Advanced Video Understanding: Mixpeek Embed and Weaviate KNN for Multimodal AI
This article demonstrates how to build a reverse video search system using Mixpeek for video processing and embedding, and Weaviate as a vector database, enabling both video and text queries to find relevant video segments through semantic similarity.

This tutorial delves into the implementation of a reverse video search and semantic video search using Weaviate as our vector database, and Mixpeek Embed for video embeddings. We'll walk through a practical example using a Jurassic Park trailer as our source database and demonstrate both video-based and text-based queries.
System Architecture
Before we dive into the implementation details, let's visualize the overall architecture of our reverse video search system:
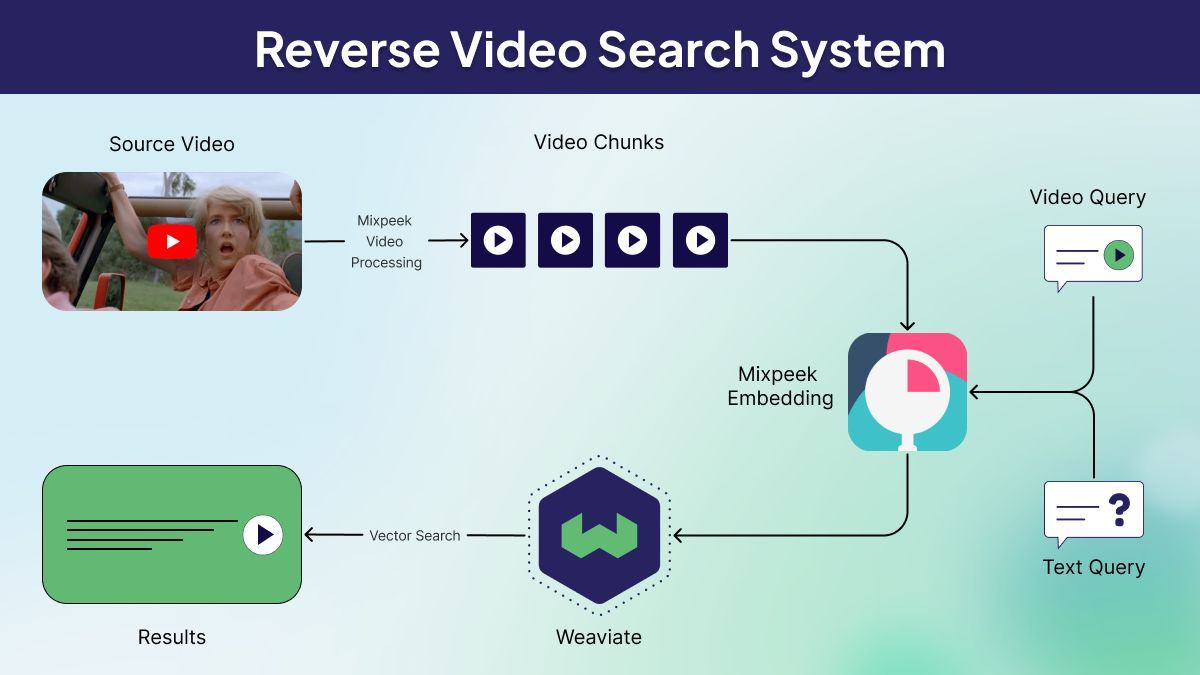
This diagram illustrates the flow of data from the source video through processing, embedding, and storage, as well as the query process for both video and text inputs.
Step 1: Video Ingestion and Embedding
The first step in building our reverse video search system is to process and embed our source video. We'll use a Jurassic Park trailer as our example.
Initializing Clients
We start by setting up our Mixpeek and Weaviate clients:
from mixpeek import Mixpeek
import weaviate
# Initialize the Mixpeek client with your API key
mixpeek = Mixpeek("YOUR_API_KEY")
# Initialize Weaviate client
client = weaviate.Client("http://localhost:8080")
Make sure to replace "YOUR_API_KEY" with your actual Mixpeek API key, and adjust the Weaviate client URL if your instance is hosted elsewhere.
Defining Weaviate Schema
Next, we define a schema for our VideoChunk class in Weaviate:
schema = {
"classes": [{
"class": "VideoChunk",
"vectorizer": "none",
"vectorIndexType": "hnsw",
"vectorIndexConfig": {
"dim": 768 # Dimensionality of vuse-generic-v1 embeddings
},
"properties": [
{"name": "start_time", "dataType": ["number"]},
{"name": "end_time", "dataType": ["number"]}
]
}]
}
# Create schema
client.schema.create(schema)This schema defines a VideoChunk class with properties for the start and end times of each video chunk. We're using HNSW (Hierarchical Navigable Small World) as our vector index type for efficient similarity search. Importantly, we specify the dim parameter in vectorIndexConfig as 768, which matches the output dimensionality of Mixpeek's vuse-generic-v1 model.
Processing and Embedding Video Chunks
Now, we'll process our source video into chunks and embed each chunk:
# Process video chunks
processed_chunks = mixpeek.tools.video.process(
video_source="https://mixpeek-public-demo.s3.us-east-2.amazonaws.com/starter/jurassic_park_trailer.mp4",
chunk_interval=1, # 1 second intervals
resolution=[720, 1280]
)
for chunk in processed_chunks:
print(f"Processing video chunk: {chunk['start_time']}")
# embed each chunk
embed_response = mixpeek.embed.video(
model_id="vuse-generic-v1",
input=chunk['base64_chunk'],
input_type="base64"
)
# Add to Weaviate
client.data_object.create(
"VideoChunk",
{
"start_time": chunk["start_time"],
"end_time": chunk["end_time"]
},
vector=embed_response['embedding']
)
This code processes the video into 1-second chunks, embeds each chunk using Mixpeek's vuse-generic-v1 model, and stores the resulting vector along with the chunk's start and end times in Weaviate.
Step 2: Reverse Video Search
With our video database prepared, we can now perform reverse video searches using either video clips or text descriptions as queries.
Video-based Query
Let's start with a video-based query. We'll use a cartoon "Jurassic Bunny" clip as our search query:
# We'll use a cartoon version of a Jurassic Park scene
file_url = "https://mixpeek-public-demo.s3.us-east-2.amazonaws.com/starter/jurassic_bunny.mp4"
embed_response = mixpeek.embed.video(
model_id="vuse-generic-v1",
input=file_url,
input_type="url"
)
results = (
client.query
.get("VideoChunk", ["start_time", "end_time"])
.with_near_vector({
"vector": embed_response['embedding']
})
.with_limit(10)
.do()
)
for result in results['data']['Get']['VideoChunk']:
print(result)
This query will return the top 10 most similar video chunks from our Jurassic Park trailer database.
Text-based Query
One of the powerful features of this system is the ability to use text queries to search for relevant video segments. Here's how to perform a text-based search:
query = "two people inside a car"
embed_response = mixpeek.embed.video(
model_id="vuse-generic-v1",
input=query,
input_type="text"
)
results = (
client.query
.get("VideoChunk", ["start_time", "end_time"])
.with_near_vector({
"vector": embed_response['embedding']
})
.with_limit(10)
.do()
)
for result in results['data']['Get']['VideoChunk']:
print(result)
This query will return video chunks that are semantically similar to the description "two people inside a car", even though the input is text rather than video.
Results and Analysis
In our experiments, we demonstrated two types of queries:
- Video Query: We used a cartoon "Jurassic Bunny" clip as our search query. This clip is not actually present in the Jurassic Park trailer, but it's modeled after a specific scene. Our reverse video search successfully identified the original scene that inspired the cartoon version.
- Text Query: We used the text description "two boys inside a car". The system was able to find relevant video chunks from the Jurassic Park trailer that match this description, showcasing the model's ability to understand semantic relationships between text and video content.
These results demonstrate the versatility and power of video embeddings in capturing semantic content across different modalities. The vuse-generic-v1 model from Mixpeek is able to understand the context and content of both video scenes and textual descriptions, allowing for robust matching across different input types.
Technical Insights
- Chunking Strategy: We chose 1-second intervals for our video chunks. This granularity allows for precise matching while keeping the database size manageable. Depending on your specific use case, you might want to experiment with different chunk sizes to find the optimal balance between precision and performance.
- Embedding Model: The
vuse-generic-v1model from Mixpeek is designed for general-purpose video understanding. It creates 768-dimensional embeddings that capture both visual and semantic information from video frames. Importantly, it can also create compatible embeddings from text inputs, enabling cross-modal search. This multi-modal capability is crucial for creating flexible and powerful search systems. - Vector Search: Weaviate's HNSW (Hierarchical Navigable Small World) index allows for efficient approximate nearest neighbor search, crucial for quick retrieval in large video databases. HNSW provides a good balance between search speed and accuracy, making it suitable for real-time applications.
- Cross-Modal Search: The ability to use both video and text queries against the same video database showcases the power of semantic embeddings. This opens up possibilities for more flexible and intuitive video search interfaces. Users can search for video content using natural language descriptions, making the system more accessible to a wider audience.
- Scalability: This approach can scale to much larger video databases. As the database grows, you might need to consider techniques like quantization or sharding to maintain performance. Weaviate provides options for distributed setups, allowing you to scale horizontally as your data volume increases.
Practical Applications
The reverse video search system we've built has a wide range of potential applications:
- Content Recommendation: Streaming platforms can use this technology to suggest similar content based on a user's viewing history or preferences.
- Copyright Enforcement: Media companies can quickly identify potential copyright infringements by searching for similar video content across various platforms.
- Video Summarization: By identifying key scenes or moments in a video, this system can aid in creating concise video summaries or highlights.
- Educational Tools: Teachers and students can quickly find relevant video segments for educational purposes using natural language queries.
- Forensic Analysis: Law enforcement agencies can use this technology to quickly search through large volumes of video evidence.
- Content Moderation: Social media platforms can automatically flag potentially inappropriate content by comparing uploaded videos against a database of known problematic content.
Resources
Conclusion
Combining Mixpeek's video processing and embedding capabilities with Weaviate's vector search functionality creates a powerful system for reverse video search. This technology bridges the gap between different visual styles and even between text and video, opening up exciting possibilities for multi-modal video analysis and retrieval.
As video content continues to proliferate across the internet, tools like this will become increasingly valuable for managing, analyzing, and deriving insights from vast video repositories. The cross-modal nature of this system, allowing both video and text queries, makes it particularly versatile and suited for a wide range of applications.
Future developments might include:
- Integration with real-time video streams for live content analysis
- Incorporation of audio analysis for even more comprehensive understanding of video content
- Expansion to handle longer-form content like full-length movies or TV episodes
As AI and machine learning technologies continue to advance, we can expect even more sophisticated video understanding and search capabilities to emerge, further revolutionizing how we interact with and derive value from video content.