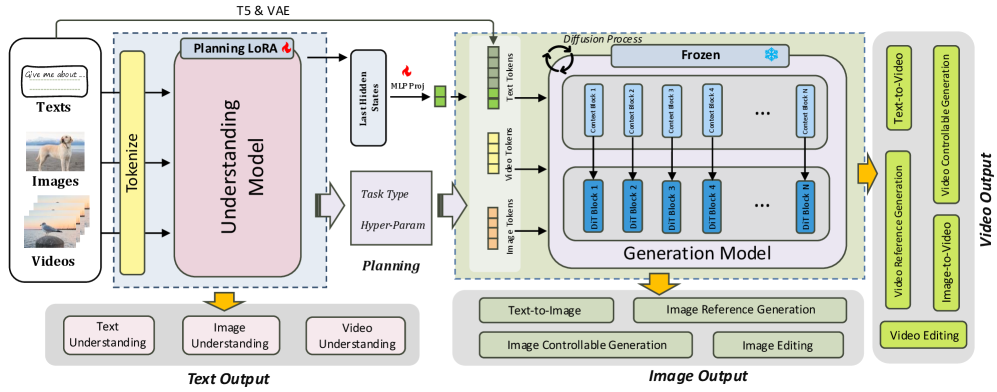
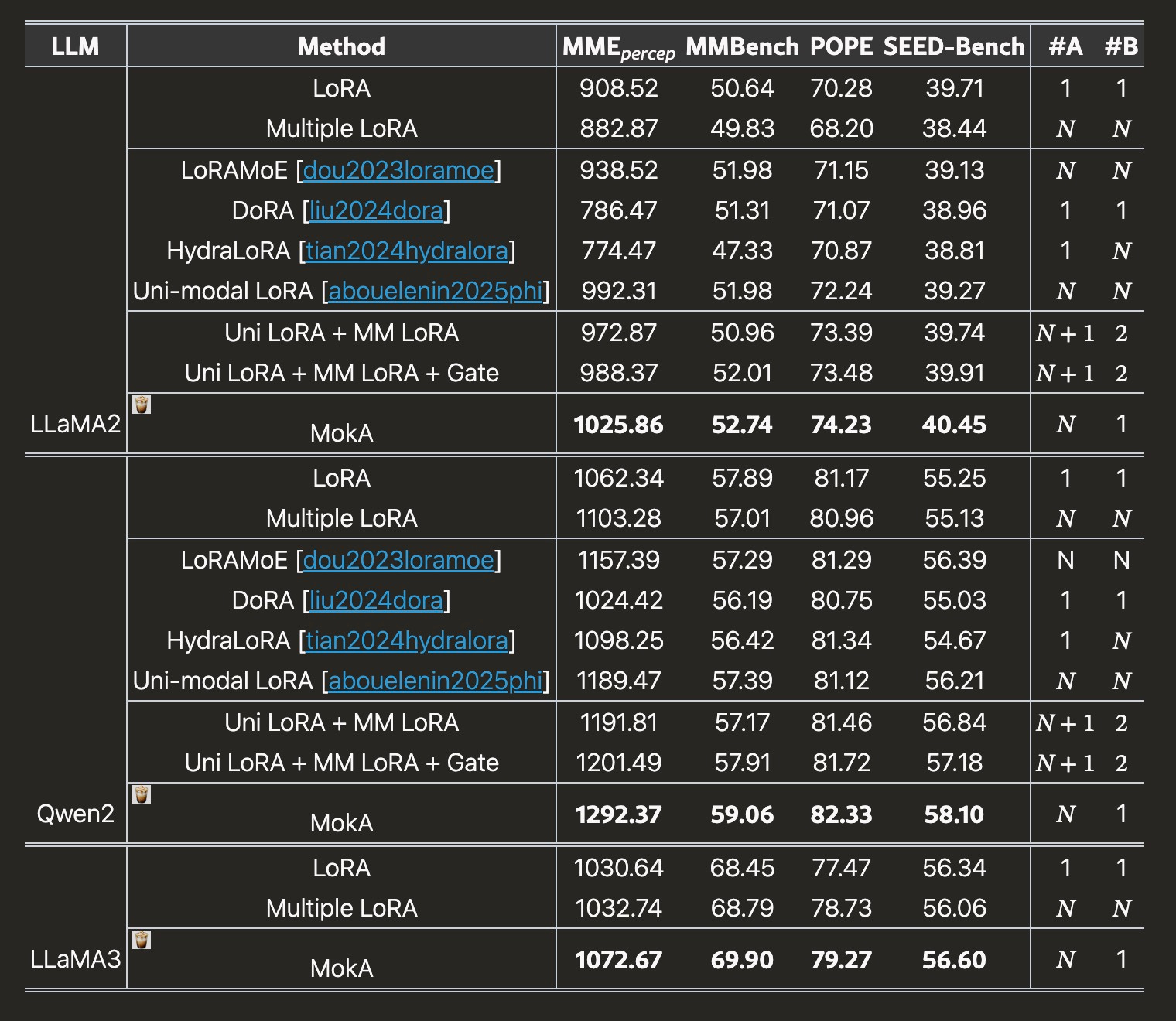
MokA: Multimodal Low-Rank Adaptation for MLLMs
MokA reveals that current multimodal fine-tuning wastes parameters and proposes a low-rank method that improves visual-language integration. The approach beats standard fine-tuning on visual grounding benchmarks while using fewer parameters.
Links: Paper
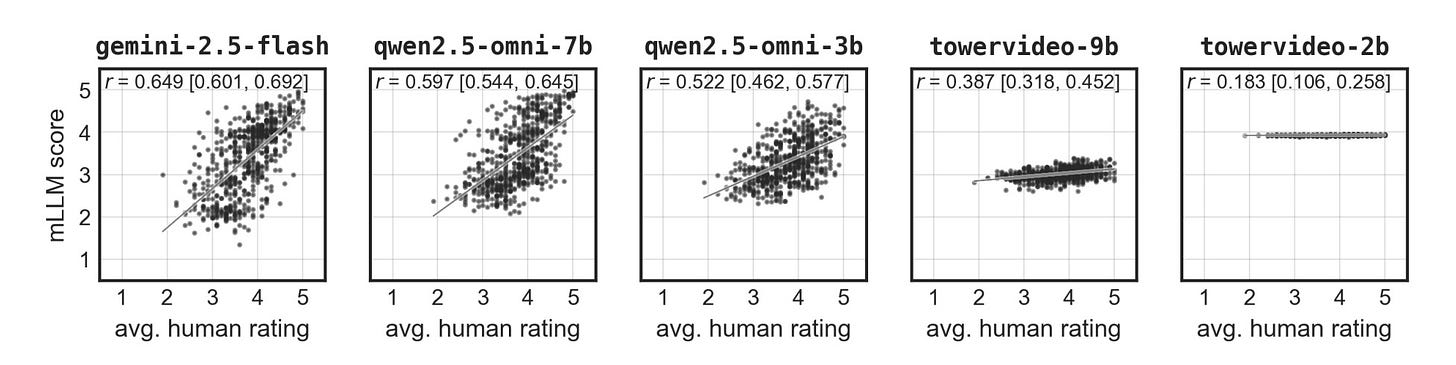
Computational Emotion Analysis with Multimodal LLMs
Researchers evaluate how well multimodal LLMs analyze emotions from audio-visual data. The paper identifies gaps in current methods and shows where generative AI can improve affective computing.
Links: Paper
WonderZoom: Generates multi-scale 3D worlds from text descriptions. Links: Paper
X-VLA: Soft-prompted transformer that controls different robot types using a unified interface. Links: Docs
MoCapAnything: Captures 3D motion for arbitrary skeletons from single-camera videos. Links: Paper
RouteRAG: Uses reinforcement learning to efficiently retrieve from both text documents and knowledge graphs. Links: Paper | GitHub
🛠️ Tools, Models and Techniques
AutoGLM
z.ai released AutoGLM, an open-source framework that completes tasks on Android phones through natural language commands. AutoGLM-Phone-9B is available on Hugging Face and ModelScope.
Why it matters: You can now build agents that interact with real-world smartphone apps.
Links: Website
Apriel-1.6-15B-Thinker
ServiceNow’s 15B multimodal model scores 57 on the Artificial Analysis Intelligence Index, matching the performance of 200B-scale models. The model handles reasoning tasks at a fraction of the size.
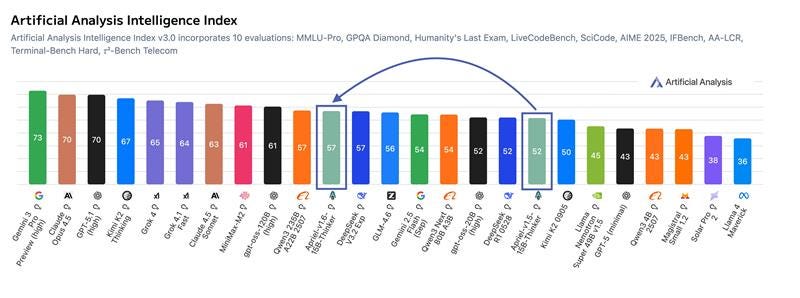
Why it matters: You get frontier-level multimodal reasoning in a model small enough to self-host.
Links: Model | Blog | Demo
GLM-4.6V
Z.ai released GLM-4.6V with tool-calling and 128K context window for vision-language tasks. The model handles multilingual development and API integration.
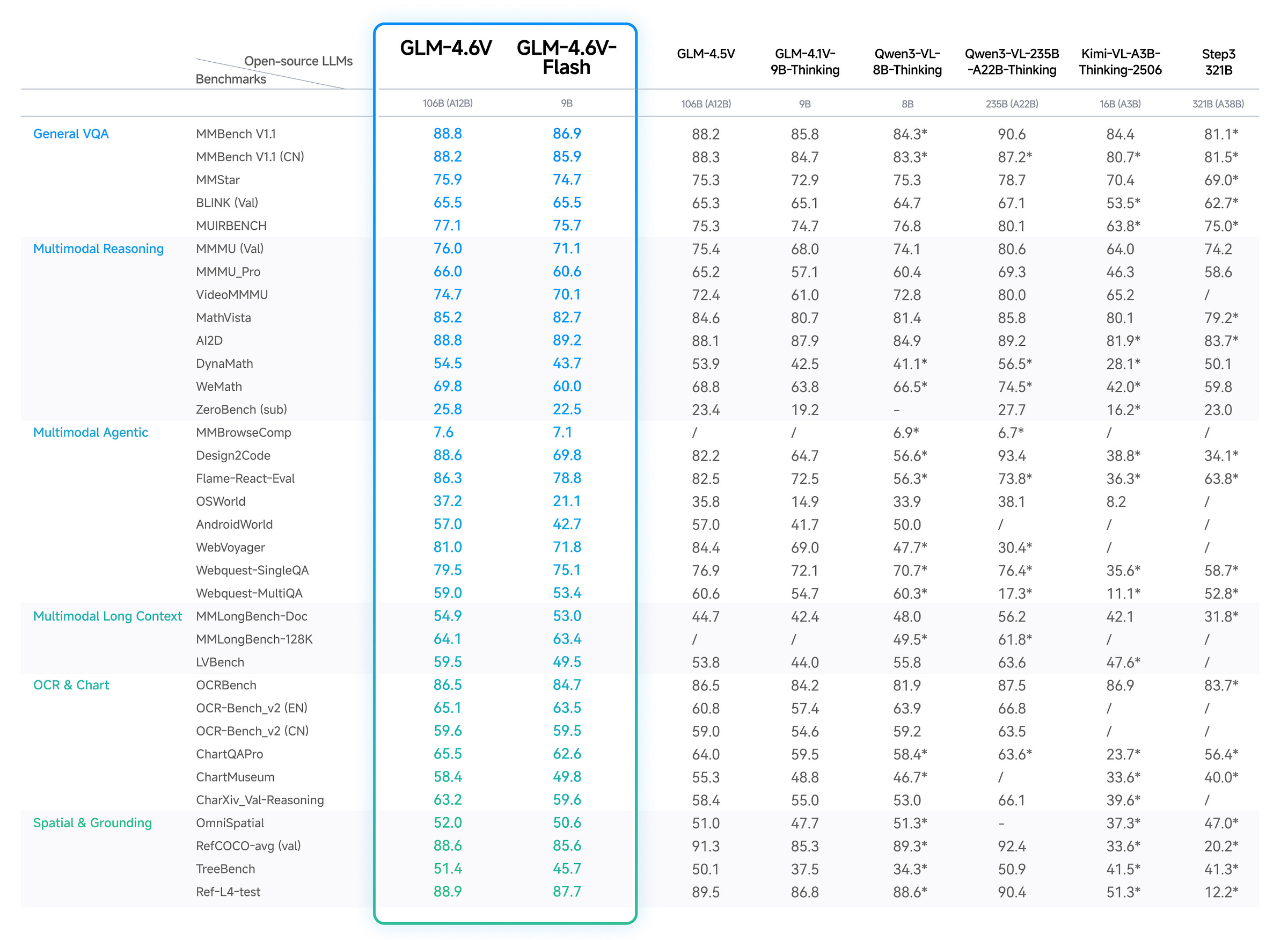
Why it matters: You get long-context multimodal processing with native tool support.
Links: Blog | GitHub | Demo
GPT-5.2
OpenAI released GPT-5.2, their latest frontier model. The model advances capabilities across reasoning, generation, and multimodal understanding.
Why it matters: The new baseline for frontier model performance just shifted.
Links: Twitter | Blog
DMVAE
Tencent and PKU released DMVAE, a VAE that matches latent distributions to any reference. The model achieves state-of-the-art image synthesis with fewer training epochs.

Why it matters: You can control the distribution of your generated images more precisely.
Links: Paper | Model
Qwen-Image-i2L: First open-source tool that converts a single image into a custom LoRA. Links: ModelScope | Code
Dolphin-v2: 3B parameter model that parses any document type. Links: Hugging Face
RealGen: Improves text-to-image photorealism using detector-guided rewards. Links: Website | Paper | GitHub | Models

Qwen 360 Diffusion: State-of-the-art 360° text-to-image generation. Links: Hugging Face | Viewer

Any4D: Unified transformer for feed-forward, dense, metric-scale 4D reconstruction. Links: Website | Paper | Demo
Shots: Generates 9 cinematic camera angles from a single image with perfect consistency. Links: Twitter
📈 Trends & Predictions
The Great Simplification
We’re watching complexity collapse in real time. Apple needs one attention layer where others use dozens. Unison handles any modality without retraining. MokA beats full fine-tuning with a fraction of the parameters.
This isn’t about making things smaller. It’s about removing the cruft that never belonged there.
What This Means for You
Your multimodal systems can run faster and cheaper. A single-layer model fits on hardware that was out of reach last year. You can index a billion images on a single GPU.
Your systems can become more adaptable. Unison adds new modalities without retraining. You can build applications that were too complex before.
Your models become more transparent. Low-rank adaptation means fewer parameters to debug. You can explain why your system retrieved a specific image.
This is multimodal AI for teams with real constraints. Not just for companies with unlimited compute budgets.
🧩 Community + Shoutouts
Nano Banana Pro Solution Shoutout to rob from ComfyUI for sharing a solution that addresses the biggest downside to Nano Banana Pro (the cost and slow generation speed). 1 prompt = 9 distinct images at 1K resolution (~3 cents per image). Links: Twitter
Multimodal Benchmarks GitHub Repo Shoutout to Mixpeek for releasing a Multimodal Benchmarks GitHub repo. A great resource for anyone who is working on multimodal AI. Links: GitHub
67 New Z Image LoRAs Shoutout to Reddit user malcolmrey for releasing 67 new Z Image LoRAs. A great resource for anyone who is using Z Image. Links: Reddit
That’s a wrap for Multimodal Monday #37! Apple proves one attention layer generates SOTA images. Adobe’s relsim captures analogies between images. MokA beats full fine-tuning with low-rank adaptation. RouteRAG navigates knowledge graphs with reinforcement learning. X-VLA controls different robots with one transformer. AutoGLM completes tasks on Android phones. Apriel-1.6-15B matches 200B-scale models at 15B parameters.
Ready to build multimodal solutions that actually work? Let's talk