Understanding Late Interaction Models in Multimodal Retrieval
Late interaction models enable precise retrieval from multimodal data like PDFs and images by comparing query tokens with token or patch embeddings—ideal for RAG, search, and document understanding.

Late interaction models are redefining how we perform retrieval over multimodal data—not just text, but also images, PDFs, scanned documents, and hybrid content. These models retain per-token or per-patch granularity, enabling rich semantic comparisons across modalities.

Why Late Interaction for Multimodal Data?
Dense vector models collapse meaning into a single representation. That works for simple ranking, but falls short when you want to:
🔍 Search a scanned PDF for visual elements
Query:
“Show me pages with line charts illustrating monthly revenue changes.”
Why dense fails:
Dense models collapse visual structure into a single vector, losing spatial context or visual semantics like "line chart."
Why late interaction works:
Multimodal models like ColPaLI or ColQwen retain patch-level embeddings and can directly compare query tokens to image regions.
🔍 Match a table and a caption from a financial report
Query:
“Find all tables labeled as ‘Quarterly Profit Margins’ with accompanying textual explanations.”
Why dense fails:
They can't understand the structured layout nor connect the visual table to its nearby caption semantically.
Why late interaction works:
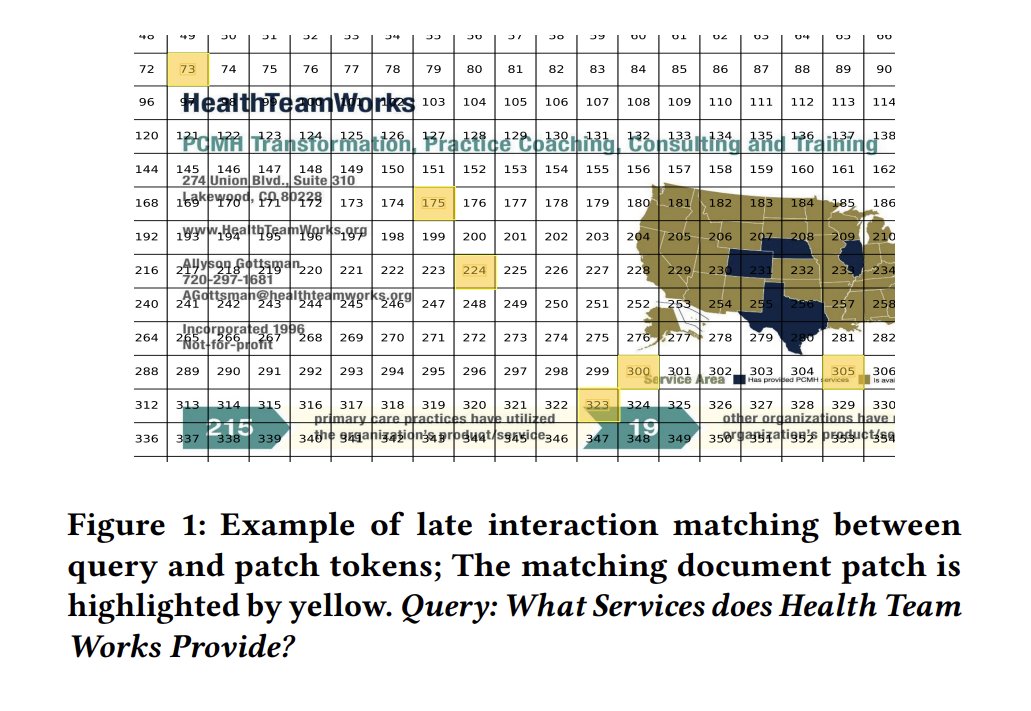
Token-level and patch-level embeddings let models localize the table and contextually associate nearby text via MaxSim.
🔍 Pull relevant sections from a scientific paper with embedded figures
Query:
“Retrieve sections discussing ‘Figure 2’ showing the model’s performance curve.”
Why dense fails:
References to figures and visual content aren’t preserved in a pooled embedding. The link between the text and the figure is lost.
Why late interaction works:
Late interaction models retain localized representations, enabling the system to align the text around “Figure 2” with the image patch it refers to.
Late interaction models enable multi-vector retrieval by retaining subcomponent embeddings—whether they're text tokens or image patches—and using the MaxSim operator to match query tokens to document segments.
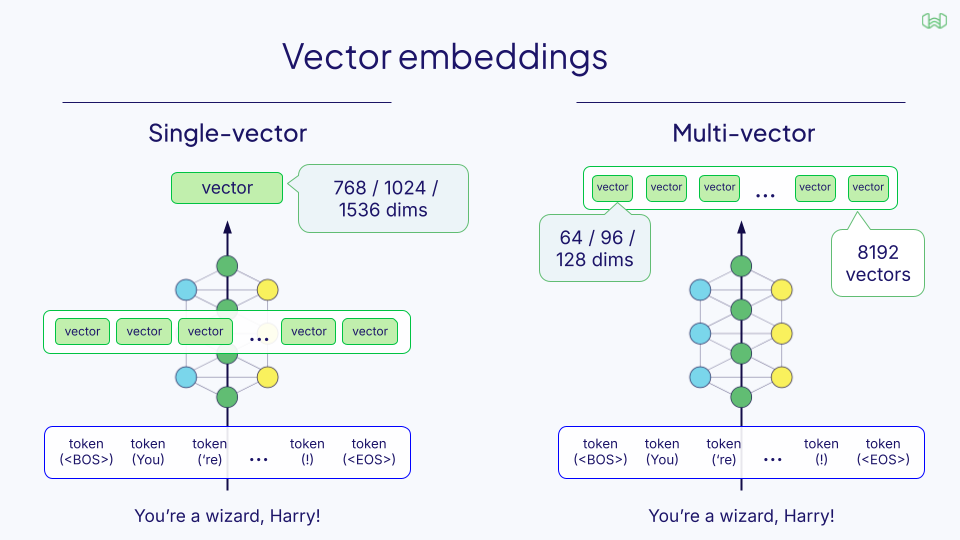
Types of Interaction in Retrieval Models
1. No-Interaction (Bi-Encoder)
- Compresses documents into one dense vector
- Fast, cheap, but discards compositional nuance
- Not suited for documents with structured layout or embedded media
Example: OpenAI's text-embedding-3-small
2. Full-Interaction (Cross-Encoder)
- Jointly encodes query + document with full attention
- High accuracy, especially in structured text
- Infeasible for image-rich, multi-document corpora
Example: MiniLM, BERT cross-encoders
3. Late-Interaction (Multi-vector Models)
- Encodes each token or patch independently
- Stores multi-vector representations (128d, compressed)
- Matches query vectors to doc vectors via MaxSim
- Supports multimodal search across hybrid documents
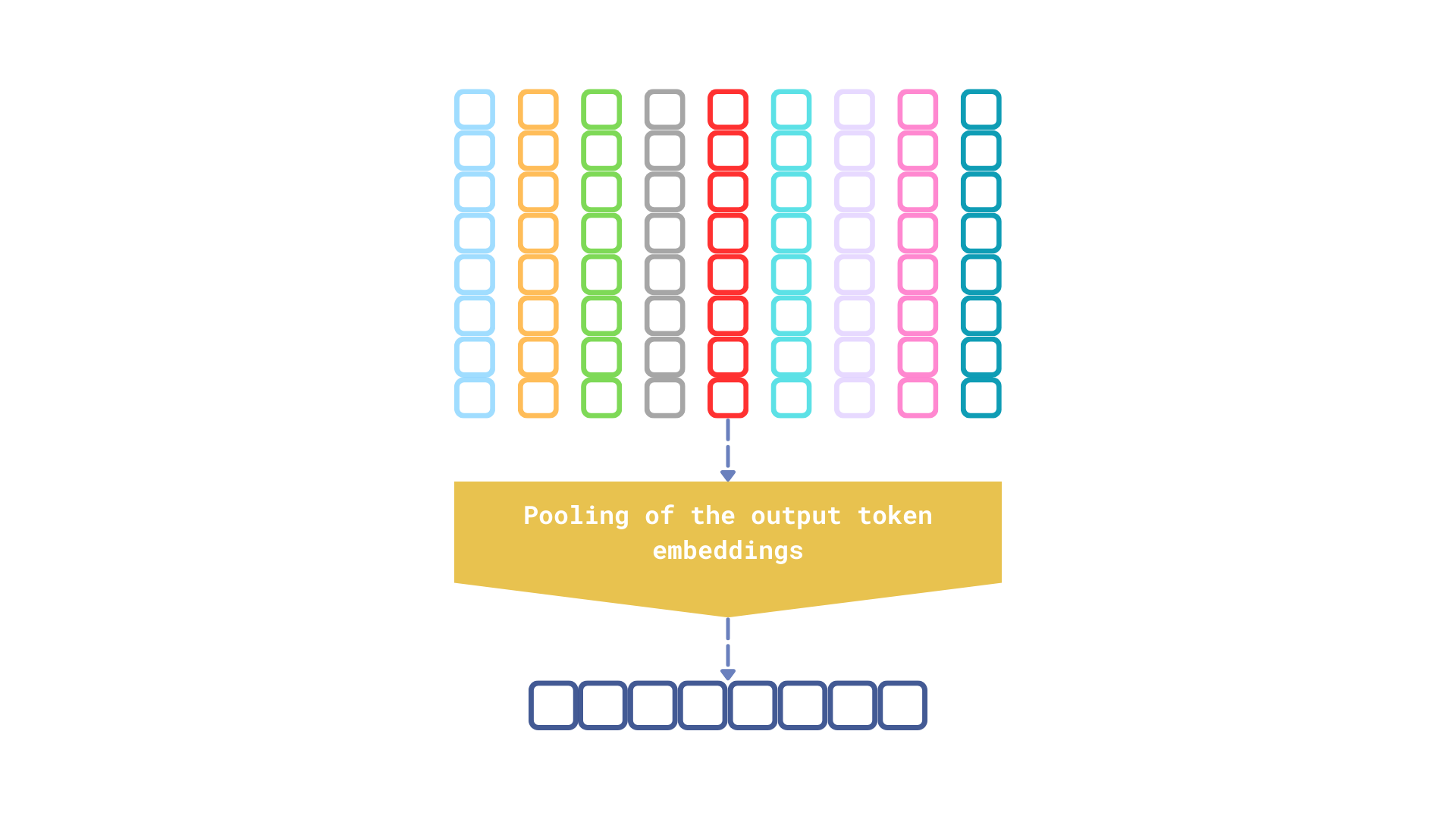
How MaxSim Works in Multimodal Retrieval
Let’s assume we want to search a financial PDF that contains charts, paragraphs, and footnotes.
- Convert the entire document to image
- Divide the image into uniform patches
- Pass patches through a VLM (e.g., PaliGemma, Qwen2-VL)
- Map image patch embeddings into a shared semantic space
- Tokenize the text query and embed it with a language model
- Use MaxSim to compute similarity between query tokens and visual patches

Key Multimodal Late Interaction Models
ColBERT
- Text-only late interaction over BERT
- 128d token vectors, MaxSim scoring
- Commonly used in RAG pipelines
ColPaLI
- ColBERT over PaliGemma
- Treats PDFs and scanned docs as images
- Text queries are embedded with Gemma; image patches via Pali
- Shared vector space enables text-image interaction
ColQwen
- ColBERT over Qwen2-VL
- Smaller patch size (768 max), Apache 2.0 license
- Efficient and permissive alternative to ColPaLI
Tradeoffs
| Model | Modalities | Accuracy | Speed | Storage | Explainability |
|---|---|---|---|---|---|
| Bi-Encoder | Text | ⬆️ | ✅ | ✅ | ❌ |
| Cross-Encoder | Text | ⬆️⬆️ | ❌ | ✅ | ✅ |
| ColBERT | Text | ⬆️⬆️ | ✅ | ❌ | ✅ |
| ColPaLI | Multimodal | ⬆️⬆️ | ✅ | ❌ | ✅ |
Challenges in Multimodal Production Retrieval
- Storage Cost: Each patch/token vector adds up
- Vector Indexing: Most vector DBs aren’t built for multi-vector (e.g., Pinecone, Milvus, Weaviate)
- Inference Scaling: MaxSim requires computing dot products across all patch vectors
- Cross-modal alignment: Requires robust training to unify image+text into one embedding space
Why Mixpeek?
At Mixpeek, we provide a production-grade infrastructure for multimodal late interaction retrieval, purpose-built for teams working with complex content like PDFs, video frames, scanned documents, and more. Specifically, we:
- Embed and index multimodal files (text, images, video, audio) using modular feature extractors, including ColBERT-style late interaction models for fine-grained semantic matching.
- Store and query multi-vector representations (token or patch-level) using an optimized retrieval layer that supports real-time and batch use cases.
- Benchmark and version retrieval pipelines with tools for evaluation, A/B testing, rollbacks, and staged cutovers—so you can safely upgrade from ColBERT to ColPaLI or ColQwen.
- Expose explainability out-of-the-box, showing which tokens or patches triggered a match—making semantic retrieval as transparent as keyword search.
Summary
Late interaction retrieval is not just for text. ColPaLI and ColQwen extend these models into the multimodal realm—powering search over documents, charts, and PDFs with no manual chunking, OCR, or preprocessing. They enable:
- Text-to-image search
- Query-based patch attention
- Deep explainability via MaxSim
Multimodal RAG and semantic search are finally here. Let Mixpeek handle the infrastructure.