Multimodal Monday #38: World Models, Real-Time Generation
Week of December 16 - December 22, 2025: TurboDiffusion achieves 100-205x video generation speedup, WorldPlay generates interactive 3D worlds with geometric consistency, Step-GUI reaches SOTA on AndroidWorld & OSWorld benchmarks, and LongVie 2 produces 5-minute continuous videos.

Quick Hits (TL;DR)
Long Context Solved Multiple Ways. LongVie 2 generates 5-minute continuous videos through architectural improvements. MemFlow handles streaming video through adaptive memory that decides what to remember. WorldPlay maintains geometric consistency across extended sequences.
Video generation gets a speed boost. TurboDiffusion accelerates video diffusion models by 100-205 times, making real-time video generation practical for the first time. And ReFusion bridges ARMs and MDMs for efficient, high-performance text generation.
The Living Edge is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Layer-Based Control Emerges. Qwen-Image-Layered separates images into editable RGBA layers. StereoPilot handles depth-aware stereo conversion. Generative Refocusing controls focus layers. DeContext adds protection layers.
Tools, Models and Techniques
T5Gemma 2
Google released T5Gemma 2, the next generation of encoder-decoder models. The architecture combines bidirectional understanding with flexible text generation.
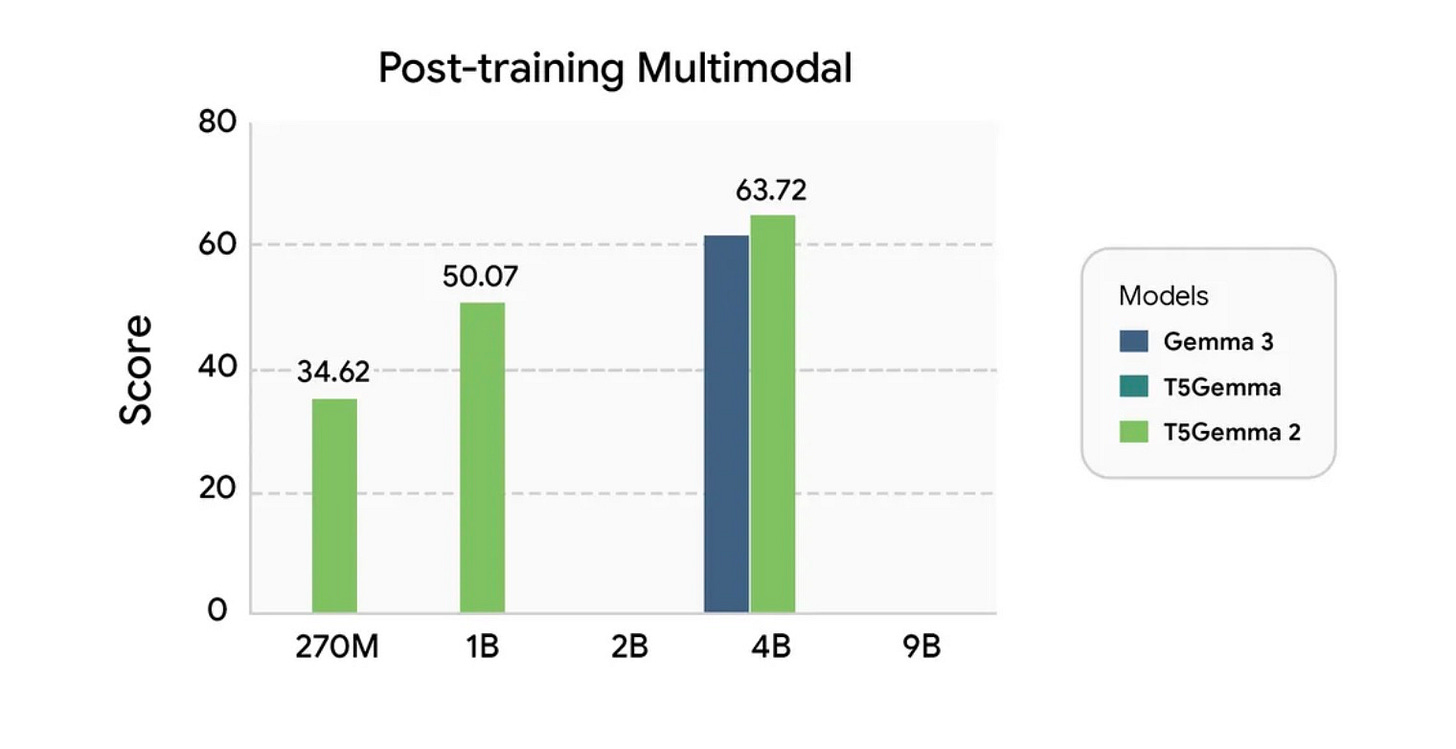
Why it matters: T5Gemma 2 handles tasks that require both deep comprehension and creative output in a single model.
Links: Blog | Model
Perception Encoder Audiovisual (PE-AV)
Meta released PE-AV, the technical engine behind SAM Audio’s audio separation capabilities. The model processes both visual and audio information to isolate individual sound sources.
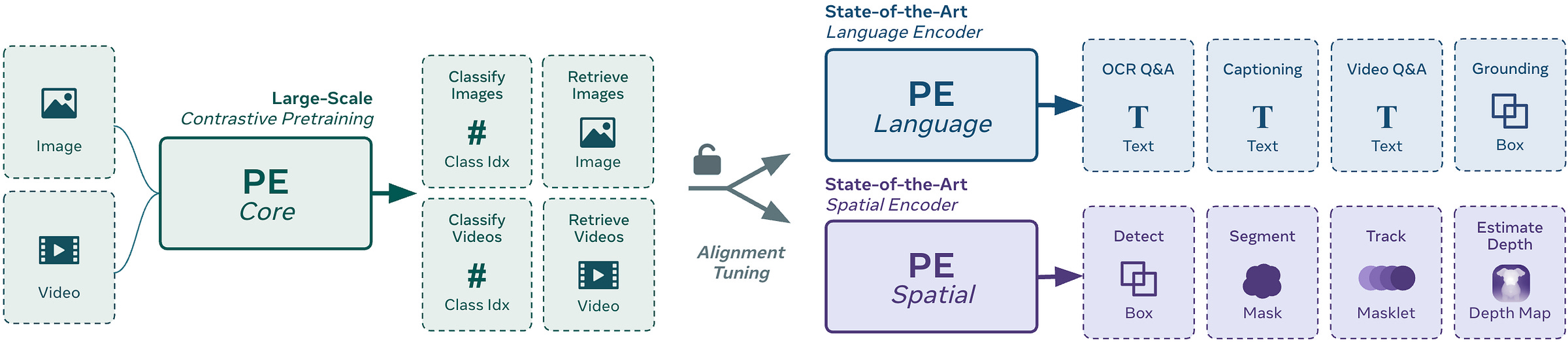
Why it matters: PE-AV separates overlapping audio sources with unprecedented accuracy by understanding what objects should sound like.
Links: Announcement | Paper | Code
MiMo-V2-Flash
Xiaomi released MiMo-V2-Flash, optimized for speed in real-time applications. The model sacrifices some accuracy for dramatic latency reductions.
Links: Hugging Face | Report | Blog
TurboDiffusion
TurboDiffusion accelerates video diffusion models by 100-205 times through architectural optimizations. The speedup comes from reducing redundant computations without quality loss.
Why it matters: Video generation moves from minutes per frame to real-time speeds, enabling interactive applications.
Links: Hugging Face | GitHub | Paper
Qwen-Image-Layered
Qwen-Image-Layered decomposes images into multiple RGBA layers that can be independently edited. Each layer isolates specific semantic or structural components while maintaining visual coherence.
Why it matters: Image editing becomes precise and reversible when you control individual layers instead of manipulating pixels directly.
Links: Hugging Face | ModelScope | Paper | Announcement | Demo
N3D-VLM
N3D-VLM grounds spatial reasoning in native 3D representations rather than 2D projections. The model understands depth, distance, and spatial relationships directly.
Why it matters: Vision-language models gain accurate spatial understanding without the distortions inherent in 2D image analysis.
Links: GitHub | Website | Model
MemFlow
MemFlow maintains adaptive memory for long streaming videos, deciding which frames to remember and which to discard. The system balances memory efficiency with video understanding quality.
Why it matters: You can now process hours of video without exhausting memory or losing critical context.
Links: Website | Paper | Model
WorldPlay
Tencent’s WorldPlay generates interactive 3D worlds with long-term geometric consistency. The model maintains spatial relationships across extended video sequences, allowing persistent interaction with generated environments.
Why it matters: AI-generated worlds become navigable spaces instead of static videos.
Links: Website | Paper | Model
LongVie 2
LongVie 2 generates 5-minute continuous videos with controllable elements and consistent geometry. The model handles multiple modalities and maintains coherence across thousands of frames.
Why it matters: Video generation moves from clips to scenes with the length and control needed for actual storytelling.
Links: Paper | Website | GitHub
FoundationMotion
FoundationMotion labels and analyzes spatial movement in videos automatically. The system identifies motion patterns and spatial trajectories without manual annotation.
Why it matters: Video datasets gain spatial movement labels at scale, enabling better motion understanding in future models.
Links: Paper | GitHub | Demo | Dataset | Models
Generative Refocusing
Generative Refocusing controls depth of field in existing images, simulating camera focus changes after capture. The model infers 3D scene structure to generate realistic blur patterns.
Why it matters: You gain photographer-level depth control without specialized camera equipment or multiple exposures.
Links: Website | Demo | Paper | GitHub
StereoPilot
StereoPilot converts 2D videos to stereo 3D through learned generative priors. The system produces depth-aware conversions suitable for VR headsets.
Why it matters: Existing 2D content becomes viewable in 3D without manual conversion or specialized filming.
Links: Website | Model | GitHub | Paper
LongCat-Video-Avatar Links: Website | GitHub | Paper | ComfyUI
Chatterbox Turbo: Hugging Face
TRELLIS 2: 3D generative model designed for high-fidelity image-to-3D generation. Links: Model | Demo
Map Anything(Meta): Model
Gemini 3 Flash(Google): Blog
FunctionGemma(Google): Model
Wan 2.6(Alibaba) - Announcement
/agent(Firebase) for agentic web scraping - Announcement
Research Highlights
KV-Tracker: Real-Time Pose Tracking with Transformers
KV-Tracker achieves real-time tracking at 30 FPS without any training. The approach uses transformer key-value pairs to track objects and scenes across frames.
Links: Website | Announcement
DeContext: Protecting Images from Unwanted In-Context Edits
DeContext adds imperceptible perturbations that prevent DiT models like FLUX and Qwen-Image from making unwanted edits. The protection preserves visual quality while blocking manipulation attempts.
Links: Website | Paper | GitHub

EgoX: Generate Immersive First-Person Video from Any Third-Person Clip
EgoX transforms third-person videos into realistic first-person perspectives using video diffusion. The framework from KAIST AI and Seoul National University maintains spatial and temporal coherence during the transformation.
Why it matters: Any third-person footage becomes immersive first-person content without specialized cameras or reshooting.
Links: Website | Paper | GitHub
MMGR: Multi-Modal Generative Reasoning
MMGR benchmarks reveal systematic reasoning failures in GPT-4o and other leading multimodal models. The evaluation exposes gaps between perception and logical inference.
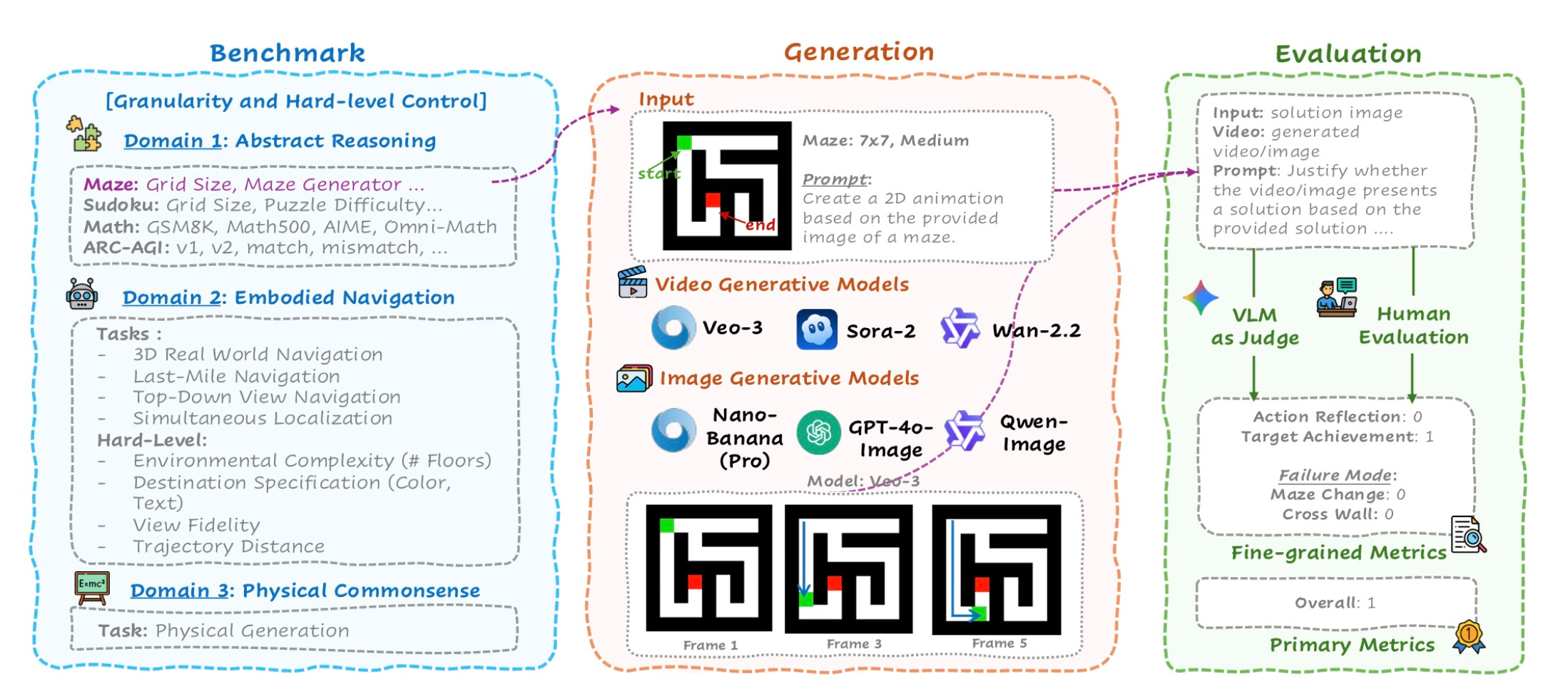
Why it matters: Top models still struggle with basic reasoning tasks despite strong perceptual capabilities.
Links: Website | Paper
KlingAvatar 2.0 and Kling-Omni Technical Report
KlingAvatar 2.0 generates high-fidelity avatar videos through a spatio-temporal cascade framework. Kling-Omni provides a generalist framework for multimodal video generation with a Co-Reasoning Director that fuses instructions across modalities.
Links: Kling-Avatar Paper | Kling-Omni Paper | Try It
Step-GUI Technical Report
Step-GUI introduces a self-evolving pipeline for GUI automation. The system reaches state-of-the-art on AndroidWorld and OSWorld benchmarks through iterative improvement.
Links: Paper | Website | GitHub | Model
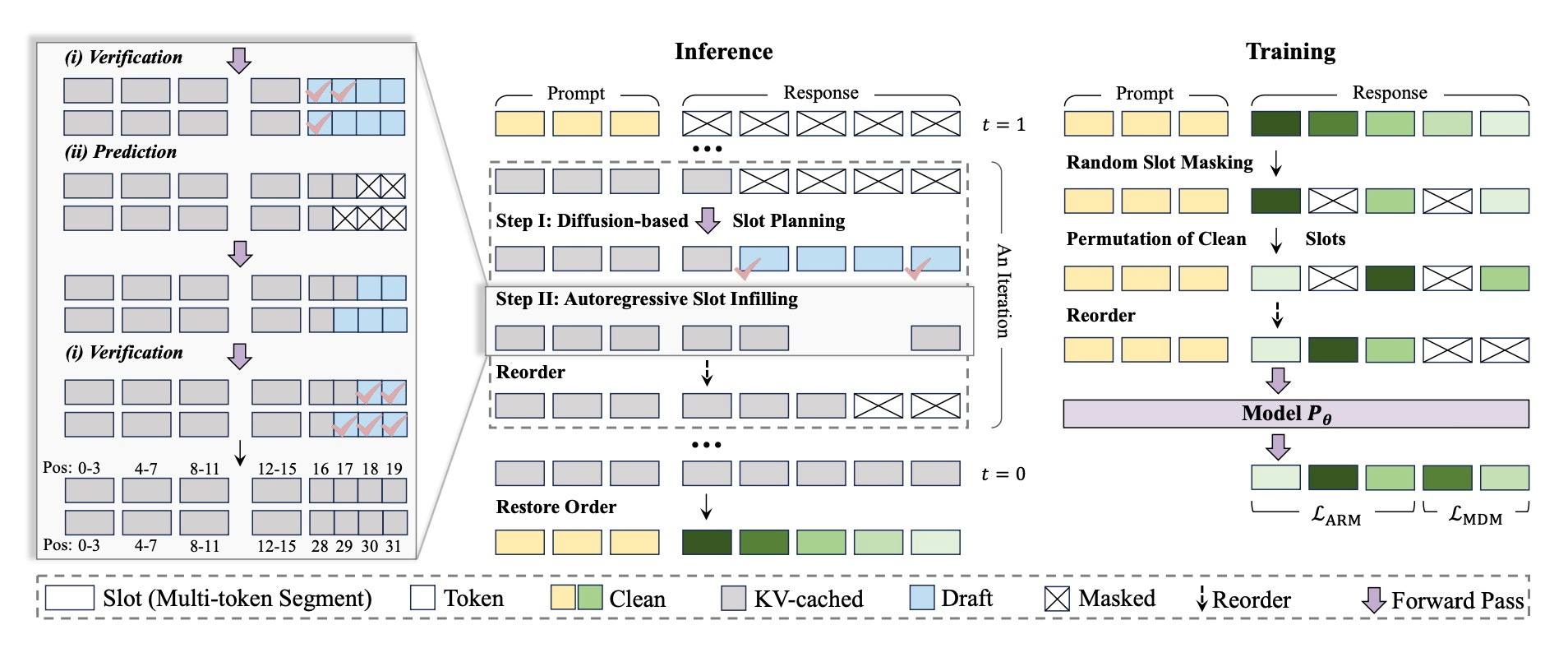
ReFusion
ReFusion combines diffusion models with parallel autoregressive decoding. The architecture bridges autoregressive models and diffusion models for faster text generation.
Links: Paper
DEER
DEER uses diffusion models to draft content and autoregressive models to verify it. The two-stage approach balances generation quality with computational efficiency.
Why it matters: You get diffusion quality at autoregressive speeds by splitting generation and verification.
Links: Paper | Website
IC-Effect
IC-Effect applies video effects through in-context learning without fine-tuning. The system learns effect patterns from examples and applies them to new videos.
Links: Website | GitHub | Paper
Flow Map Trajectory Tilting
Flow Map Trajectory Tilting improves diffusion model outputs at test time using flow maps. The technique adjusts generation trajectories without retraining.
Links: Paper | Website

Trends & Predictions
World Models
Three major releases this week generate videos that understand 3D space. WorldPlay from Tencent maintains geometric consistency across extended sequences. LongVie 2 produces 5-minute continuous videos with controllable elements. Kling-Omni provides a generalist framework for multimodal video generation.
These models don’t just generate pixels. They maintain spatial relationships. When an object moves behind another object in frame 100, it stays behind that object in frame 500. The geometry persists.
This changes video search. You can now index the underlying 3D structure instead of raw pixels. A search for “car turning left at intersection” finds the spatial event, not just visual patterns that look like cars and intersections.
This changes VR and AR. Generated worlds become explorable spaces. You navigate through them instead of watching them.
This changes agent training. Robots learn in simulated 3D environments before deployment. The sim-to-real gap narrows when simulations maintain physical consistency.
The models still have limits. Five minutes is impressive but not enough for long-form content. Geometric consistency breaks down in complex scenes. Control remains imperfect.
But the foundation is here. Video generation now builds worlds, not just sequences of images.
Community + Shoutouts
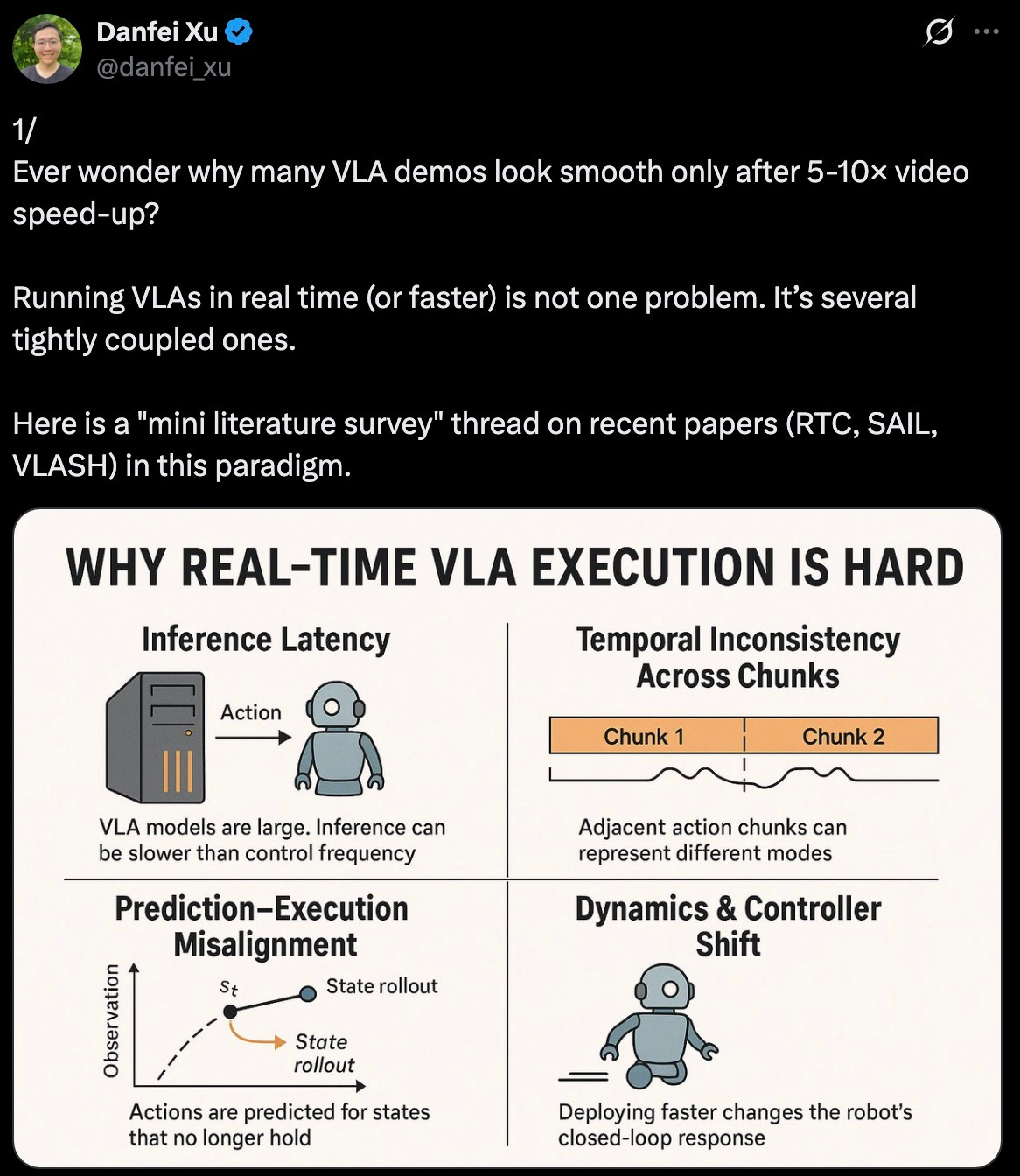
Mini Literature Survey Shoutout to Danfei Xu from Nvidia for a literature survey thread covering recent VLA developments.
Links: Thread
That's a wrap for Multimodal Monday #38! From speed breakthroughs with TurboDiffusion's 100-205x acceleration and KV-Tracker's 30 FPS training-free tracking, to spatial breakthroughs with WorldPlay's interactive 3D worlds and N3D-VLM's native 3D reasoning, to control breakthroughs with Qwen-Image-Layered's RGBA decomposition and DeContext's edit protection, this week shows multimodal AI gaining the speed, spatial understanding, and precision control needed for production applications. The era of slow, 2D, uncontrollable generation is ending.
Ready to build multimodal solutions that actually work? Let's talk