Multimodal Monday #10: Unified Frameworks, Specialized Efficiency
Multimodal Monday Week 10: Xiaomi's 7B model outperforms GPT-4o, Ming-Omni unifies all modalities with 2.8B params, and specialized efficiency beats raw scale. The AI landscape is shifting fast.

📢 Quick Takes (TL;DR)
- Unified Multimodal Frameworks Accelerate - Ming-Omni joins the rapidly growing field of unified multimodal models, continuing momentum from Qwen2.5-Omni and others. These frameworks are evolving quickly with improved cross-modality integration and reduced computational requirements.
- Specialized Models Outperform Giants - Xiaomi's MiMo-VL-7B models outperform much larger competitors like Qwen2.5-VL-72B and GPT-4o on multiple benchmarks, proving targeted optimization beats raw parameter count.
🧠 Research Highlights
Ming-Omni: Unified Multimodal Model Series
Ming-Omni introduces a unified multimodal model capable of processing images, text, audio, and video with strong generation capabilities. Built on MoE architecture, Ming-lite-omni achieves competitive performance with leading 10B-scale MLLMs while activating only 2.8B parameters.

Why It Matters: Significant advancement in early unified multimodal models that efficiently understand and generate across multiple modalities.
Announcement | GitHub | Project Page
MiMo-VL-7B: Xiaomi's Breakthrough Models
MiMo-VL-7B models deliver state-of-the-art performance in visual understanding and multimodal reasoning. MiMo-VL-7B-RL outperforms Qwen2.5-VL-7B on 35 out of 40 tasks and scores 59.4 on OlympiadBench, surpassing Qwen2.5-VL-72B and GPT-4o.
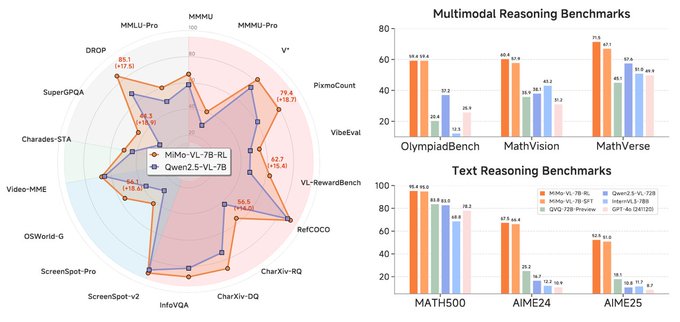
MiMo-VL-7B-RL Benchmarks
Why It Matters: Demonstrates that well-optimized smaller models can outperform much larger ones, potentially democratizing access to high-performance multimodal AI.
ViGoRL: Visual Grounding with Reinforcement Learning
ViGoRL anchors reasoning to image regions through novel reinforcement learning that connects language reasoning with specific visual regions, enabling more precise visual reasoning.
Why It Matters: Creates stronger connections between language and visual elements, addressing a key challenge in ensuring reasoning is properly grounded in visual context.
Additional Research
- Samsung's "Model Already Knows the Best Noise" - Introduces Bayesian Active Noise Selection for improved video diffusion quality. Paper
- SPORT Multimodal Agent - Demonstrates improved reasoning through better visual-textual integration. Project Page
- DARTH - Declarative Recall Through Early Termination for more efficient vector search. Paper
🛠️ Tools & Techniques
Qwen2.5-Omni-3B: Lightweight GPU Accessibility
Qwen2.5-Omni-3B enables 50%+ reduction in VRAM consumption compared to the 7B version. Supports long-context processing (~25k tokens) and 30-second audio-video interactions on consumer GPUs while retaining 90%+ of the 7B model's capabilities.