Multimodal Monday 32: Multi-Query Retrieval, Streaming Video
Multimodal Monday 32: AMER shows 4-21% gains on complex queries by generating multiple embeddings, Adobe MotionStream hits 29 fps with interactive motion controls, Step-Audio-EditX edits voice emotion and style through text prompts, and GEN-0 trains robots for general skills.

📢 Quick Hits (TL;DR)
Retrieval beyond single vectors - Single-vector search fails when you ask complex questions. AMER generates multiple embeddings that capture different aspects of your query, finding better results from more angles.
Models learn to think in images - V-Thinker gives models an internal sketchpad. Thinking with Video lets them reason by generating video sequences. Both approaches help AI understand problems the way you do.
Real-time video generation continues advancing - Adobe’s MotionStream and Tencent’s Rolling Forcing generate high-quality video in real-time on a single GPU. You can now create and edit video instantly with interactive controls.
🧠 Research Highlights
Beyond Single Embeddings: Capturing Diverse Targets with Multi-Query Retrieval
Single-vector retrieval breaks when queries have multiple distinct answers. The Autoregressive Multi-Embedding Retriever (AMER) generates a sequence of query embeddings instead of one, capturing diverse relevant documents for ambiguous or list-based queries.
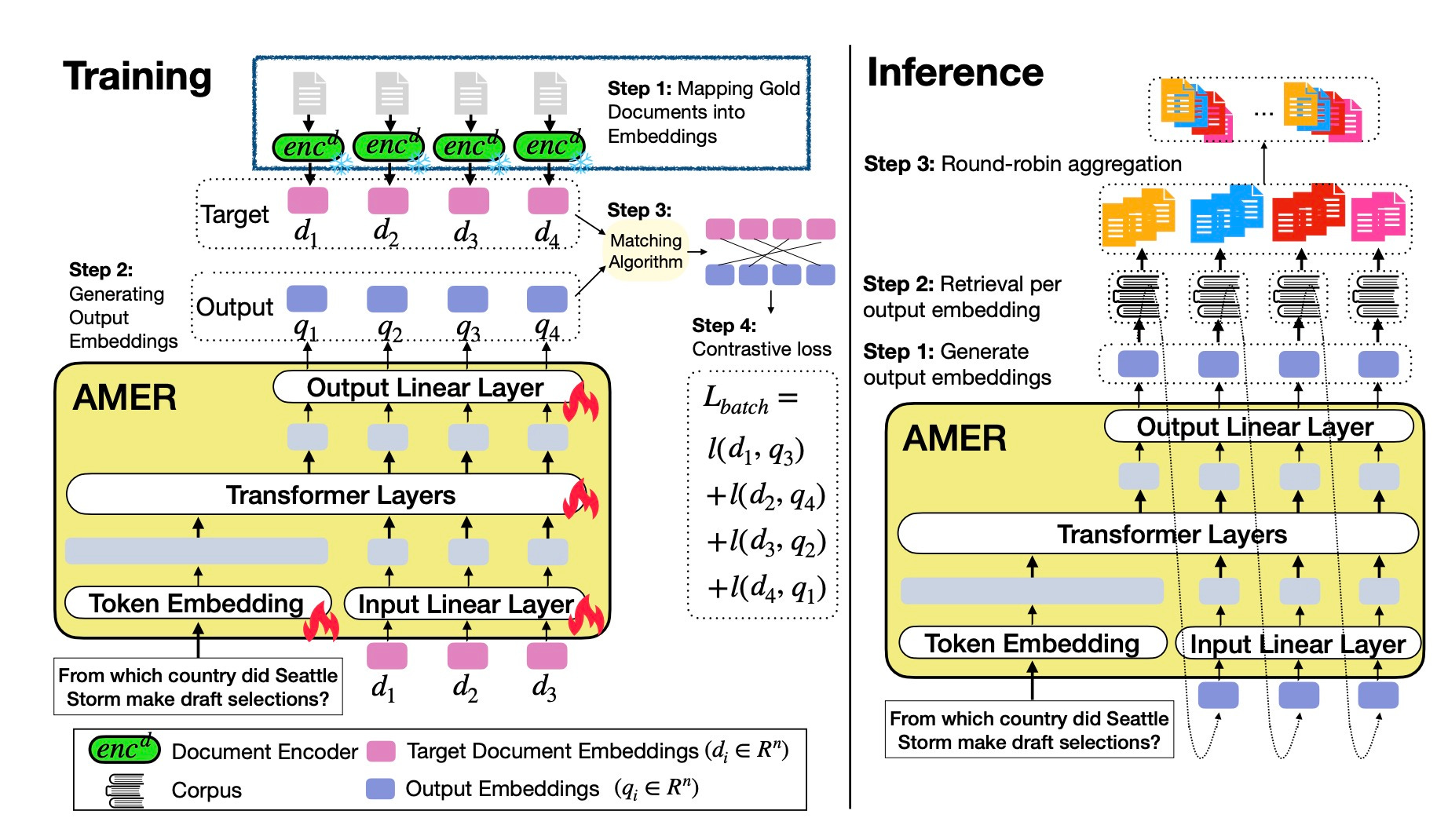
Why it matters: Your search application needs this if you handle complex queries beyond simple lookups.
Links: Paper
FractalForensics: Proactive Deepfake Detection and Localization
This detector embeds fractal watermarks into images before they’re shared online. The watermarks survive normal edits but break under AI manipulation, showing you exactly where an image was altered.
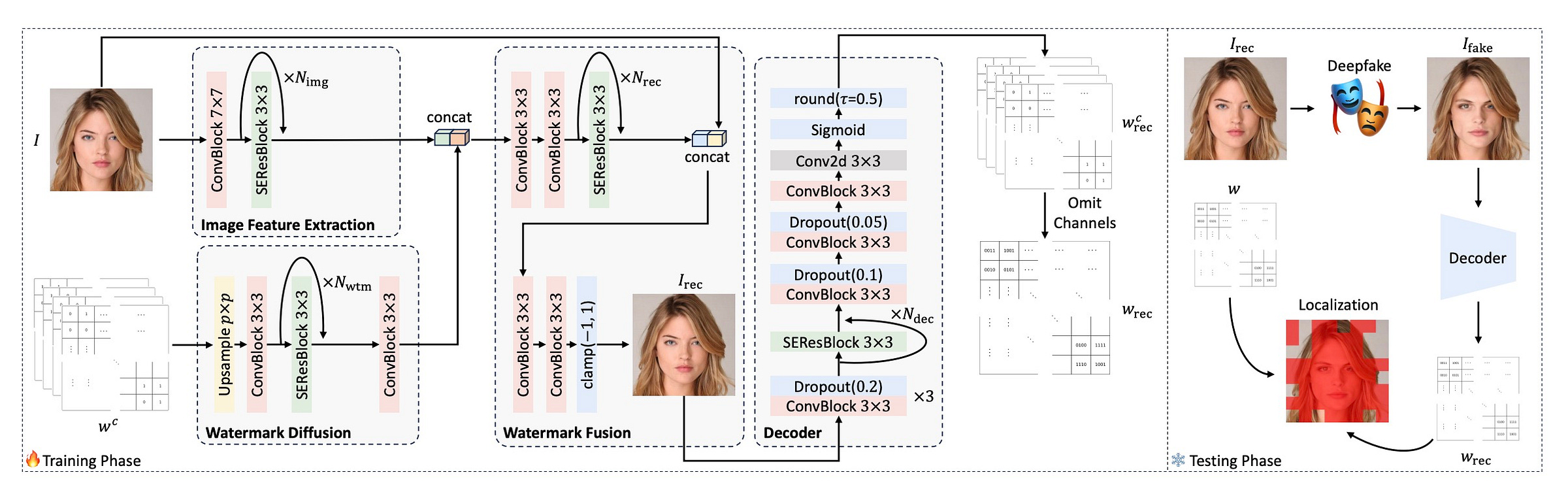
Why it matters: You get both detection and proof of manipulation in one system.
Links: Paper
Cambrian-S: Advancing Spatial Supersensing in Video
NYU and Stanford researchers built models that anticipate and organize complex visual experiences in long videos. The system selects relevant information and reasons about relationships between objects and events over time.
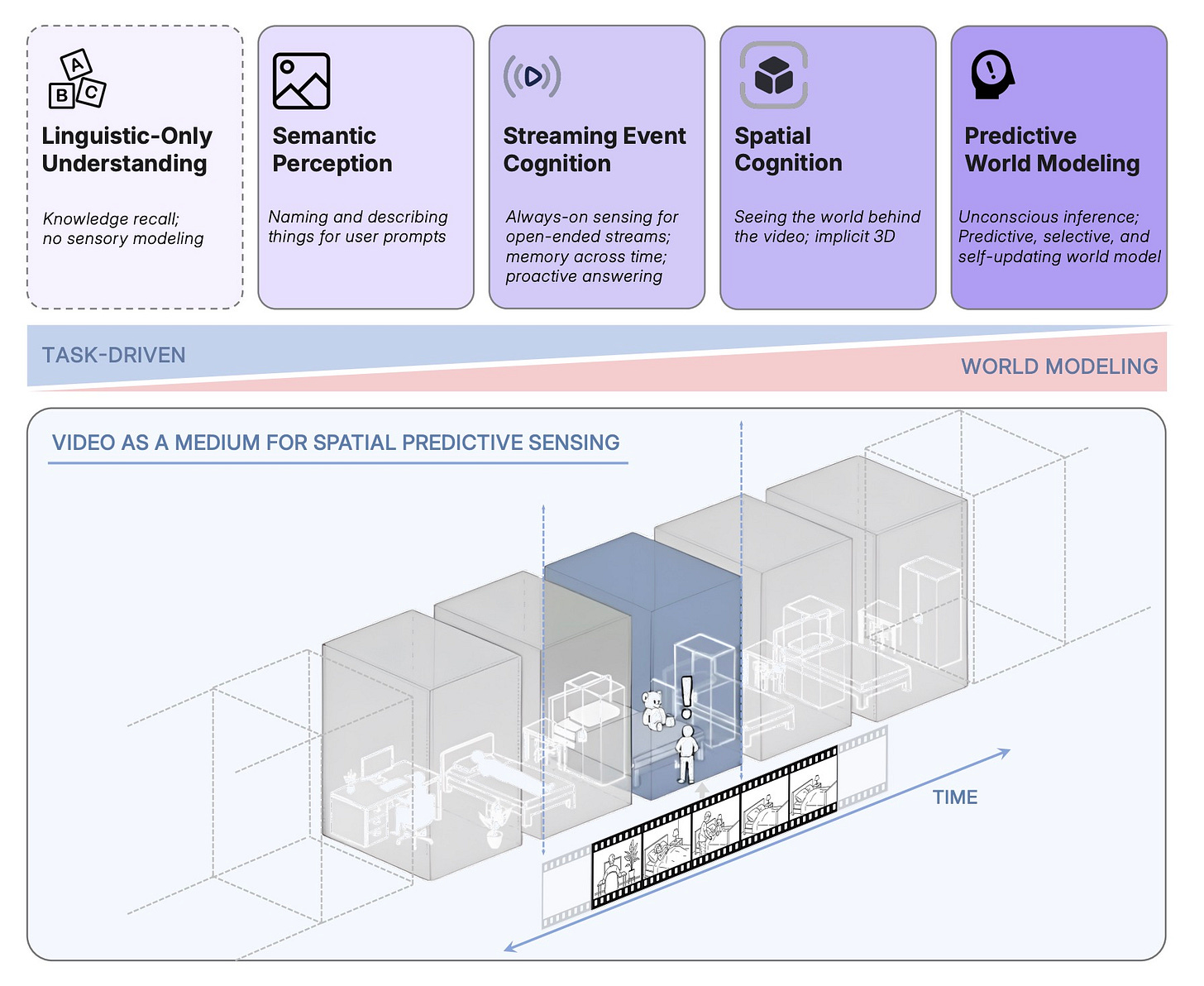
Why it matters: This moves beyond passive video understanding to active scene comprehension.
Links: Hugging Face | Paper
The Underappreciated Power of Vision Models for Graph Structural Understanding
Vision models outperform graph neural networks at understanding global graph properties. GraphAbstract benchmark shows vision models intuitively grasp overall structure better than specialized GNNs.
Why it matters: You might not need specialized graph models when vision models work better.
Links: Paper
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Models improve reasoning on both vision and text tasks by generating video sequences. The Video Thinking Benchmark shows that video generation helps models explore possibilities and think dynamically.
Why it matters: Video generation becomes a thinking tool, not just an output format.
Links: Project Page | Paper | GitHub
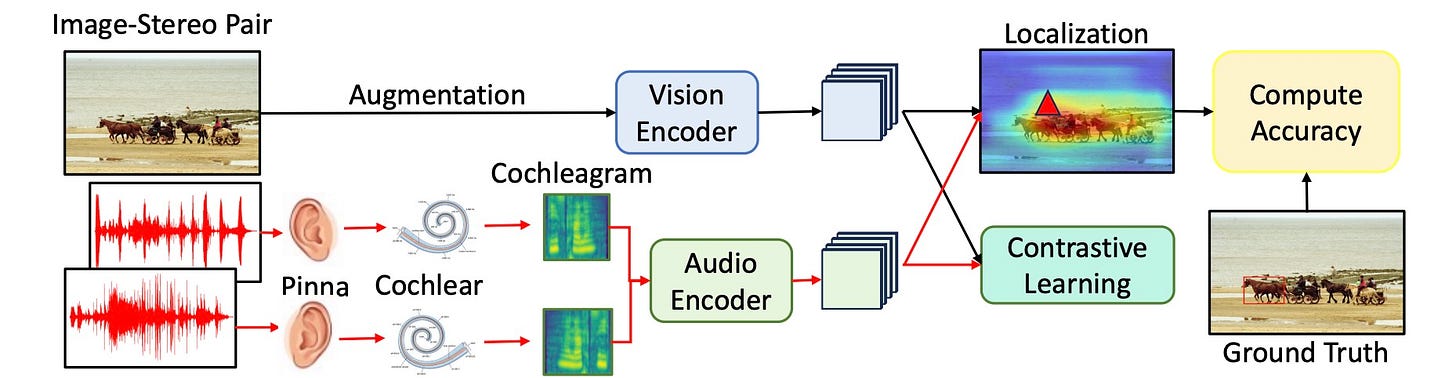
Seeing Sound, Hearing Sight: A new neuroscience-inspired model resolves cross-modal conflicts for sound localization. Links: Paper
Don’t Blind Your VLA: A new paper on aligning visual representations for OOD generalization. Links: Paper
Spatially anchored Tactile Awareness: Teaching robots sub-millimeter precision through spatially-grounded touch. Links: Paper
World Simulation with Video Foundation Models: A new paper on using video foundation models for physical AI. Links: Paper
ELIP: Enhanced visual-language foundation models for image retrieval. Links: Project Page | Paper | GitHub
V-Thinker: Interactive thinking with images. Links: Paper
SIMS-V: Simulated instruction-tuning for spatial video understanding. Links: Project Page | Paper
🛠️ Tools, Models and Techniques
OlmoEarth-v1-Large
AllenAI released a foundation model for remote sensing trained on Sentinel and Landsat satellite data. OlmoEarth turns Earth data into insights within hours using ready-made infrastructure for both image and time series tasks.
Why it matters: You can monitor deforestation and track climate change without building your own satellite analysis pipeline.
Links: Hugging Face | Paper | Announcement
BindWeave
ByteDance’s model for subject-consistent video generation uses cross-modal integration to keep subjects consistent across multiple shots. BindWeave already works in ComfyUI.
Why it matters: Your videos maintain character consistency without manual intervention.
Links: Project Page | Paper | GitHub | Hugging Face
GEN-0
GeneralistAI built a 10B+ foundation model for robots with Harmonic Reasoning architecture. GEN-0 trains on 270,000+ hours of dexterous data to think and act simultaneously.
Why it matters: Robots can now learn general skills instead of task-specific programming.
Links: Blog Post | Announcement
Step-Audio-EditX
StepFun open-sourced the first LLM-grade audio editing model. Control emotion, speaking style, breaths, laughs, and sighs through text prompts in a 3B-parameter model that runs on a single GPU.

Why it matters: You edit audio like you edit text, with natural language commands.
Links: Project Page | Paper | GitHub | Hugging Face
Rolling Forcing
This technique generates multi-minute streaming videos in real-time on a single GPU. Rolling Forcing denoises multiple frames jointly and anchors context with attention sinks for temporal consistency.
Why it matters: You can generate long videos instantly without waiting for rendering.
Links: Project Page | Paper | GitHub | Hugging Face
Spatial-SSRL: A self-supervised reinforcement learning framework from InternLM for spatial understanding. Links: Paper | Hugging Face
UniAVGen: A new framework from Tencent Hunyuan for audio-visual generation. Links: Project Page | Paper
InfinityStar: A unified 8B spacetime autoregressive model from Bytedance for high-res image and video generation. Links: Paper | GitHub | Hugging Face
ElevenLabs Voice Design v3: A new tool for creating custom AI voices through text descriptions. Links: Blog Post
ViDoRe V3: A comprehensive evaluation of retrieval for enterprise use-cases. Links: Blog Post
📈 Trends & Predictions
Retrieval Gets Smarter
Search broke when you started asking it to do two things at once. AMER fixes this by generating multiple query embeddings instead of forcing everything through a single vector.
Here’s what that means. When you search for “climate change impacts and economic solutions,” a single-vector system picks one interpretation and misses the other. AMER showed 4x better performance than single embedding models on synthetic data where queries had multiple distinct answers arXiv. The gains get bigger when your target documents are conceptually distant from each other. The technique works by predicting query embeddings autoregressively. Each embedding captures a different facet of what you want. Think of it as asking the question from multiple angles simultaneously rather than hoping one angle catches everything.
On real-world datasets, AMER showed 4-21% gains on average, but the improvements jumped to 5-144% on queries where target documents formed distinct clusters arXiv. The system struggles when your answers are too similar because single-vector search already handles that fine.
This changes how you build search applications. Your recommendation engine can now surface diverse perspectives instead of variations on a theme. Your research tool finds opposing viewpoints without manual query refinement. Your enterprise search handles ambiguous questions that have legitimately different correct answers.
The limitation? Most real-world datasets don’t have enough diversity to show the full benefit yet. Target documents tend to cluster together more than they diverge. But for applications where you need comprehensive coverage over narrow precision, multi-embedding retrieval gives you tools that single vectors can’t.
Community + Shoutouts
Replicate Mouse Tracker
Shoutout to fofr and kylancodes for putting together a dedicated Replicate model that generates HTML with a face that follows the cursor. Links: Replicate | Post
VideoSwarm 0.5
Shoutout to Cerzi for releasing VideoSwarm 0.5, a mass video player for easy browsing of large video datasets. Links: GitHub
That’s a wrap for Multimodal Monday #32! From AMER generating multiple query embeddings to capture diverse search targets, to Rolling Forcing and MotionStream achieving real-time video generation on single GPUs (if you have the hardware), to V-Thinker and Thinking with Video showing models that reason by generating visual sequences, this week demonstrates how multimodal systems are evolving beyond single-vector thinking toward dynamic, multi-faceted approaches to understanding and creation.
Ready to build multimodal solutions that actually work? Let's talk.