Multimodal Monday #18: Real-Time Vision, Evolving Minds
Multimodal Monday #18: MoVieS rebuilds 4D in 1s, MindJourney boosts reasoning by 8%, and MOSPA predicts audio motion. Spatial intelligence takes off!

📢 Quick Take (TL;DR)
The $1 trillion question gets answered - Step-3 cracks the code on affordable AI at scale, running 321B parameters while only activating 38B per token, matching GPT-4o performance at a fraction of the cost through clever hardware tricks that make CFOs smile and engineers jealous.
Reality check: Video AI still thinks like a toddler - New benchmark Video-TT exposes an uncomfortable truth: even GPT-4o scores just 36% on understanding YouTube Shorts compared to humans' 64%, revealing that our "smart" video models are still missing obvious visual cues your five-year-old would catch.
Audio AI learns to read the room - Step-Audio 2 doesn't just transcribe words, it detects sarcasm, emotion, and speaking style while integrating web search and voice switching, marking the shift from "what you said" to "how you meant it" in audio understanding.
🧠 Research Highlights
Step-3: Large yet Affordable Model-system Co-design for Cost-effective Decoding
Step-3 achieves 321B parameters with only 38B active per token through Multi-Matrix Factorization Attention (MFA) and Attention-FFN Disaggregation (AFD), delivering 4,039 tokens/second/GPU compared to DeepSeek-V3's 2,324. The model matches GPT-4o and Claude Opus 4 performance while dramatically reducing computational costs through hardware-aware design.
Why It Matters: This breakthrough makes enterprise-scale multimodal AI economically viable, enabling companies to process massive content libraries without breaking the bank on compute costs.
A Survey of Multimodal Hallucination Evaluation and Detection
This 33-page survey systematically categorizes hallucination types in Image-to-Text and Text-to-Image generation, covering evaluation benchmarks and instance-level detection methods. The research provides a comprehensive taxonomy based on faithfulness and factuality, establishing standardized approaches for identifying when AI makes things up.
Why It Matters: Essential reading for anyone building production multimodal systems, hallucination detection is the difference between a trusted search engine and a creative fiction generator.
Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning
Video-TT benchmarks 1,000 YouTube Shorts with 5,000 questions, revealing that top models like GPT-4o achieve only 36% accuracy versus humans' 64.4%. The test distinguishes between frame sampling issues and genuine comprehension gaps using adversarial questions that probe visual and narrative understanding.
Why It Matters: Shows we're still far from human-level video understanding, critical insight for anyone building video search or analysis systems.
Links: Project Page | Announcement | ICCV 2025
Step-Audio 2: End-to-End Multi-Modal Large Language Model for Audio Understanding
Step-Audio 2 combines latent audio encoding with reasoning-centric reinforcement learning to understand paralinguistic information like emotion and speaking style. The model generates discrete audio tokens, integrates RAG, and calls external tools including web search and voice switching.
Why It Matters: Transforms audio from simple transcription to full emotional and contextual understanding, big for podcast search and voice interfaces.
Links: Paper | Announcement | StepFun
Diffuman4D: 4D Consistent Human View Synthesis from Sparse-View Videos
Creates temporally consistent human animations from limited camera angles using spatio-temporal diffusion models. The system generates realistic motion and appearance across multiple viewpoints and time steps.
Why It Matters: Enables creation of full 3D human motion from just a few camera angles, crucial for virtual production and AR applications.
Links: Paper | Project Page
AURA: A Multi-Modal Medical Agent for Understanding, Reasoning & Annotation
AURA combines medical image analysis with clinical reasoning for healthcare applications. The agent handles complex medical annotation tasks while providing interpretable decision support.
Why It Matters: Bridges the gap between raw medical imaging and actionable clinical insights with explainable AI.
Links: Paper
MoDA: Multi-Modal Diffusion Architecture for Talking Head Generation
Generates realistic talking heads by synchronizing facial animation with speech using multi-modal diffusion. The architecture ensures natural lip-sync and facial expressions from audio input.
Why It Matters: Makes creating realistic digital avatars as easy as providing audio, transforming video production and virtual meetings.
Links: Paper
ByteDance RankMixer: Scaling Up Ranking Models in Industrial Recommenders
RankMixer scales recommendation systems for industrial multimodal content ranking. The framework handles billions of items while maintaining recommendation quality and response time.
Why It Matters: Shows how to make TikTok-scale recommendations work in practice, essential for anyone building content discovery systems.
Links: Paper
True Multimodal In-Context Learning Needs Attention to the Visual Context
Demonstrates that multimodal in-context learning fails without proper visual attention mechanisms. The research provides architectural insights for improving cross-modal understanding.
Why It Matters: Explains why many multimodal models ignore images in prompts, and how to fix it.
Links: Paper
LMM-Det: Make Large Multimodal Models Excel in Object Detection
Enhances large multimodal models for object detection without sacrificing general capabilities. The method bridges specialized computer vision and general multimodal understanding.
Why It Matters: Finally makes general-purpose multimodal models competitive with specialized detectors.
Links: Paper
🛠️ Tools & Techniques
InternLM Intern-S1: 235B MoE with 128 Experts
Intern-S1 packs 235B parameters into a Mixture of Experts architecture with 128 specialists, activating just 8 per token. This sparse activation enables efficient processing of diverse content types without the computational overhead of dense models.
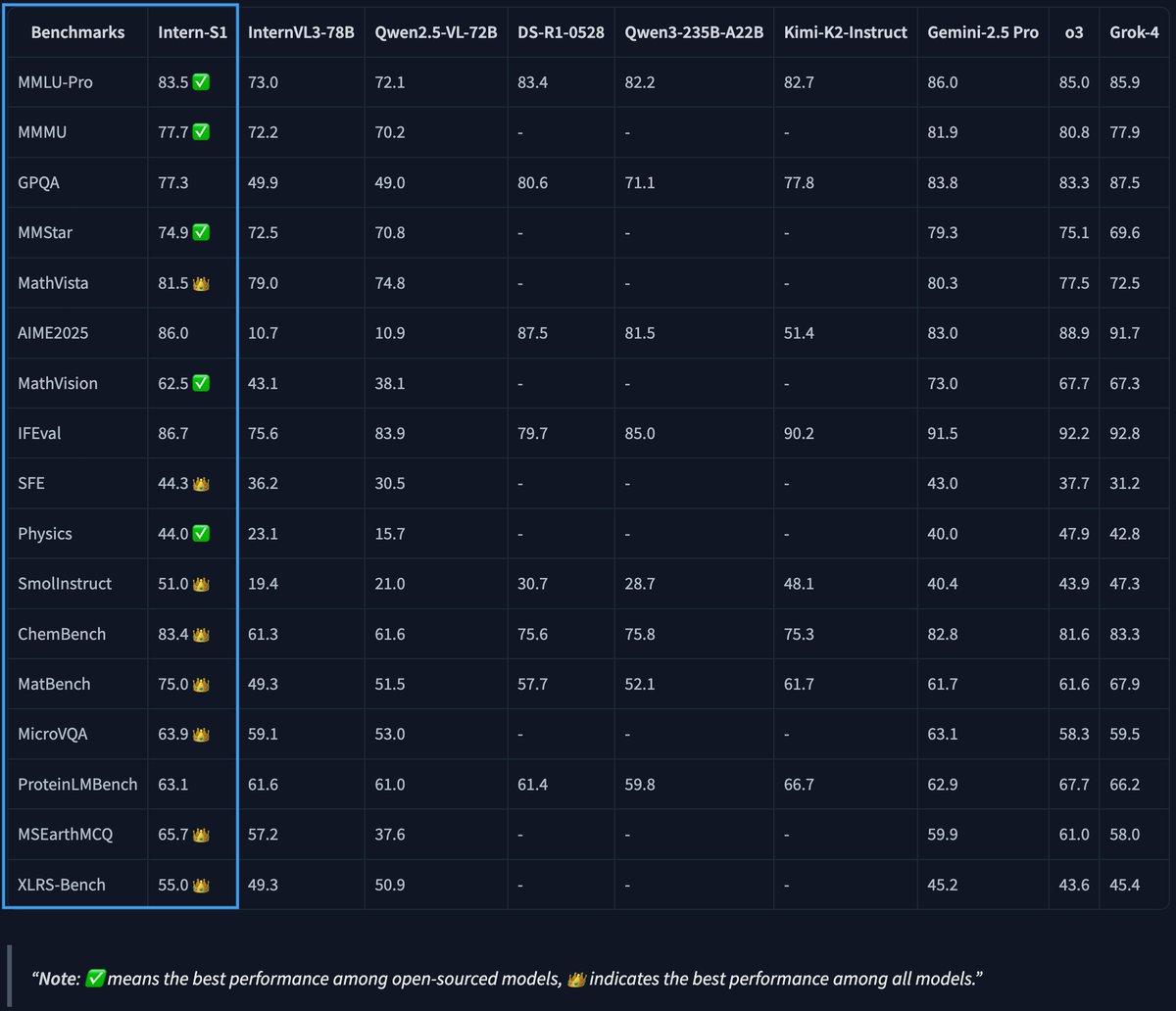
Why It Matters: Shows how to build Google-scale multimodal systems that don't require Google-scale infrastructure.
TimeScope: How Long Can Your Video Large Multimodal Model Go?
TimeScope benchmarks video models on temporal understanding from short clips to extended sequences. The evaluation reveals how models lose coherence over longer videos and struggle with temporal relationships.
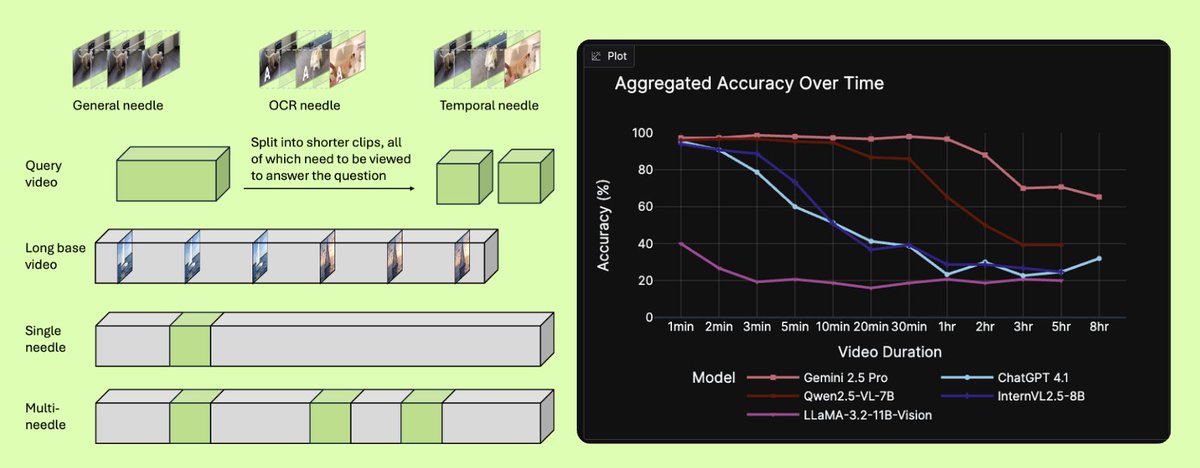
Why It Matters: Essential benchmark for anyone building video search, most models can't handle anything longer than a TikTok.
Links: Blog | HuggingFace
Tencent Hunyuan3D World Model 1.0: Generate Immersive 3D Worlds
Creates explorable 3D environments from single sentences or images, generating interactive worlds with consistent geometry and textures. The model handles complex spatial relationships and object interactions in generated scenes.
Why It Matters: Text-to-3D world generation opens entirely new content categories that will need novel search and indexing approaches.
Links: Announcement | Tencent Hunyuan
FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
FLOAT animates portraits using generative motion flow matching, creating realistic facial movements from audio. The system maintains temporal consistency while capturing subtle expressions and lip-sync.
Why It Matters: Makes anyone a virtual presenter, transforming how we think about video content creation and authenticity.
Links: Project Page | GitHub | DeepBrain AI
Google Gemini Conversational Image Segmentation
Gemini 2.5 now segments images through natural conversation, turning complex pixel-level tasks into simple chat. Users describe what to segment in plain language and receive precise masks instantly.

Why It Matters: Makes advanced computer vision as easy as asking a question, democratizing precise visual analysis.
Links: Announcement | Google Blog | Google Gemini
RF-DETR: Next-Generation Object Detection Models
RF-DETR-Nano beats YOLO11-n by 11 mAP points while running faster, and RF-DETR-Small outperforms YOLO11-x with 7.77ms speed improvement. The models achieve state-of-the-art detection with practical deployment speeds.
Why It Matters: Finally dethroned YOLO's speed-accuracy trade-off, new king of real-time object detection.
Links: Announcement | GitHub | Demo
📈 Trends & Predictions
The Humbling Truth About Video Understanding
Video-TT's revelation that our best models achieve just 36% accuracy on YouTube Shorts (versus 64% for humans) should be a wake-up call for the industry. We've been so focused on benchmark climbing that we missed a fundamental truth: video understanding isn't just about processing frames, it's about grasping narrative, context, and the subtle visual cues that humans parse effortlessly.
This gap isn't a bug; it's a feature of our current approach. The models that power today's video search and analysis systems are essentially sophisticated pattern matchers that miss the forest for the trees. As Video-TT shows, they fail on adversarial questions that probe real understanding. For the multimodal search industry, this means we need to fundamentally rethink how we approach video content. The next breakthrough won't come from bigger models but from architectures that truly understand temporal narrative and visual storytelling.
Audio's Emotional Revolution
Step-Audio 2's ability to understand not just what is said but how it's said represents a seismic shift in audio processing. By capturing emotion, sarcasm, and speaking style while integrating external knowledge through RAG, audio AI is finally growing up. This isn't just better transcription, it's the difference between reading sheet music and feeling the performance.
The integration of paralinguistic understanding with external tool calling creates possibilities we're only beginning to imagine. Podcast search that finds not just topics but moods. Customer service analysis that detects frustration before it escalates. Educational content that adapts to student engagement levels in real-time. When audio AI can read the room as well as read the words, every audio interaction becomes rich with searchable, actionable intelligence. The companies that capitalize on this emotional dimension of audio will build the next generation of voice interfaces and audio analytics platforms.
🧩 Community + Shoutouts
Demo of the Week: Meta EMG Hardware and Models
Meta unveils EMG technology that translates wrist muscle signals into computer commands, published in Nature. The system combines custom hardware with ML models to enable direct neural control of interfaces. Users control computers through natural muscle movements, opening new paradigms for human-computer interaction beyond traditional input devices.
Links: Announcement | GitHub | Nature Paper |
That's a wrap for Multimodal Monday #18! This week proved that the future of multimodal AI isn't about raw power, it's about efficiency, understanding, and emotional intelligence. From Step-3's cost breakthrough to Video-TT's reality check to Step-Audio 2's emotional awareness, we're seeing the industry mature from impressive demos to practical deployments.
Ready to build multimodal solutions that actually work? Let's talk