Multimodal Monday #26: Adaptive Retrieval, Visual Reasoning
Multimodal Monday #26: MetaEmbed scales retrieval on-the-fly, EmbeddingGemma beats giants with 308M params, and Veo3 develops reasoning.

📢 Quick Take
Test-time scaling arrives for retrieval - Meta's MetaEmbed lets you dial retrieval precision up or down on the fly. Running on a phone? Use fewer vectors. Need perfect accuracy? Crank it up. No retraining required.
Small models beat giants - Google's EmbeddingGemma proves 308M parameters can outperform models twice its size. It runs on 200MB of RAM and generates embeddings in 22ms on EdgeTPU. The era of bloated models is ending.
Video models develop visual reasoning - Google's Veo3 spontaneously learned to solve mazes and recognize symmetry without training for these tasks. Video models are following the same path as LLMs, from single-purpose tools to general intelligence.
🧠 Research Highlights
MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Meta built MetaEmbed to solve retrieval's biggest problem: you either get fast but dumb (single vectors) or smart but slow (hundreds of embeddings). MetaEmbed uses learnable "Meta Tokens" that create hierarchical embeddings you can adjust at runtime, use 1 vector for speed or 32 for accuracy, all from the same model.

Why It Matters: You can finally deploy one retrieval model everywhere, from phones to data centers, and tune performance based on available compute.
Links: Paper
Google DeepMind EmbeddingGemma: Powerful and Lightweight Text Representations
Google squeezed state-of-the-art embedding performance into 308 million parameters through clever training: they distilled knowledge from Gemini, adapted Gemma 3 into an encoder, and added regularization for robustness. The model handles 100+ languages and runs on less than 200MB RAM with quantization.

Why It Matters: High-quality embeddings now work on devices where traditional models won't even load.
Links: Paper | Documentation
Google Veo3: Video Models are Zero-Shot Learners and Reasoners
Veo3 developed unexpected capabilities without explicit training: it segments objects, detects edges, edits images, understands physics, and even solves mazes. The model learned general visual understanding from simple video generation training, mirroring how LLMs developed language understanding.

Why It Matters: Video models are becoming general-purpose vision systems that understand and reason about the world, not just generate clips.
Links: Paper | Project Page
WorldExplorer: Towards Generating Fully Navigable 3D Scenes
TU Munich researchers fixed 3D generation's biggest flaw: scenes that fall apart when you move the camera. WorldExplorer generates multiple video trajectories that explore scenes deeply, then fuses them into consistent 3D Gaussian Splatting representations you can navigate freely.
Why It Matters: You can now generate 3D environments from text that remain stable no matter where you move the camera.
Links: Paper | Project Page | GitHub
NVIDIA Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
NVIDIA's Lyra extracts the 3D knowledge hidden in video diffusion models without needing multi-view training data. The system trains a 3D Gaussian Splatting decoder using only synthetic data from video models, enabling real-time 3D scene generation from text prompts or single images.
Why It Matters: You can create 3D scenes without expensive multi-view capture setups, just use what video models already know.
Links: Paper | Project Page | GitHub
HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos teaches robots complex interactions directly from YouTube videos without manual reward engineering.
Links: Twitter | Paper | Project Page | GitHub
VideoFrom3D: 3D Scene Video Generation via Complementary Image and Video Diffusion Models generates dynamic videos from static 3D scenes using complementary diffusion models.
Links: Paper | Project Page | GitHub
Alibaba GeoPQA: MLLMs learn to see, then reason fixes geometry failures with 2-stage RL that first improves visual perception, then reasoning, boosting accuracy 9.1%.
Links: Dataset | Paper
RecIS: Sparse to Dense, A Unified Training Framework for Recommendation Models bridges TensorFlow's sparse modeling with PyTorch's multimodal capabilities for recommendation systems.
Links: Paper | GitHub
🛠️ Tools & Techniques
ByteDance Lynx: High-Fidelity Personalized Video Synthesis
ByteDance's Lynx generates personalized videos from a single photo using two lightweight adapters on a DiT foundation. The ID-adapter compresses facial embeddings into identity tokens while the Ref-adapter injects fine details across all transformer layers, achieving 0.779 face resemblance versus competitors' 0.575-0.715.
Why It Matters: You can create identity-consistent videos from one photo that actually look like the person.
Links: Project Page | GitHub
Alibaba Qwen3-LiveTranslate-Flash: Real-Time Multimodal Interpretation
Qwen3-LiveTranslate-Flash achieves 3-second translation latency while reading lips, gestures, and on-screen text across 18 languages. The system uses lightweight mixture-of-experts with dynamic sampling to maintain 94% of offline translation accuracy in real-time.
Why It Matters: Real-time translation that sees context beats audio-only systems in noisy environments.
Links: Blog Post | Documentation | Demo
Alibaba Qwen3-Omni: First Natively End-to-End Omni-Modal AI
Qwen3-Omni unifies text, image, audio, and video processing in one model without modality trade-offs. The native end-to-end architecture eliminates the need for separate specialized models, letting each modality enhance the others.
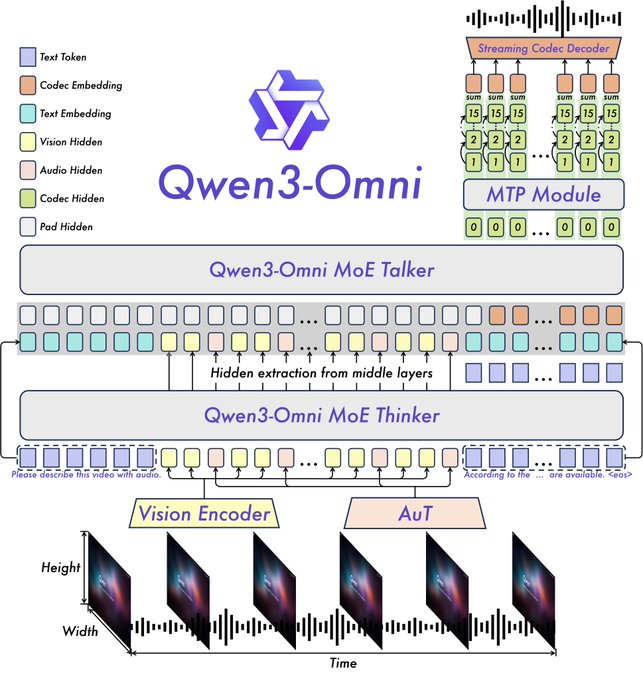
Why It Matters: One model handles all modalities equally well—no more juggling specialized systems.
Links: Twitter | GitHub | Demo | Models
Google Gemini Robotics-ER 1.5: SOTA on Embodied Reasoning Tasks
Google's Gemini Robotics-ER 1.5 sets new benchmarks for embodied reasoning, understanding spatial relationships and physical interactions in real environments. The model works through standard Gemini APIs, making advanced robotics capabilities accessible to developers.
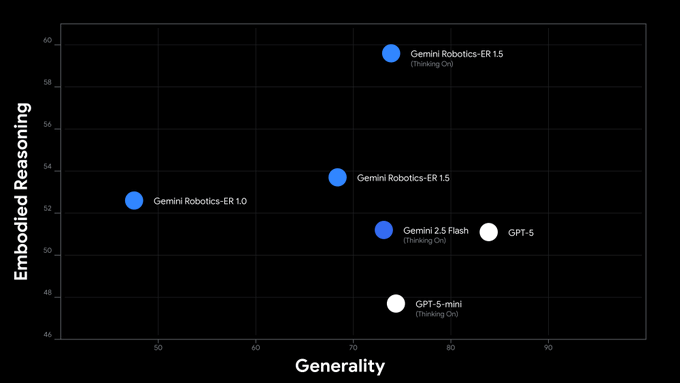
Why It Matters: Physical AI that understands space and objects is now available through simple API calls.
Links: Twitter | Blog Post
Tencent Hunyuan3D-Part: Part-Level 3D Shape Generation Model
Tencent's Hunyuan3D-Part generates 3D objects at the part level, letting users modify individual components rather than whole objects. The system includes P3-SAM for native 3D part segmentation and X-Part for state-of-the-art generation quality.
Why It Matters: You can now edit the handle of a mug without regenerating the entire object.
Links: Twitter | GitHub | HuggingFace | Paper 1 | Paper 2
ByteDance OmniInsert seamlessly inserts subjects from any video or image into scenes without masks.
Links: Paper | Project Page
Alibaba Qwen-Image-Edit-2509 supports multi-image editing combinations like "person + product" with enhanced consistency and native ControlNet support.
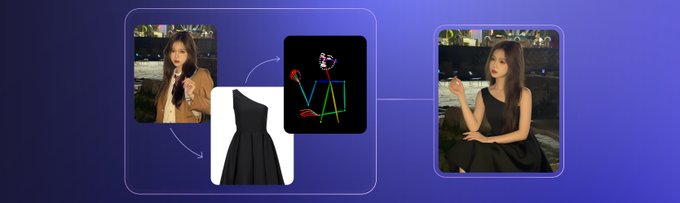
Links: Blog Post | GitHub | HuggingFace
Alibaba Qwen3-VL operates GUIs, codes Draw.io charts from mockups, and recognizes specialized visual content.
Links: Twitter
Alibaba Qwen3 Guard provides generative and streaming content safety models with low-latency detection.
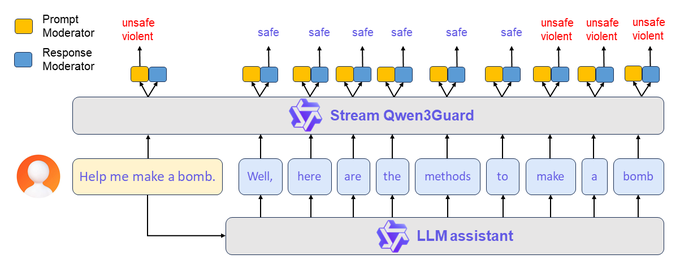
Links: Twitter | Technical Report | Models
Meta Vibes uses Midjourney to power AI video creation with editing, relighting, restyling, and music features.
Links: Announcement
Baidu Qianfan-VL delivers enterprise-grade vision-language models with strong OCR and math capabilities. Links: Twitter | GitHub | Website | Models
Google Mixboard helps explore and visualize ideas using Google's latest image generation models.
📈 Trends & Predictions
Small Models Win
The success of Google's EmbeddingGemma in achieving state-of-the-art performance with only 308M parameters signals a broader trend toward efficiency-optimized multimodal models. This development challenges the assumption that better performance requires exponentially larger models, instead demonstrating that sophisticated training techniques and architectural innovations can deliver superior results with dramatically reduced computational overhead.
Companies no longer need massive infrastructure for basic multimodal capabilities. Startups can compete with tech giants using models that run on commodity hardware. The cost barrier to AI adoption just collapsed.
Video Models Becoming Generally Intelligent
Veo3's emergent reasoning abilities signal something profound. Video models trained on simple generation tasks spontaneously develop visual understanding and reasoning. These models don't just generate videos anymore. They are starting to understand physics, solve puzzles, recognize patterns. They reason about what they see. This wasn't programmed, it emerged from scale and data. The same way GPT learned to understand language.
🧩 Community + Shoutouts
🛠️ Builder Spotlight Shoutout to anandmaj for tinyWorlds, a 3M parameter world model capable of generating playable game environments, demonstrating efficient world modeling with minimal parameters for interactive gaming applications.
Links: GitHub
Shoutout to Amir and the HuggingFace team for releasing Smol2Operator, a full open-source recipe for turning a 2.2B model into an agentic GUI coder, providing all the tools needed to build custom agentic coding systems.
That's a wrap on this week's multimodal developments! From test-time scaling breakthroughs to explorable 3D generation and real-time multimodal interpretation, we're witnessing the maturation of truly adaptive and interactive multimodal AI systems.
Ready to build multimodal solutions that actually work? Let's talk.