Multimodal Monday #31: Visual Thinking, Longer Video
Google Latent Sketchpad lets models sketch thoughts before acting, Amazon Nova MME unifies search, Emu3.5 matches Google's Nano Banana locally, BEAR reveals why AI fails physical tasks.

📢 Quick Hits (TL;DR)
MLLM Learn to Think Visually - Google’s Latent Sketchpad gives AI models an internal drawing board. They can now sketch out ideas before taking action, just like you doodle while thinking through a problem.
Video Gen Breaks the 10-Second Barrier - GVS creates ultra-long videos that follow camera paths through impossible geometries, generating all segments simultaneously. VFXMaster adds Hollywood-style effects on demand without any training, while ViMax handles everything from script to final video.
Diffusion Models Finally Make Sense - OpenAI and Sony just dropped a 130-page manual that explains how diffusion models actually work. They took years of scattered research and boiled it down to three simple views that anyone can understand.
🧐 Research Highlights
Generative View Stitching (GVS)
Researchers created a method that generates ultra-long videos following complex camera paths, including physically impossible ones like Penrose stairs. GVS generates all video segments simultaneously rather than sequentially, avoiding the visual glitches that plague current methods.
Why It Matters: You can now generate videos that follow any camera path you draw, opening doors for architects, filmmakers, and game designers.
Links: Project Page | GitHub | Announcement
BEAR: A Benchmark for Embodied AI
BEAR tests whether AI models understand the physical world through 4,469 tasks spanning everything from basic perception to complex planning. The benchmark includes BEAR-Agent, which boosts GPT-5’s embodied reasoning performance by 9.12% by integrating specialized vision models.
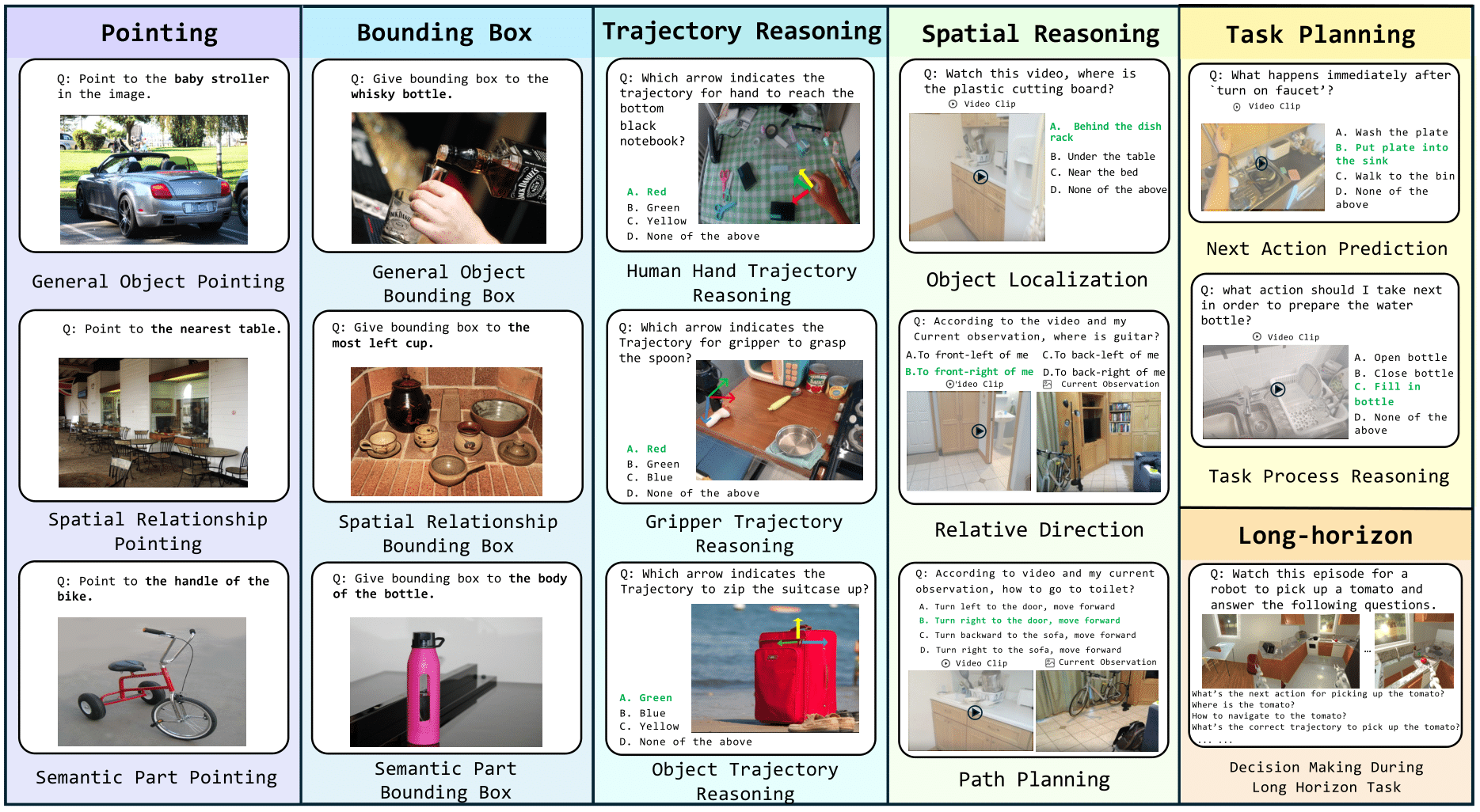
Why It Matters: BEAR exposes why your chatbot can’t help you fix a leaky faucet—most AI lacks basic physical reasoning skills.
Links: Project Page
Amazon Nova Multimodal Embeddings (MME)
Amazon built an enterprise model that searches across text, images, documents, video, and audio using one unified system. Nova MME creates a single searchable space where you can find a video clip using a text query or locate documents with an audio snippet.
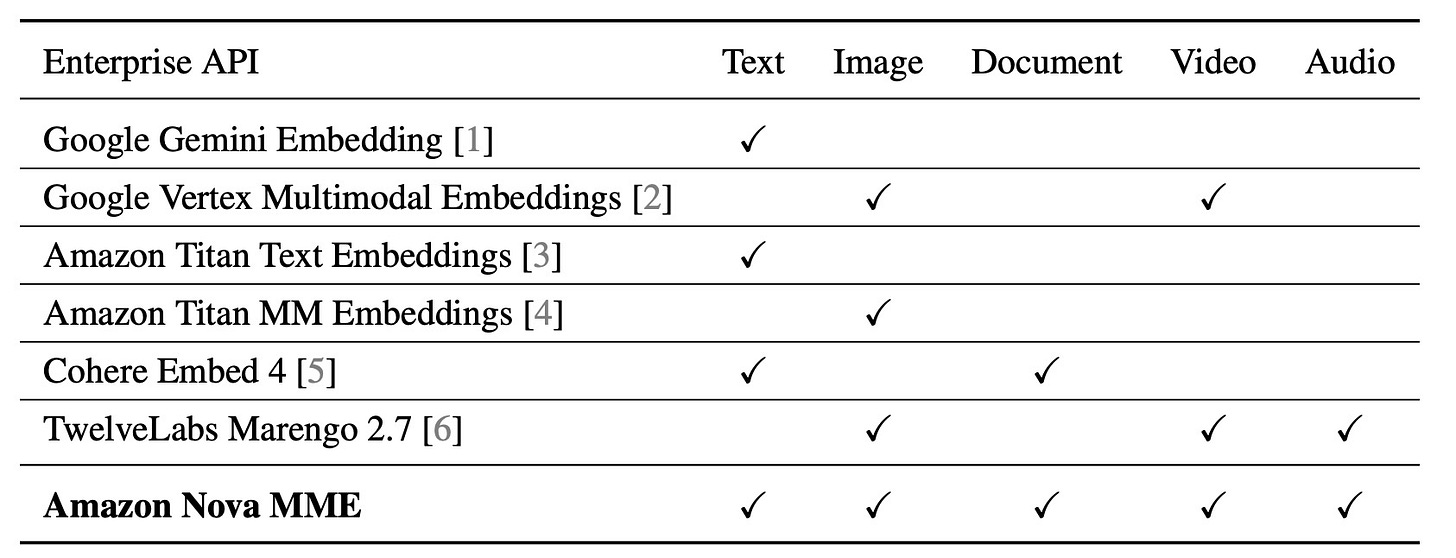
Why It Matters: One search box for everything, text, images, videos, audio, and documents all become instantly findable.
Links: Paper
HEAVEN: Hybrid-Vector Retrieval for Visually Rich Documents
HEAVEN solves document search’s speed-accuracy problem by using fast single-vector search for initial results, then applying precise multi-vector analysis for final ranking. This two-stage approach delivers both speed and accuracy when searching complex visual documents.
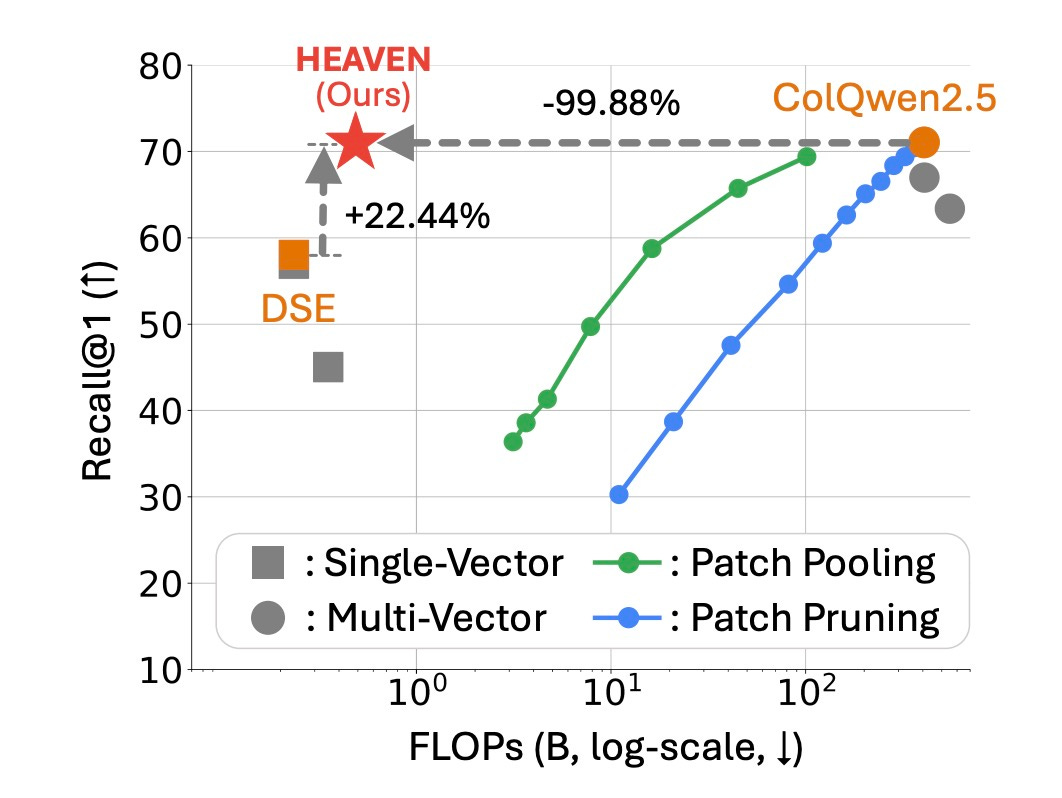
Why It Matters: You get Google-speed search with human-level accuracy for finding information in PDFs, slides, and scanned documents.
Links: Paper
Toward Socially-Aware LLMs: A Survey of Multimodal Approaches
This survey analyzed 176 papers and found most multimodal models miss crucial social cues like tone, body language, and context. The authors show current systems rely too heavily on text processing, discarding the visual and audio signals humans use to communicate.
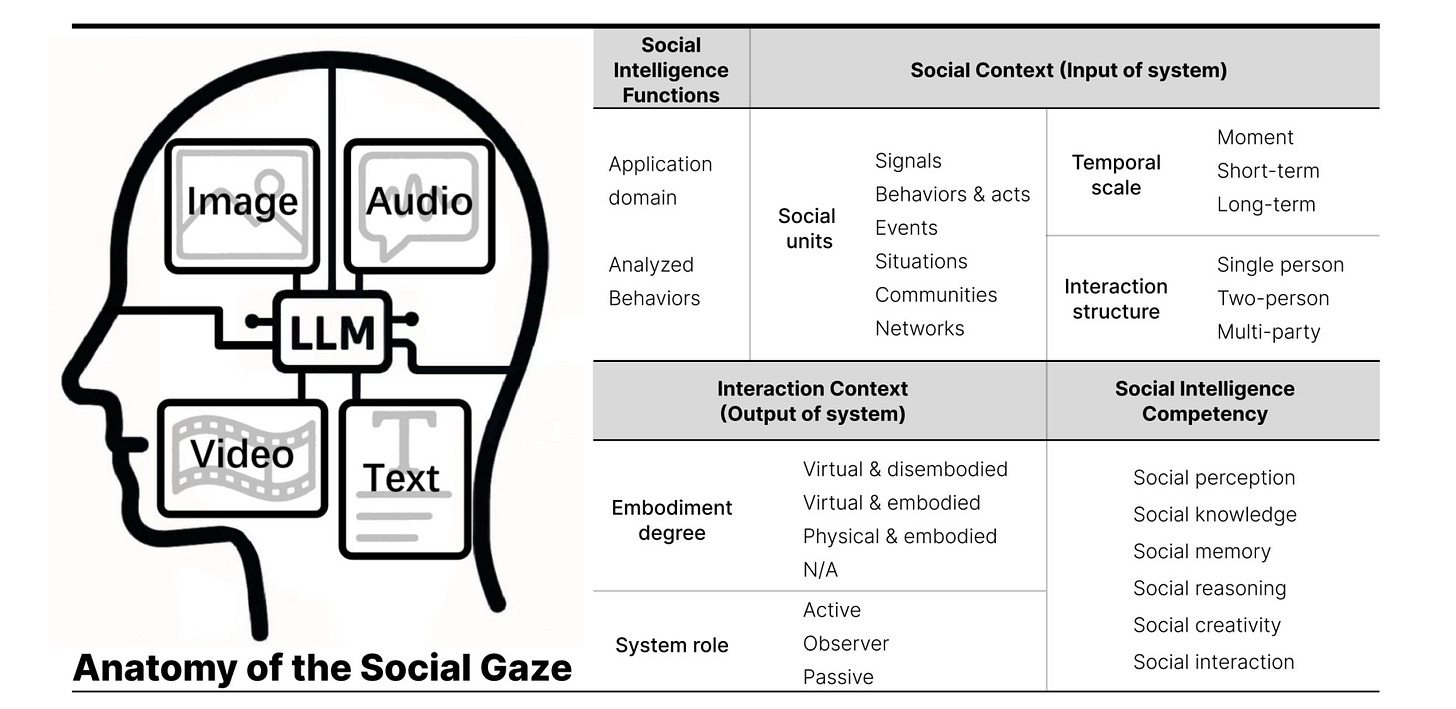
Why It Matters: Your AI assistant needs to understand when you’re being sarcastic, not just what you’re saying.
Links: Paper
Diffusion Models Monograph: OpenAI and Sony AI released a comprehensive guide unifying diffusion model theory into three complementary perspectives. Links: Paper
State of VLA Research at ICLR 2026: A guide reveals the performance gap between Gemini Robotics and open-source vision-language-action models. Links: Blog Post
Are video models ready as zero-shot reasoners?: Testing Veo-3 across 12 reasoning dimensions shows where video models excel and fail. Links: Paper | Project Page
VFXMaster: Generates dynamic visual effects through in-context learning without training. Links: Paper | Project Page
FARMER: ByteDance Seed unified Normalizing Flows and Autoregressive models for better image synthesis. Links: Paper
MMSD3.0: New benchmark for detecting sarcasm across multiple images. Links: Paper
🛠️ Tools, Resources and Techniques
Emu3.5: Native Multimodal Models are World Learners
Emu3.5 predicts what happens next across images, text, and video, matching Gemini 2.5 Flash’s performance while being fully open-source. The model excels at embodied manipulation tasks and image editing without requiring specialized training.
Why It Matters: You get Gemini-level multimodal AI that runs on your own hardware, no API keys required.
Links: Announcement | Paper | Project Page | Hugging Face
NVIDIA Surgical Qwen2.5-VL
NVIDIA fine-tuned Qwen2.5-VL to recognize surgical actions, instruments, and anatomical targets directly from endoscopic video. The model provides real-time surgical assistance by understanding what’s happening during procedures.
Why It Matters: Surgeons get an AI copilot that watches operations and provides instant guidance.
Links: Hugging Face
Latent Sketchpad: Sketching Visual Thoughts
Latent Sketchpad gives language models an internal visual canvas where they sketch ideas before responding. Models can now generate and refine visual concepts internally, leading to more coherent and creative outputs.
Why It Matters: AI can now think in pictures, not just words, solving visual problems the way humans do.
Links: Paper | Project Page | GitHub
NVIDIA ChronoEdit
ChronoEdit brings physics to image editing with a 14B model that understands how objects change over time. You can edit images while maintaining realistic physics and temporal consistency.
Why It Matters: Your edits follow the laws of physics, drop something and it falls, age a face and wrinkles appear naturally.
Links: Hugging Face | Paper
E²RANK: Unified Retrieval and Reranking
Alibaba created E²RANK to handle both search and ranking with one model using simple cosine similarity. The framework treats ranking prompts as relevance feedback, eliminating expensive autoregressive generation.
Why It Matters: Faster search that’s just as accurate, using one model instead of two.
Links: Paper | Project Page
BEDLAM2.0 dataset: More diverse 3D human pose and shape data. Links: Project Page
LongCat-Flash-Omni: 560B-parameter MoE model for real-time audio-visual interaction. Links: GitHub | Project Page
ViMax: Agentic Video Generation: AI handles everything from script to final video. Links: GitHub

Google Labs Pomelli: Experimental AI tool for scalable marketing content. By no means perfect but it worked surprisingly well when i gave it my new email agent client(try it free). Links: Website
Ming-flash-omni Preview: AntGroup’s new multimodal foundation model. Links: Hugging Face | Paper
Wan2GP: Fast video generation for regular GPUs. Links: GitHub
📈 Trends & Predictions
MLLMs Learn to Think Visually
Latent Sketchpad changes how AI solves problems. Instead of processing everything through text, models now have an internal drawing board. They sketch visual ideas, refine them, then act. Think of it like giving AI a napkin to doodle on while figuring things out. BEAR benchmark results show why this matters, current models fail at basic physical reasoning because they can’t visualize consequences.
The combination of visual thinking and embodied benchmarks pushes us toward useful robots. Emu3.5 already demonstrates world-state prediction across modalities. Add visual sketching, and you get robots that plan repairs by visualizing each step, architects who iterate designs internally, and AI tutors that solve geometry problems the way students do.
🧩 Community + Shoutouts
Awesome-World-Models GitHub Repo
Shoutout to Siqiao Huang for creating and curating my new go-to collection of world model research. If you want to understand where embodied AI is heading, start here.
Links: GitHub
AI Recreation of Old Spice Ad
Sanket Shah and Invideo proved AI video generation works for real production. They recreated the Old Spice ad shot-for-shot using current tools. Watch it to see what’s possible today.
Links: Post
Guest Lecture on VLAs
NVIDIA’s Ankit Goyal explains Vision-Language-Action models and robot manipulation. Clear explanations, practical examples, worth your time.
Links: Video | Slides
That’s a wrap for Multimodal Monday #31! From Latent Sketchpad giving models an internal visual canvas, to GVS generating ultra-long videos through impossible camera paths, to OpenAI and Sony unifying years of diffusion research into three clear views, to Amazon Nova MME creating unified search across five modalities, this week shows multimodal AI moving from text-dominated reasoning to true visual thinking, longer coherent generation, and genuinely unified cross-modal understanding.
Ready to build multimodal solutions that actually work? Let's talk.