Multimodal Monday #40: Unified Search, Synthetic Worlds
Qwen3-VL-Embedding unifies text, image, and video search in 30+ languages, HY-Video-PRFL trains 1.4x faster using video models as reward signals, PointWorld-1B simulates interactive 3D environments from single images, and Music Flamingo reasons about chord progressions and harmony.

📢 Quick Take (TL;DR)
- Search everything with one model. Qwen3-VL-Embedding and e5-omni unify text, images, video, and audio into single vector spaces.
- Practice in synthetic worlds first. PointWorld-1B simulates 3D environments from images, RoboVIP generates multi-view training data, and Web World Models turn the internet into a training ground.
- Understanding beats pattern matching. Music Flamingo reasons about harmony instead of tagging genres. Thinking with Map uses spatial reasoning to beat Gemini-3-Pro by 2.8x. MindWatcher chains multimodal thoughts.
- High-end AI on your GPU. LTX-2 does 4K video with audio, Qwen3-VL handles 30+ languages across media types, cBottle simulates atmospheric states at kilometer resolution. All on consumer hardware.
🛠️ Tools, Models and Techniques
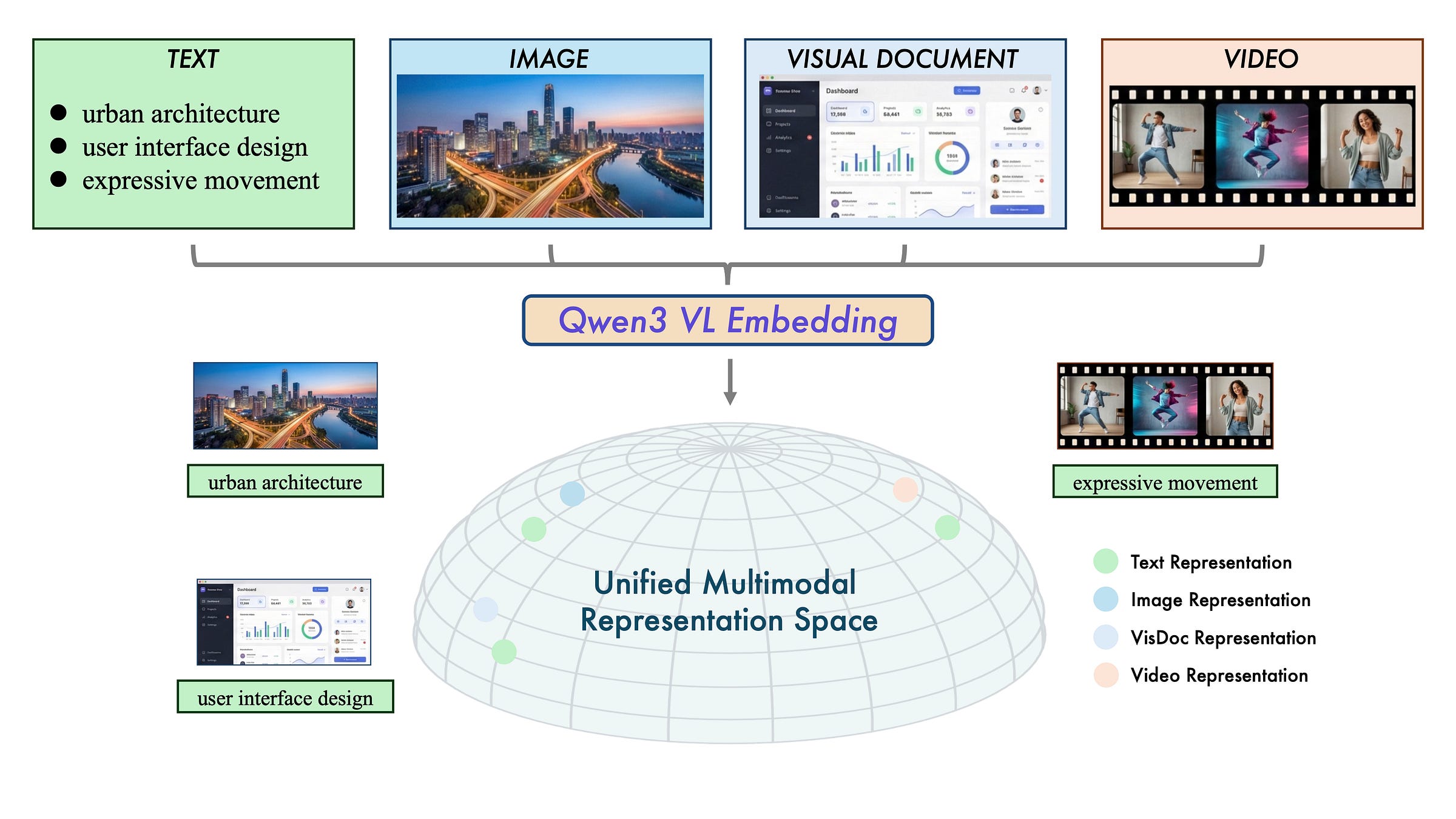
Qwen3-VL-Embedding & Reranker Alibaba’s bi-encoder maps text, images, and video into unified space while the cross-encoder reranker scores relevance. State-of-the-art across 30+ languages. Why it matters: One model handles all media types, eliminating separate pipelines for different content. Hugging Face (Embedding) | Hugging Face (Reranker) | Blog
e5-omni Solves the modality gap problem in omni-modal embeddings by fixing inconsistent score scales and negative hardness imbalance. Handles text, image, audio, and video simultaneously. Why it matters: Stabilizes training for models that need to understand everything at once. Paper | Hugging Face
The Living Edge is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.

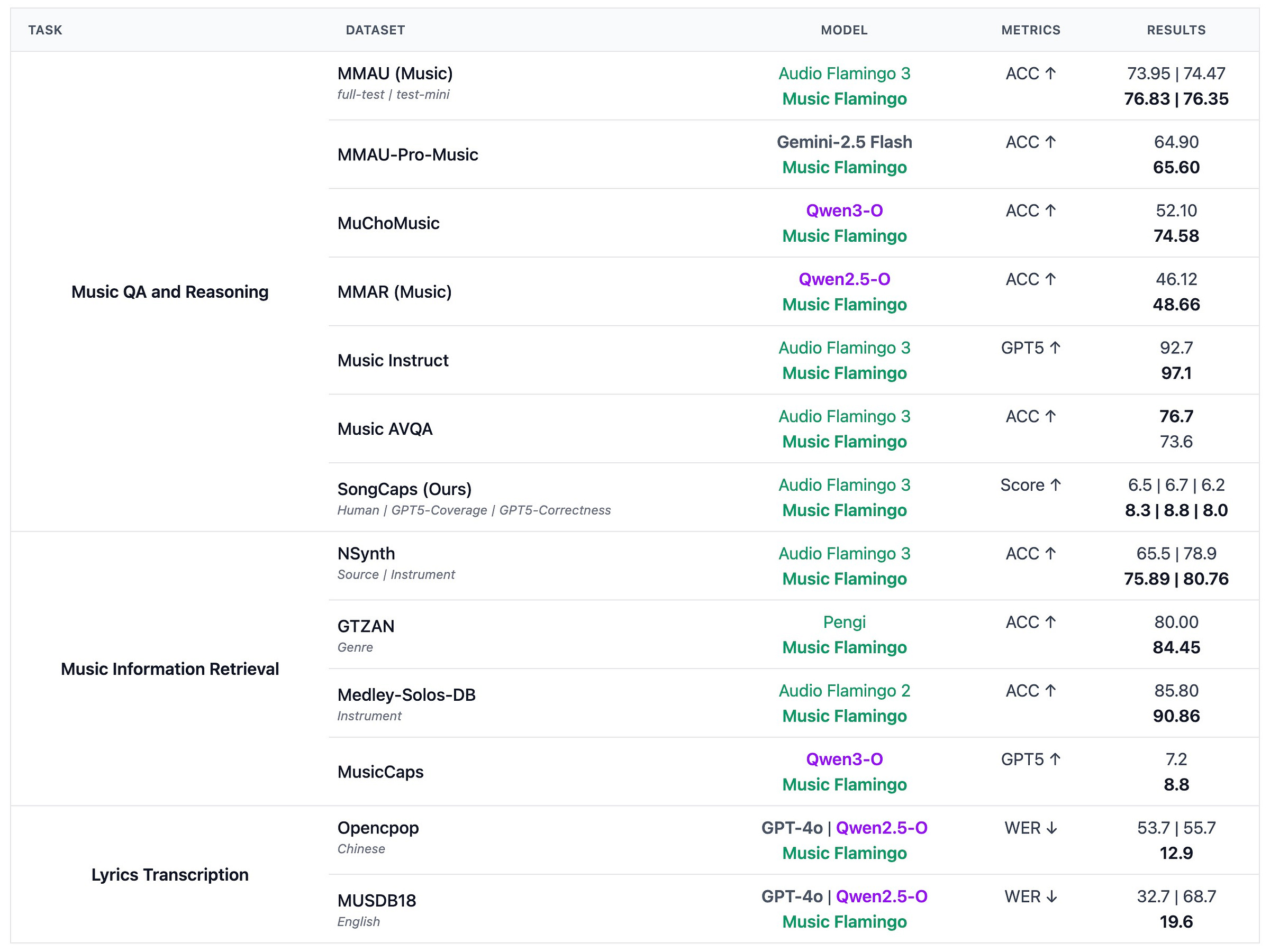
Music Flamingo NVIDIA’s open audio-language model understands full-length songs and reasons about music theory, harmony, structure, and cultural context. Goes beyond simple genre tagging. Why it matters: Enables deep content-based retrieval like searching for specific chord progressions or key changes. Hugging Face | Project Page | Paper | Demo
LTX-2 Lightricks’ video generation model supports 4K resolution, audio generation, 10+ second clips, and runs on consumer GPUs. Low VRAM requirements. Why it matters: High-quality video generation works on hardware you already own. Blog | Model | GitHub
UniVideo Kling’s open-source framework unifies video generation, editing, and understanding. Generate from text or images, then edit with natural language commands. Why it matters: Three tasks in one model means simpler deployment and faster workflows. Project Page | Paper
cBottle: NVIDIA’s diffusion model generates atmospheric states at kilometer resolution. Hugging Face

VideoAuto-R1: Framework for explicit reasoning in video understanding. GitHub

🧠 Research Highlights
PointWorld-1B NVIDIA and Stanford’s 1B parameter 3D world model predicts environment dynamics from a single image. Simulates interactive 3D worlds in real-time. Why it matters: Robots can test action consequences in realistic simulations before moving in the real world. Project Page | Paper
Web World Models Treats the web as a persistent simulation environment where LLMs generate actions and narratives within deterministic web code. Creates controllable training grounds for digital agents. Why it matters: Agents learn complex web tasks without breaking production sites. Project Page

HY-Video-PRFL Tencent’s method turns video generation models into latent reward models for self-improvement. Delivers 56% motion quality boost and 1.4x faster training through efficient preference optimization. Why it matters: Video models judge their own output quality, creating faster feedback loops. Hugging Face | Project Page

Thinking with Map Alibaba’s agent uses maps for geolocalization and outperforms Gemini-3-Pro by 2.8x. Combines agentic reinforcement learning with parallel test-time scaling. Why it matters: Specialized reasoning with map data unlocks navigation, logistics, and intelligence applications. Project Page | Paper
RoboVIP Augments robot data with multi-view, temporally coherent videos using visual identity prompting. Exemplar images condition diffusion models for precise scene control when training robot policies. Why it matters: Generates high-quality synthetic training data without thousands of teleoperation hours. Project Page | Paper
More Highlights(many interesting papers didnt make the cut):
- Robotic VLA with Motion Image Diffusion: Salesforce teaches VLAs to reason about forward motion. Project Page
- NeoVerse: Builds 4D world models from single-camera videos. Paper
Klear: 26B unified model for joint audio-video generation. Paper

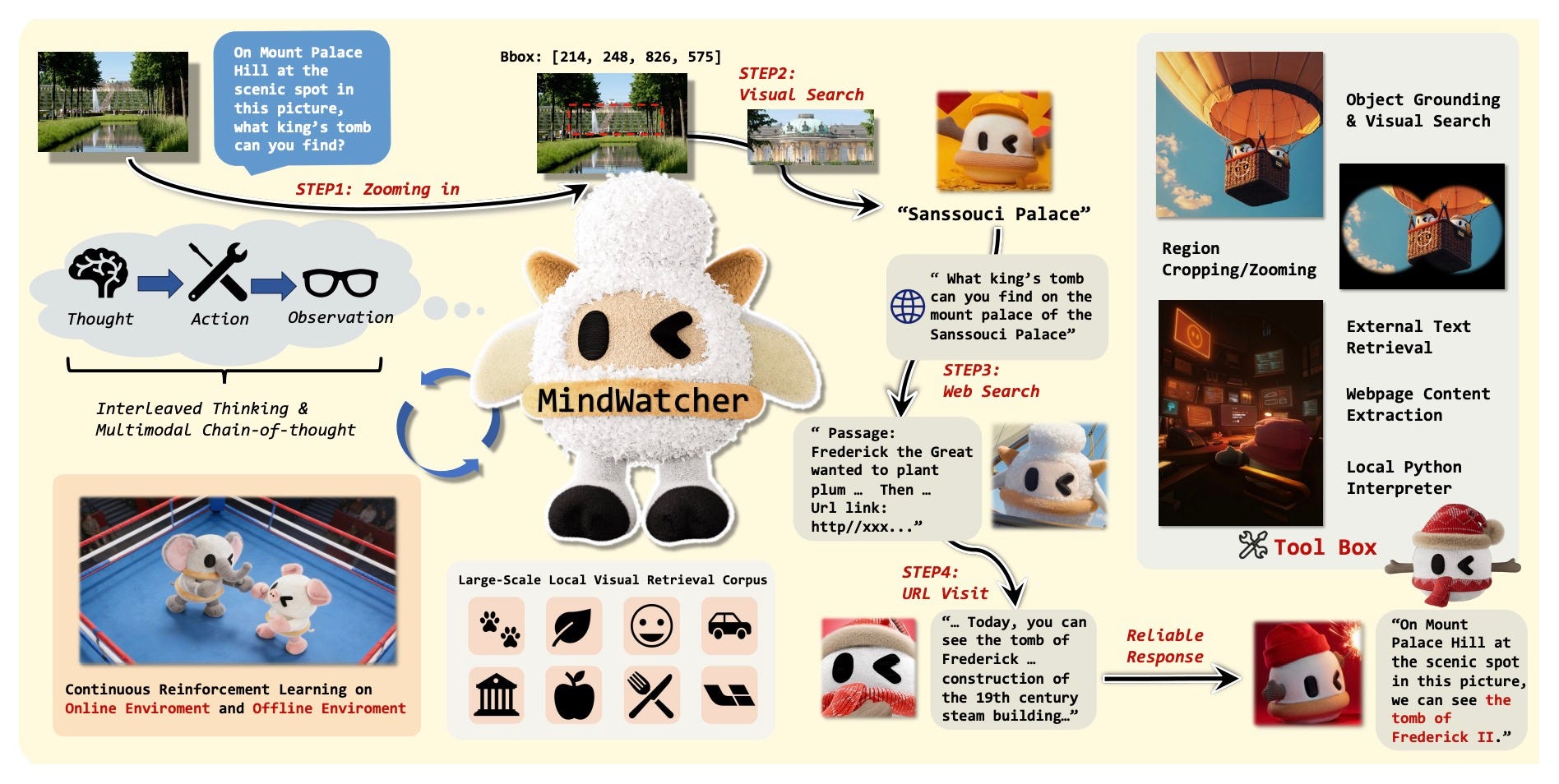
MindWatcher: TIR agent with interleaved thinking and multimodal chain-of-thought. Paper
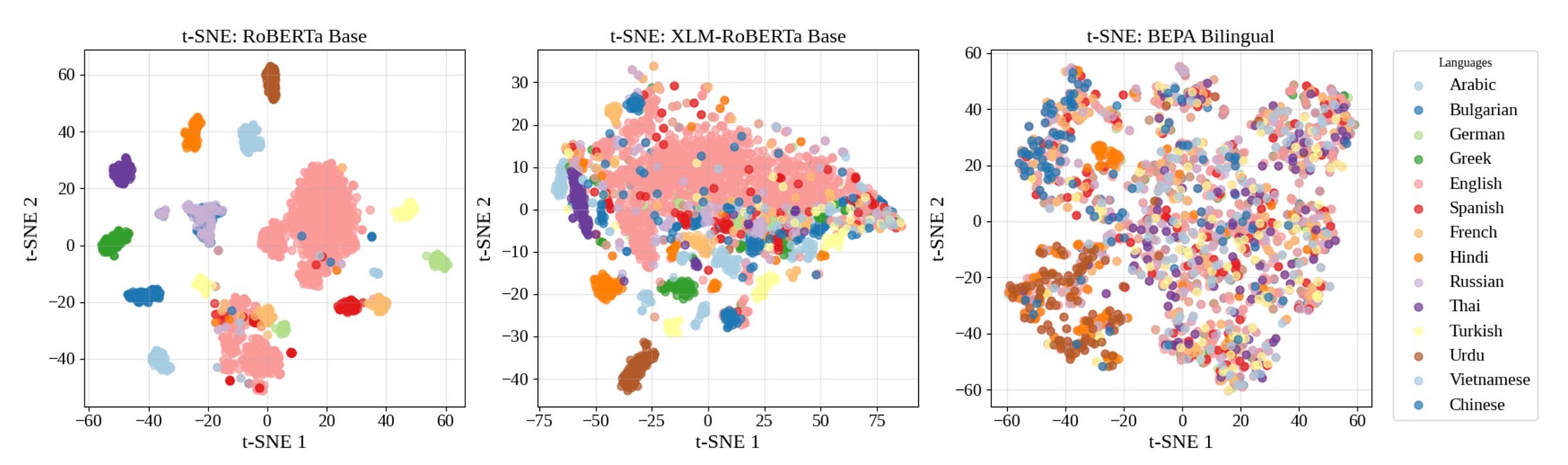
BERT-JEPA: Reorganizes CLS embeddings for language-invariant semantics. Paper
- VINO: Generates and edits images and videos from text and reference visuals. Project Page
- PII-VisBench: Benchmark for evaluating PII safety in VLMs. Paper

📈 Trends & Predictions
Unified multimodal retrieval is here
Qwen3-VL-Embedding and e5-omni launched this week. Both map text, images, video, and audio into single shared vector spaces. This marks a shift from stitching together separate models to truly unified architectures.
What this changes:
Cross-modal queries work. Find video clips matching audio snippets. Locate images that match how a text description sounds. Search relationships across data types instead of treating each modality separately.
Embeddings collapse into single space. Text, images, video, and audio now live in the same vector space. This enables queries that were structurally impossible before: "show me videos where the visual style matches this song's energy."
Music Flamingo adds depth. Beyond genre tags, you can now search by chord progressions, key modulations, and harmonic structure. Combined with unified embeddings, audio becomes as searchable as text.
Search is no longer only about keywords or semantic text matching. It's about finding patterns across every data type you produce. The question shifts from "can we search this modality?" to "what relationships exist between modalities that we couldn't see before?"
🧩 Community + Shoutouts
- Randy Retrieval Demo: Harpreet showed off Qwen3-VL-Embedding and Reranker in action. Extra points for including Randy Marsh. Post
- Qwen Camera Control: Linoy Tsaban added 3D interactive control to the Qwen Camera Angle demo. Space
- 3D Character Gen: Deedy shared a workflow for generating and animating 3D characters in under 5 minutes. Announcement
That's a wrap for Multimodal Monday #40! This week brought unified retrieval that works across any content type, video models that train themselves through internal feedback, world simulators that let robots practice before deployment, and audio understanding that reasons about structure instead of just labels.
Ready to build multimodal solutions that actually work? Let's talk