Multimodal Monday #28: Diffusion Thinks, Retrieval Unifies
Multimodal Monday #28: Fast-dLLM v2 diffuses text 2.5x faster, Omni-Embed-Nemotron hunts across modalities, and Think-Then-Embed reasons to top MMEB-V2.

Week of October 6-12, 2025
📢 Quick Takes (TL;DR)
Unified multimodal retrieval advances - Nvidia's Omni-Embed-Nemotron extends retrieval embeddings to handle text, images, audio, and video in a single architecture, building on recent work like ColPali and inspired by models like
Diffusion models branch beyond images - RND1 applies diffusion to text generation. Fast-dLLM v2 converts autoregressive models to parallel generation. DiffusionNFT makes reinforcement learning work with diffusion. The technique generalizes.
Models start explaining their thinking - Think-Then-Embed generates reasoning traces before embeddings. Hunyuan-Vision-1.5-Thinking processes visual info through structured reasoning steps. Chunkr-parse-1-thinking understands document context beyond text extraction. Explanation improves accuracy.
🧠 Research Highlights
Nvidia Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video
Nvidia built a single model that searches across text, images, audio, and video simultaneously. Unlike current systems that handle each media type separately, Omni-Embed-Nemotron performs both cross-modal searches (finding videos from text queries) and joint-modal searches (combining text and audio to find relevant content).

Link: Paper
Meta SSDD: Single-Step Diffusion Decoder for Efficient Image Tokenization
Meta created SSDD, a new image tokenizer that processes images in one step instead of multiple iterations. The system achieves better image quality (FID improves from 0.87 to 0.50) while running 3.8x faster than current methods, all without needing adversarial training.

Link: Paper
Nvidia Fast-dLLM v2: Efficient Block-Diffusion LLM
Nvidia's Fast-dLLM v2 converts standard language models into parallel text generators using only 1 billion training tokens (500x less than competitors). The system generates text 2.5x faster than regular models while maintaining the same quality, reaching 217.5 tokens per second at batch size 4.
Links: Paper | Project Page
Character Mixing for Video Generation
Researchers developed a system that places characters from different worlds into the same video while preserving their unique styles. The framework uses Cross-Character Embedding to learn character behaviors and Cross-Character Augmentation to create synthetic training data, enabling Mr. Bean to interact naturally in Tom & Jerry's cartoon world.
Links: Announcement | Project Page | GitHub | Paper
Think Then Embed: Generative Context Improves Multimodal Embedding
Think-Then-Embed makes models reason through complex queries before creating embeddings. The two-stage approach first generates reasoning traces that explain the query, then produces embeddings based on both the original query and the reasoning, achieving state-of-the-art results on MMEB-V2 benchmark.

Link: Paper
Token Perception for Multimodal Reinforcement Learning enhances agent understanding across different modalities through token-based perception mechanisms.
Link: Paper
Vision Language Models: A Survey of 26K Papers analyzes 26,000 VLM papers, revealing the field's shift toward multimodal LLMs and generative methods.
Link: Paper
DiffusionNFT: Online Diffusion Reinforcement with Forward Process makes reinforcement learning practical for diffusion models by working directly on the forward process.
Links: Paper | GitHub
ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation treats image editing as video generation to maintain physical consistency.
Links: Announcement | Project Page | Paper
RLAD: Reasoning Abstractions for Decision Making teaches models to learn textual strategies that guide exploration in decision-making tasks.
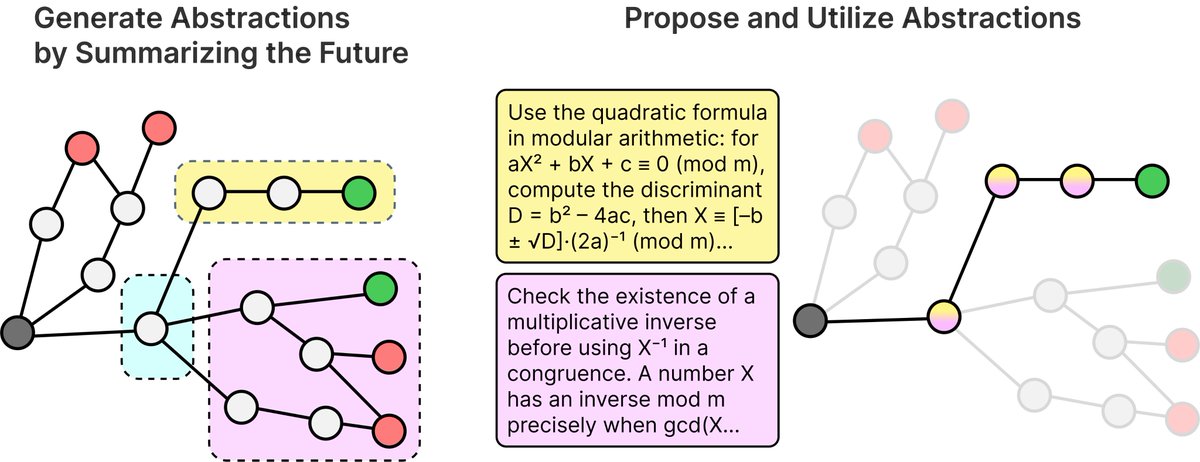
Links: Announcement | Paper | Project Page
VLM-Lens: Interpreting Vision-Language Models provides tools for analyzing vision-language models at any layer with YAML configuration.

Links: Announcement | GitHub | Paper
NaViL: Rethinking Scaling Properties of Native Multimodal Large Language Models under Data Constraints shows how to scale multimodal LLMs when training data is limited.
Link: Paper
🛠️ Tools & Techniques
StreamDiffusionV2: Real-Time Interactive Video Generation
StreamDiffusionV2 generates live video at 42 FPS on 4 H100 GPUs and 16.6 FPS on 2 RTX 4090s. The system uses StreamVAE to compress 4 video frames into one latent frame, synced rolling KV cache for style consistency, and motion-aware noise control that adapts to how fast things move in your video.
Links: Announcement | Project Page | GitHub
Tencent Hunyuan-Vision-1.5-Thinking
Tencent released their latest vision-language model, ranked #3 on LM Arena. The model processes visual information through structured reasoning steps before generating responses, handling complex visual understanding tasks that require multi-step thinking.
Links: Announcement | Github
chunkr-parse-1 and chunkr-parse-1-thinking VLMs
Chunkr built VLMs specifically for parsing documents with complex layouts, tables, and formulas in over 100 languages. The models outperform AWS Textract, Gemini 2.5 Pro, and Mistral at OCR tasks, with the "thinking" variant understanding document context beyond just text extraction.
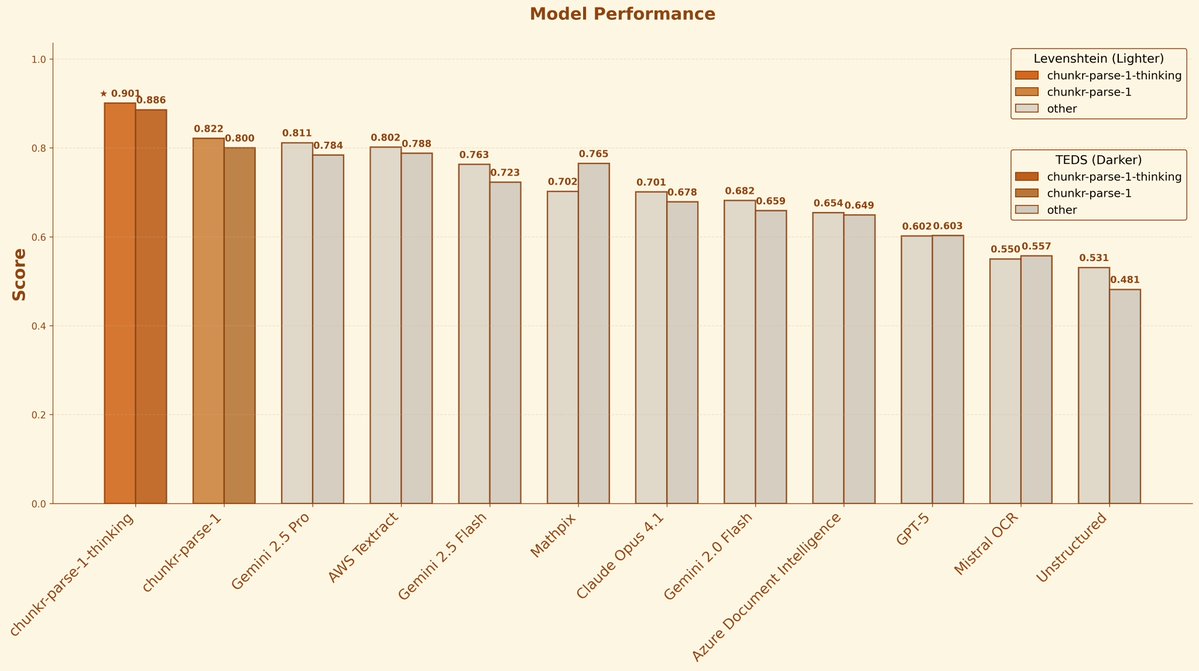
Links: Annoucement | Website | Blog Post
Paris: Decentralized Trained Open-Weight Diffusion Model
Paris is the first diffusion model trained across multiple nodes without centralized control. The decentralized approach distributes computational resources while keeping the model weights open for anyone to use.

Links: Annoucement | Paper | HuggingFace
RND1: Powerful Base Diffusion Language Model
Radical Numerics launched RND1, their base diffusion language model that generates text through diffusion processes instead of traditional sequential generation. The model offers parallel text generation with improved controllability.
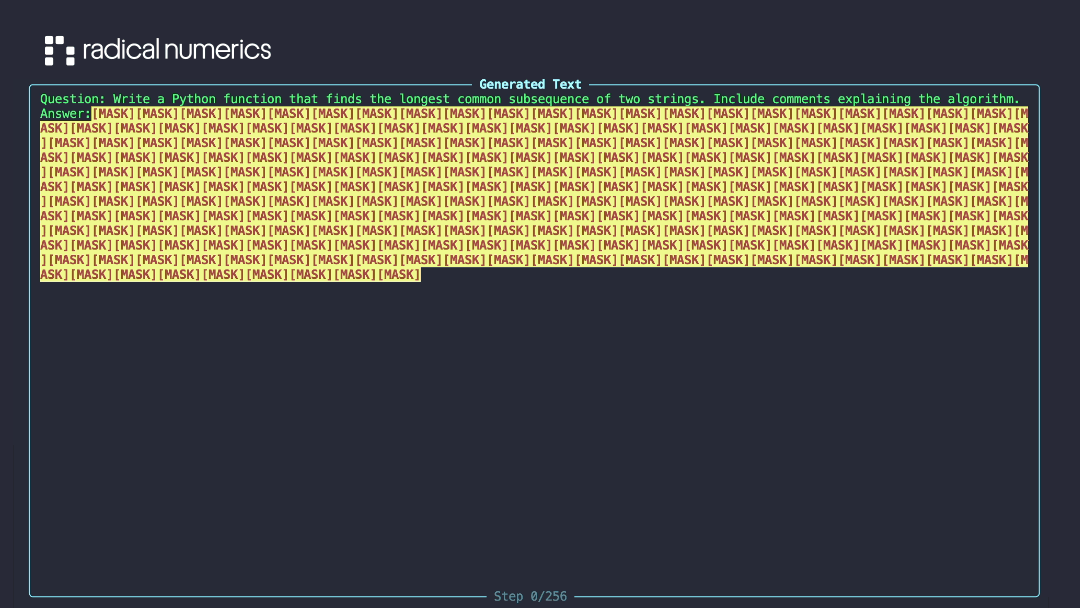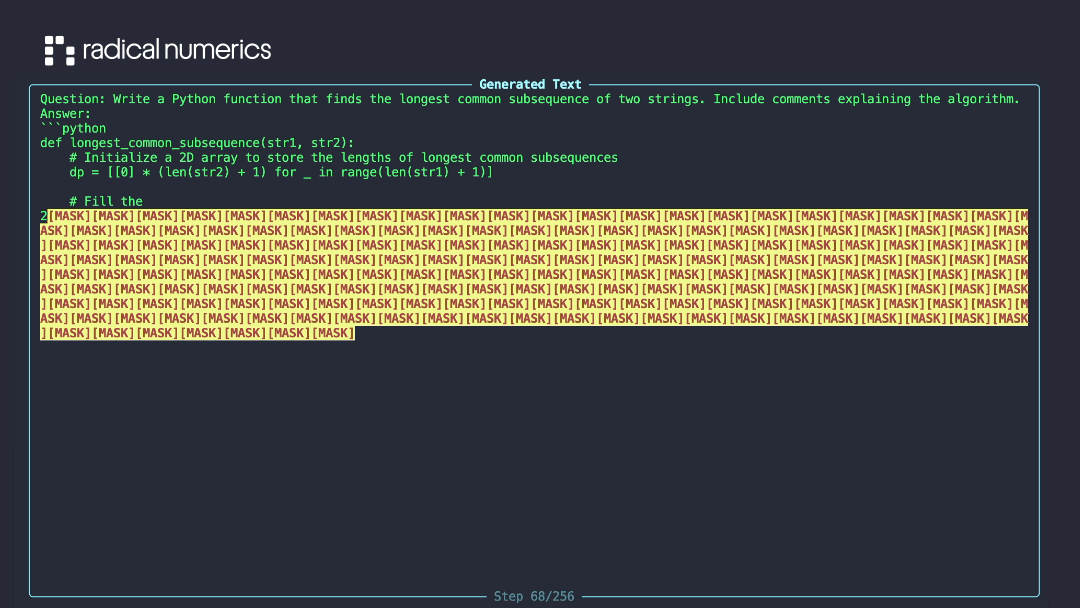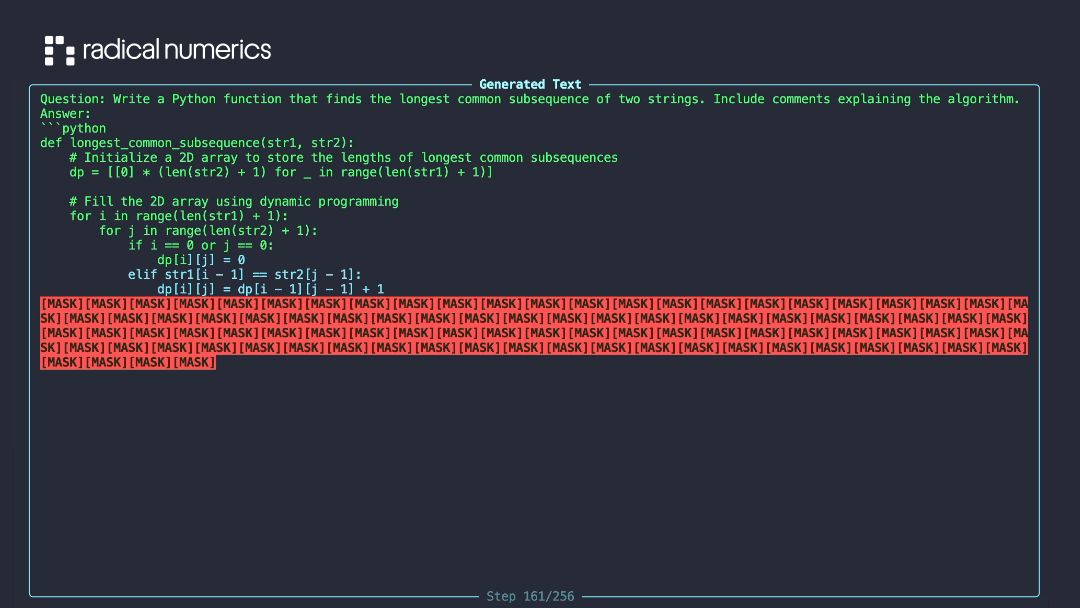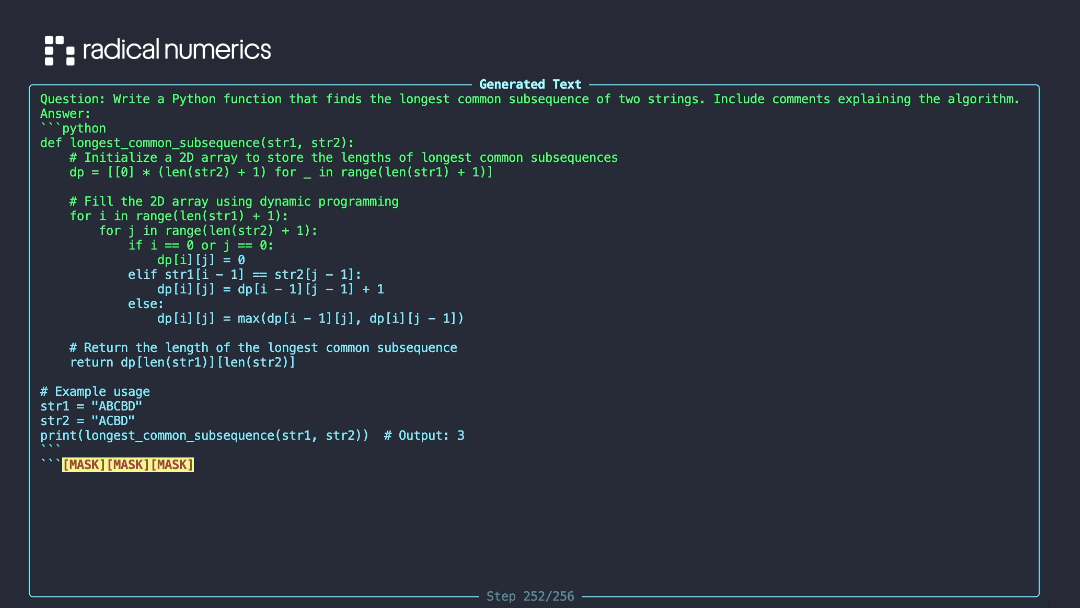
Links: Annoucement | Blog Post | GitHub | HuggingFace
MM-HELIX launches on Hugging Face as a 7B parameter multimodal model with thinking capabilities.
Links: Paper | HuggingFace
kani-tts-370m introduces a lightweight 370M parameter text-to-speech model for resource-constrained environments.
Links: HuggingFace Model | Demo Space
OpenAI GPT-5 Pro and AgentKit launches with enhanced capabilities and agent development frameworks, representing significant advancement in large language model capabilities and agent development tools.
Links: Docs
UNIDOC-BENCH provides 70,000 real-world PDF pages spanning eight domains with 1,600 multimodal QA pairs for evaluating document RAG systems. Links: Paper | GitHub
CFVBench offers comprehensive video benchmark for fine-grained multimodal retrieval-augmented generation.
Link: Paper
📈 Trends & Predictions
Unified Multimodal Retrieval Architectures Consolidate Modalities
Nvidia's Omni-Embed-Nemotron demonstrates a trend toward consolidating retrieval capabilities across text, images, audio, and video within single unified architectures. Building on recent work like ColPali, which showed that preserving document layout through image-based representations improves retrieval quality, and inspired by capabilities of models like Qwen2.5-Omni, the approach extends unified embeddings to encompass all major content modalities. Rather than maintaining separate retrieval pipelines for each content type, the model provides consistent embedding spaces that enable both cross-modal retrieval (searching across different modality types) and joint-modal retrieval (combining multiple modalities in queries). This architectural consolidation addresses practical challenges in managing heterogeneous content collections. Organizations maintaining documents, presentations, recorded meetings, and training videos can implement unified search interfaces rather than separate systems for each content type. The ability to find connections across media types, such as locating a concept mentioned in both a PDF document and a recorded presentation, becomes more straightforward when embeddings exist in consistent spaces.
For multimodal indexing and retrieval systems, this trend suggests a shift from modality-specific pipelines toward unified architectures that handle diverse content types through consistent frameworks. The practical implications center on simplified infrastructure, more coherent search experiences, and the ability to discover relationships across content that exists in different formats. As these unified architectures mature, the distinction between searching "documents" versus "videos" versus "audio recordings" may become less relevant to end users, who simply search for information regardless of its original format.
Diffusion Models Expand Beyond Image Generation
The application of diffusion techniques to domains beyond image generation represents a significant expansion of the methodology's scope. RND1 demonstrates diffusion applied to text generation, achieving competitive performance with traditional autoregressive approaches while offering potential advantages in parallel generation and controllability. Fast-dLLM v2 shows that pretrained autoregressive models can be efficiently adapted into block diffusion models for parallel text generation, requiring only ~1B tokens of fine-tuning compared to the 580B tokens needed for full-attention diffusion LLMs like Dream. DiffusionNFT extends the technique to reinforcement learning, introducing a new online RL paradigm that works directly on the forward process via flow matching.
These applications share a common pattern: adapting diffusion principles to new domains while addressing domain-specific challenges. For text, this involves handling discrete tokens and maintaining coherence across longer sequences. For reinforcement learning, it requires integrating reward signals into the diffusion process. The success of these adaptations suggests that diffusion's core principles, iterative refinement through learned denoising processes, generalize beyond the image domain where they first proved successful.
The practical implications for multimodal systems are substantial. Text generation components that can operate in parallel rather than sequentially may reduce latency in multimodal pipelines. Reinforcement learning approaches that leverage diffusion could enable more sophisticated training of multimodal agents. As diffusion techniques continue expanding into new domains, multimodal systems gain access to a broader toolkit of generation and optimization methods that share common underlying principles, potentially simplifying integration and enabling novel combinations of capabilities across different modalities.
🧩 Community + Shoutouts
Shoutout to the Alibaba Qwen team for releasing Qwen3-VL Cookbooks. Comprehensive guides that teach while documenting.
Links: Announcement | GitHub
Shoutout to enigmatic_e for the entertaining stress test of Wan 2.2 Animate.
Link: Post
That's this week's Multimodal Monday. Unified retrieval architectures that handle multiple modalities. Real-time generation at production speeds. Models that think before they act. The research continues advancing.
Ready to build multimodal solutions that actually work? Let's talk.