Multimodal Monday #12: World Models, Efficiency Increases
Multimodal Monday #12: V-JEPA 2 boosts vision understanding with self-supervised world model, LEANN cuts indexing to 5%, and DatologyAI CLIP gains 8x efficiency.

📢 Quick Takes (TL;DR)
- Unified multimodal frameworks reach new efficiency milestones - Meta's V-JEPA 2 demonstrates self-supervised world modeling for robotics while Ming-lite-omni achieves GPT-4o-level modality support with just 2.8B parameters.
- Ultra-efficient indexing enables local multimodal search - LEANN reduces vector index storage to under 5% of raw data while maintaining 90% recall, making multimodal search practical on personal devices.
- Data curation alone drives major CLIP performance gains - DatologyAI achieves state-of-the-art CLIP performance with 8x training efficiency and 2x inference gains using improved data curation techniques alone.
- Major tech companies deploy multimodal models - Apple introduces new Foundation Models with vision capabilities across 15 languages, while real-world applications expand across healthcare, automotive security, and sports analytics.
🧠 Research Highlights
ViGaL: Learning Through Arcade Games
Training multimodal models on Snake and other simple games significantly improves performance on complex reasoning tasks. The 7B model beats benchmarks on multimodal math without seeing a single worked solution.

Why It Matters: Synthetic games as training data could revolutionize how we build models that understand complex visual-textual relationships.
Paper | Project | Code
RCTS: Tree Search Re-ranking for Multimodal RAG
New framework enriches multimodal RAG with reasoning patterns and uses Monte Carlo Tree Search for relevance ranking. Self-consistent evaluation ensures high-quality reasoning examples in the knowledge base.

Why It Matters: Directly solves the erratic response problem in multimodal RAG, making visual question answering more reliable.
Paper | Code
CLaMR: Contextualized Late-Interaction for Multimodal Content Retrieval
Extends proven late-interaction techniques to multimodal content, enabling nuanced understanding of how visual and textual elements relate within documents. The contextualized approach improves query-document matching across modalities.

Why It Matters: Could significantly boost multimodal search accuracy by better understanding content relationships.
Announcement | Paper
A Distractor-Aware Memory for Visual Object Tracking with SAM2
CVPR 2025 paper proposing a new distractor-aware memory model for SAM2 and an introspection-based update strategy that jointly addresses segmentation accuracy and tracking robustness. The resulting tracker SAM2.1++ outperforms SAM2.1 and related SAM memory extensions on seven benchmarks, setting new state-of-the-art on six of them.
Announcement | Paper | Code
Additional Research
- Text Embeddings Should Capture Implicit Semantics - Position paper arguing that text embedding research should move beyond surface meaning and embrace implicit semantics as a central modeling goal Paper
- A Distractor-Aware Memory for Visual Object Tracking with SAM2 - Proposes a new distractor-aware memory model for SAM2 and an introspection-based update strategy that jointly addresses segmentation accuracy and tracking robustness. Paper | Code
- Vision Transformers: Test-Time Registers Beat Training - Shows high-norm outliers hurt ViT performance but can be fixed at test-time instead of retraining. Announcement | Paper
🛠️ Tools & Techniques
Meta V-JEPA 2: Self-Supervised World Model for Robotics
Meta's V-JEPA 2 learns visual representations by predicting future states in video without labels. The self-supervised foundation model enables robots to understand and predict how objects and environments evolve over time.
Why It Matters: Unlocks general-purpose robotic intelligence that can predict multimodal interactions, enabling more sophisticated temporal search capabilities.
Meta AI Blog | Paper
Apple Foundation Models 2025
New generation features multimodal understanding across 15 languages with improved reasoning. Includes 3B on-device model and novel PT-MoE server architecture optimized for Apple silicon.
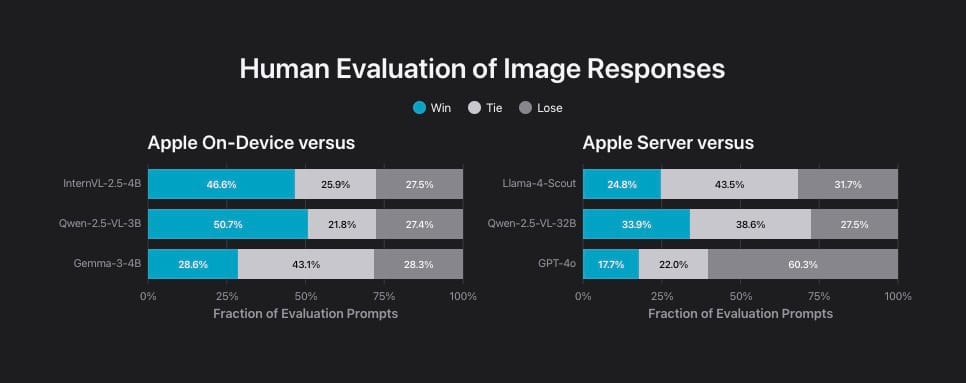
Why It Matters: Mainstream deployment of efficient multimodal AI sets new standards for consumer products.
Apple ML Research | Documentation
NVIDIA GEN3C: 3D-Aware Video Generation
Open-sourced generative video model with explicit 3D cache for precise camera control. Handles single-view synthesis, dynamic scenes, and driving simulation with Apache 2.0 license.
Why It Matters: 3D understanding in video models enables spatial queries and better video searchability.
Announcement | Project | Paper
DatologyAI CLIP: Data Beats Architecture
Achieves SOTA CLIP performance (76.9% vs SigLIP2's 74%) through data curation alone. Delivers 8x training efficiency, 2x inference gains, and 80% cost reduction without architectural changes.
Why It Matters: Proves investing in data quality yields better returns than scaling model size.
Announcement | Blog | Models
LEANN: 50x Smaller Vector Indexes
UC Berkeley's ultra-efficient indexing reduces storage to under 5% of raw data while maintaining 90% recall. Compact graph structure with on-the-fly recomputation makes multimodal search feasible on phones.

Why It Matters: Enables sophisticated multimodal search on personal devices without cloud dependency.
Paper | Code
Ming-lite-omni: GPT-4o Modalities at 2.8B Parameters
AntGroup's unified model processes images, text, audio, and video while generating speech and images. First open-source model to match GPT-4o's modality coverage with 10x fewer parameters.
Why It Matters: Makes comprehensive multimodal search practical and cost-effective for organizations without data center budgets.
HuggingFace | Paper | Project
Text-to-LoRA: Natural Language Model Adaptation
Sakana AI's hypernetwork generates task-specific LoRA adapters from text descriptions. No fine-tuning needed - just describe what you want and get a custom adapter.
Why It Matters: Organizations can deploy specialized multimodal search for any domain using plain English.
Announcement | Paper
Additional Tools
- Implicit Semantics in Embeddings - Position paper arguing text embeddings should capture speaker intent and sociocultural context Paper
- TempVS Benchmark - Tests if models truly understand temporal order in image sequences Paper
- MMMG - Massive multi-tier benchmark for text-to-image reasoning Paper
- Optimus-3 - Generalist multimodal agents for Minecraft environments Paper
- Sound-Vision Substitution - Explores replacing vision with sound in LLaVA Paper
🏗️ Real-World Applications
GE HealthCare + AWS: Medical AI Foundation Models
Strategic partnership to co-develop multimodal AI for medical imaging copilots. Combines GE's imaging expertise with AWS infrastructure to analyze medical images alongside clinical text.
Why It Matters: Demonstrates multimodal AI viability in high-stakes healthcare environments.
Announcement
Syntiant: Ultra-Low-Power Automotive Security
Demonstrates multimodal security systems combining visual and audio processing for vehicles. Maintains extremely low power consumption suitable for automotive environments.
Why It Matters: Shows multimodal AI can work effectively in resource-constrained automotive applications.
Article
Hockey East: AI-Powered Sports Analytics
Expanded partnership with 49ing AG for AI video analysis across all games. System combines visual analysis with statistical data for comprehensive game insights.
Why It Matters: Proves multimodal AI's practical value for content analysis in sports and entertainment.
Announcement
📈 Trends & Predictions
The Efficiency Increases in Multimodal AI
This week's developments reveal a clear trend toward achieving more with less in multimodal AI. Ming-lite-omni's achievement of GPT-4o-level modality support with just 2.8B parameters, DatologyAI's 8x training efficiency gains through data curation alone, and LEANN's 50x storage reduction for vector indexes all point to a fundamental shift in how the industry approaches multimodal model development and deployment.
This efficiency revolution directly benefits multimodal indexing and retrieval systems by making advanced capabilities more accessible and cost-effective. Organizations can now deploy sophisticated multimodal search with significantly lower computational and storage requirements, enabling real-time processing of diverse content types without massive infrastructure investments.
Data Quality Over Model Scale
DatologyAI's breakthrough in achieving state-of-the-art CLIP performance through data curation alone reinforces a growing recognition that data quality often matters more than model scale. This trend suggests that future improvements in multimodal AI may come more from better data practices than from larger models.
Organizations building multimodal indexing systems should prioritize investing in high-quality data curation pipelines and preprocessing techniques rather than simply scaling model size. This approach could yield better search quality and user satisfaction while being more cost-effective and environmentally sustainable.
🧩 Community + Shoutouts
Open Source Releases
- Ming-lite-omni - First open-source model matching GPT-4o's modality support
- NVIDIA GEN3C - Apache 2.0 licensed 3D-aware video generation
- DatologyAI CLIP - SOTA models from improved data curation
- EmbodiedGen - Complete toolkit for interactive 3D world generation
Community Highlights
JEPA Architecture Evolution - A new post by TuringPost overview of 11+ variants now span video (V-JEPA 2), time-series (TS-JEPA), denoising (D-JEPA), CNNs (CNN-JEPA), music (Stem-JEPA), and discriminative targets (DMT-JEPA).
Post
The multimodal AI landscape is being reshaped by efficiency breakthroughs and novel training paradigms. This week proved that smaller, smarter models can outperform giants, that games teach better than textbooks, and that data curation beats architectural complexity. The future isn't about who has the biggest model - it's about who builds the smartest systems.
Ready to deploy efficient multimodal solutions that actually work? Contact us to get started