Multimodal Monday #17: Real-Time Cognition, Evolving Precision
Multimodal Monday #17: MoVieS creates 4D scenes in 1s, MOSPA tracks audio motion, and ColQwen-Omni unifies search. Real-time understanding expands!

📢 Quick Take (TL;DR)
AI achieves instant 3D scene understanding - MoVieS reconstructs complete 4D scenes from phone videos in just 1 second (down from minutes), while MOSPA makes AI "hear" where sounds come from to predict human movements, like knowing someone's reaching for a door when they hear it creak behind them.
Test-time thinking makes AI 8% smarter without retraining - MindJourney lets vision models "think" about 3D space by mentally rotating objects during inference, boosting spatial reasoning without touching the base model. It's like giving AI a mental sketchpad.
🧠 Research Highlights
MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second
MoVieS reconstructs complete 4D scenes, appearance, geometry, and motion—from regular phone videos in just 1 second, a 100x speedup over previous methods. The system uses pixel-aligned Gaussian primitives to simultaneously track every point's movement, reconstruct 3D structure, and render new viewpoints, all in a single forward pass.
Why It Matters: This speed breakthrough makes real-time 3D content search possible, imagine finding "all moments when the red car turns left" in security footage instantly.
Links: Project Page | Announcement | Video Demo
MOSPA: Spatial Audio-Driven Human Motion Generation
MOSPA generates realistic human movements purely from spatial audio cues, trained on 30K+ seconds of 3D motion data across 27 daily scenarios. The system understands that footsteps behind you make you turn around, while sounds to your left make you look left, capturing the unconscious dance between sound and movement.
Why It Matters: Enables AI to understand and search for human reactions to off-screen events, revolutionizing how we index human behavior in video.
Links: Project Page | Announcement | Paper
MindJourney: Test-Time Scaling with World Models for Spatial Reasoning
MindJourney boosts vision models' spatial reasoning by 8% without any retraining by letting them "imagine" different viewpoints during inference. The system uses video diffusion to mentally rotate objects and explore scenes, gathering multi-view evidence before answering spatial questions, like a human walking around to understand a complex shape.
Why It Matters: Proves we can make existing AI models smarter at deployment time, opening doors for continuous improvement without expensive retraining.
Links: Announcment | Paper
Scaling Laws for Optimal Data Mixtures
Researchers crack the code for predicting optimal training data mixtures using scaling laws, replacing expensive trial-and-error with mathematical precision. Small experiments on 1M parameter models accurately predict the best data mix for 1B+ parameter training, validated across text, vision, and multimodal models.
Why It Matters: Cuts the cost of building specialized AI models by 10x through smarter data selection instead of blind experimentation.
Links: Paper | Announcement
2HandedAfforder: Learning Precise Actionable Bimanual Affordances
2HandedAfforder learns how humans use both hands together on objects from video, creating detailed maps of where to grasp objects for different tasks. The system understands that opening a jar requires gripping the lid with one hand and the base with another, building a dataset of bimanual interactions across common objects.
Why It Matters: Enables search systems to find "how to use this object" by understanding the functional parts, not just object names.
Links: Project Page | Announcement | Paper
Towards Agentic RAG with Deep Reasoning
Survey examining how retrieval-augmented generation systems can perform complex reasoning. Maps current approaches and identifies pathways toward RAG systems that think, not just retrieve.

Pinterest PinFM: Foundation Model for Visual Discovery
Pinterest's foundation model processes billions of user interactions to understand visual preferences at scale. Advances personalization by learning from massive-scale visual discovery patterns.

Links: Paper
VideoITG: Multimodal Video Understanding with Temporal Grounding
Enables precise temporal localization in videos through natural language instructions. Advances video search from "find this video" to "find this exact moment.
Links: Paper
VisionThink: Efficient Vision-Language Model via RL
Uses reinforcement learning to create more efficient vision-language models. Achieves better performance with less computation through smarter training strategies.
Links: Paper
DISSect: Differential Sample Selection for Contrastive Learning
Improves multimodal training by intelligently selecting which samples to learn from. Uses differential information to focus on the most informative training examples.
Links: Paper
🛠️ Tools & Techniques
Mistral AI Voxtral: Frontier Open Source Speech Understanding
Mistral releases Voxtral, bringing GPT-4-level speech understanding to open source. The models excel at transcription, translation, and speech analysis tasks while remaining fully open and customizable for specific applications.
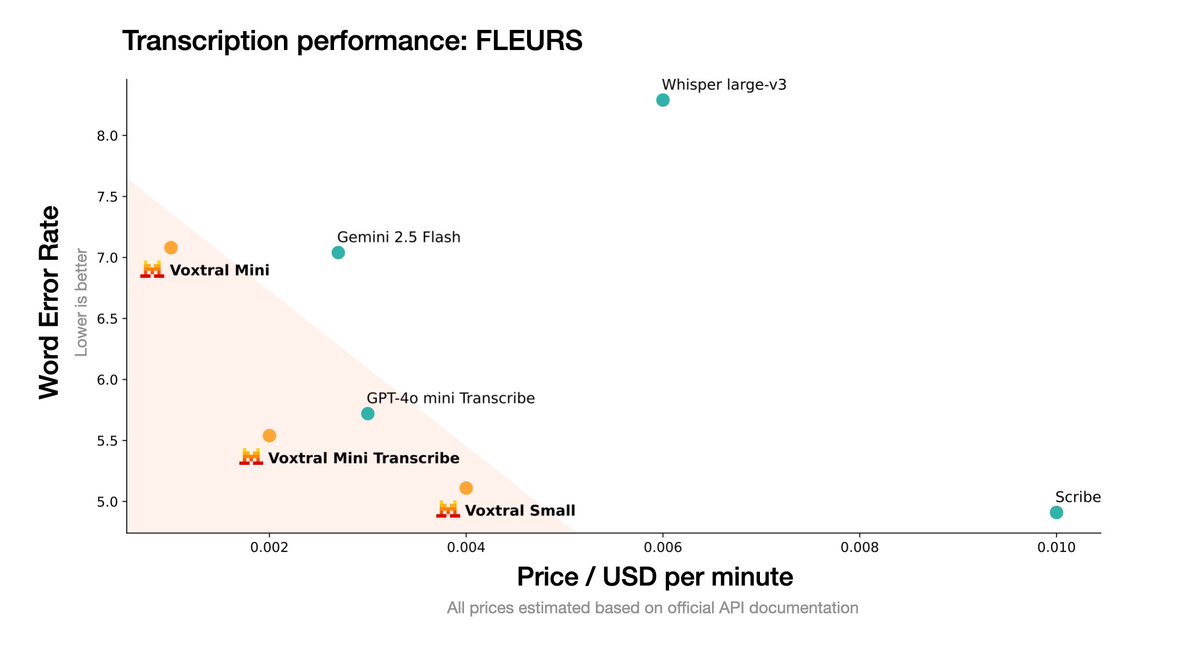
Why It Matters: Democratizes advanced speech AI, enabling anyone to build voice-powered search and analysis systems without vendor lock-in.
Links: Announcement | Mistral AI
Hume AI EVI 3: Enhanced Emotional Voice Interface
EVI 3 detects and responds to emotional nuances in speech with unprecedented accuracy, understanding not just words but feelings. The system recognizes subtle emotional shifts and responds appropriately, creating more natural and empathetic AI interactions.
Why It Matters: Makes content searchable by emotional context—find "frustrated customer calls" or "happy moments" in recordings.
Links: Announcement | Hume AI
ColQwen-Omni: 3B Omnimodal Retriever
ColQwen-Omni extends the ColPali visual document search breakthrough to handle audio chunks and short videos in one unified 3B parameter model. Unlike previous approaches requiring separate models for each media type, it searches everything with consistent quality using late interaction mechanisms.
Why It Matters: First practical universal search model—one system to search documents, podcasts, and videos without switching tools.
Links: Announcement | Article | Model
NVIDIA Canary Qwen 2.5: State-of-the-Art ASR
NVIDIA's Canary Qwen 2.5 tops the Open ASR Leaderboard, setting new records for speech recognition accuracy across languages and accents. The model handles noisy environments, multiple speakers, and technical jargon with exceptional precision.
Why It Matters: Makes every spoken word searchable with near-perfect accuracy, unlocking vast audio archives for analysis.
Links: Model
MirageLSD: The First Live-Stream Diffusion AI
Decart's MirageLSD generates and modifies visual content during live streams in real-time, responding instantly to viewer inputs. This breakthrough enables dynamic visual effects, real-time scene changes, and interactive content creation without pre-rendering.
Why It Matters: Transforms live content from static broadcasts to dynamic, searchable, interactive experiences generated on-the-fly.
Links: Announcement | Decart
📈 Trends & Predictions
AI Achieves Instant 3D Scene Understanding
MoVieS's 1-second 4D reconstruction represents more than a speed improvement, it's a fundamental shift in how AI perceives the world. Previous systems took minutes to build 3D understanding; now it happens faster than human perception. This isn't just about processing videos quickly; it's about AI finally understanding space and motion at the speed of thought. Combined with MOSPA's spatial audio awareness, we're seeing AI develop genuine spatial intelligence that rivals human environmental understanding.
The implications cascade across industries. Security systems will track complex events in real-time, understanding not just that someone entered a room, but how they moved, what they interacted with, and their behavioral patterns. Content creators will search footage by spatial relationships: "find when the camera circles the product" or "moments where people gather in groups." By 2026, expect every video platform to offer 4D-aware search, making spatial relationships as searchable as keywords are today. The companies ignoring this shift will find their 2D-only systems obsolete overnight.
Test-Time Intelligence Amplification
MindJourney's 8% performance boost through test-time thinking reveals a profound truth: we can make AI smarter without retraining. This "mental rotation" approach, letting models explore different perspectives during inference, mirrors how humans solve complex problems. It's not about bigger models or more data; it's about thinking smarter at deployment time. This paradigm shift means AI systems can continuously improve after deployment, adapting to new challenges without expensive retraining cycles.
The economic implications are staggering. Companies spending millions on retraining will pivot to test-time enhancement, achieving similar gains at 1/100th the cost. Every deployed model becomes upgradeable through software updates rather than full replacements. Search systems will dynamically adjust their intelligence based on query complexity, using more "thinking" for hard problems and staying efficient for simple lookups. By 2026, test-time scaling will be standard practice, with models shipping with "intelligence sliders" users can adjust based on their needs. The future isn't bigger models, it's smarter thinking.
That's a wrap for Multimodal Monday #17! This week proved that multimodal AI is breaking through fundamental barriers, from instant 3D understanding to universal search across all media types. The convergence of speed, spatial awareness, and unified architectures shows we're entering an era where AI truly understands our multimedia world.
Ready to build multimodal solutions that actually work? Let's talk