Multimodal Monday #43: Stop Looking, Start Seeing
Week of Jan 26 - Feb 1: World models dominate as EgoWM simulates robot actions from single images, Drive-JEPA predicts what matters for driving, Project Genie halluccinates playable games, and Google's Agentic Vision turns image analysis into active exploration.

📢 Quick Take (TL;DR)
- Vision models learn to look around - Google’s Agentic Vision and Moonshot’s Kimi K2.5 treat images as spaces to explore, not static inputs. They zoom, pan, and run analysis tools instead of just describing what they see.
- World models work for pixels and atoms - EgoWM simulates robot actions from a single image. Drive-JEPA predicts driving scenarios. Project Genie generates playable games in real time. These systems model physics and consequences, not just pixels.
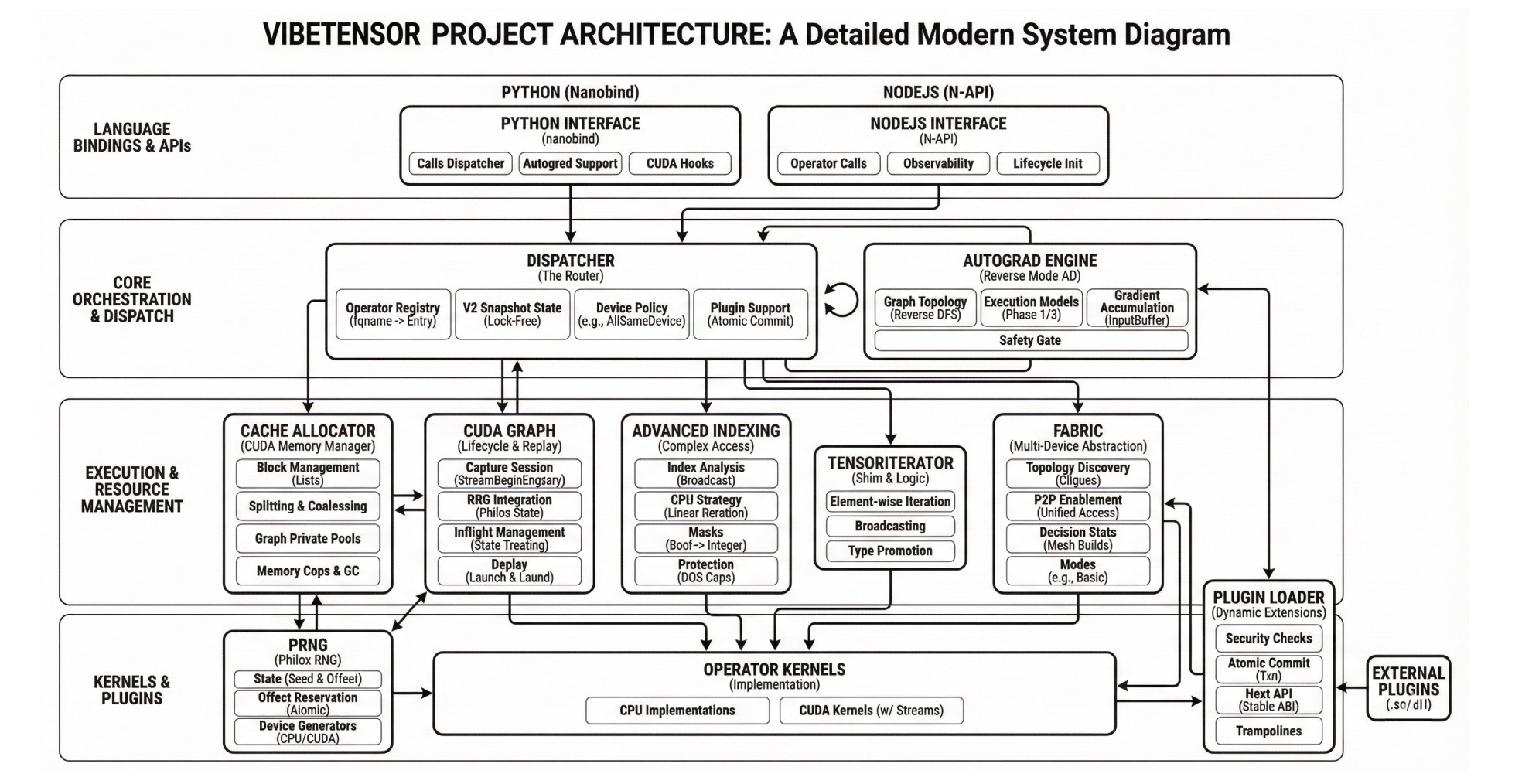
- AI wrote a CUDA library - NVLabs’ VibeTensor is a working C++/CUDA tensor library built entirely by coding agents. We’ve moved past script generation into systems programming.
🛠️ Tools, Models and Techniques
Kimi K2.5: Visual Agentic Intelligence Moonshot AI’s open-source multimodal model trained on 15 trillion tokens. Its “Agent Swarm” framework splits tasks into parallel subtasks and runs 4.5x faster than sequential execution.
Why it matters: Parallel execution solves the latency problem that kills agentic workflows and their new visual intelligence is extremely impressive for an open source model. Blog | Hugging Face
Agentic Vision in Gemini 3 Flash Google gave Gemini 3 Flash the ability to investigate images actively. The model zooms, pans, and runs code to inspect details rather than processing static frames. Why it matters: You can now point it at a 50MP X-ray or satellite image and ask it to find specific details. Blog
Project Genie DeepMind’s prototype generates interactive 2D worlds you can play in real time. A world model predicts frame-by-frame reactions to your inputs, hallucinating a working game as you go. Why it matters: This moves generative AI from creating assets to creating playable experiences. Blog
HuggingFace daggr A visual tool for building multimodal pipelines by mixing model endpoints, Gradio apps, and custom components. You can inspect and debug workflows graphically before deploying. Why it matters: Agentic pipelines are usually messy script piles, and this makes them debuggable. Blog | GitHub
Z-Image A text-to-image foundation model built for precise control with classifier-free guidance, negative prompting, and LoRA support baked in. Why it matters: Production workflows need steering, not just generation. Hugging Face

- LingBot-World: An open-source world simulator for video generation research. GitHub
- MOSS-Video-and-Audio: A 32B MoE model for generating synchronized video and audio in one pass. Hugging Face
- Lucy 2: A real-time video generation model for editing and robotics applications. Project Page


- NVIDIA Earth-2: Open models for high-accuracy AI weather forecasting. Blog
- DeepEncoder V2: A novel architecture for 2D image understanding that dynamically reorders visual tokens. Hugging Face
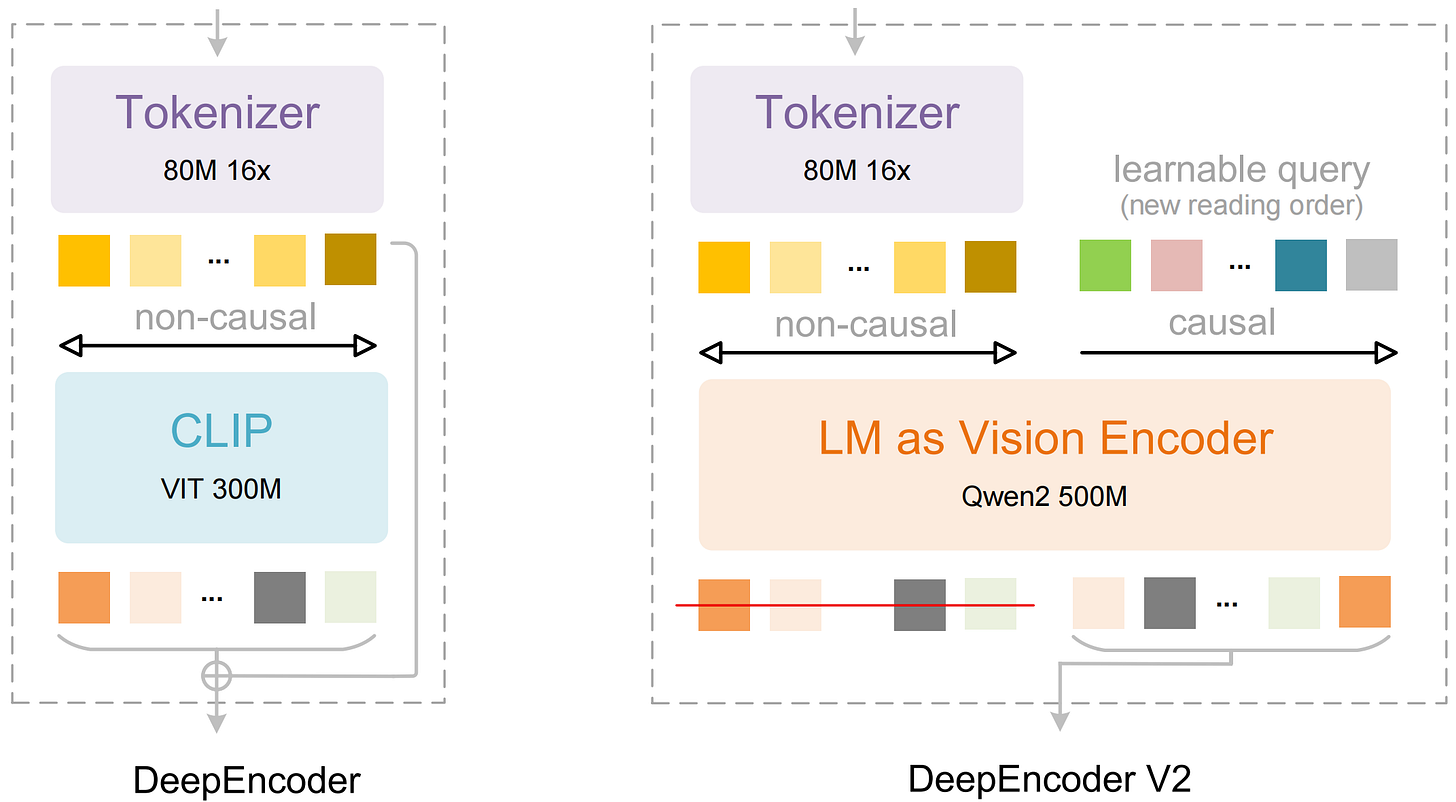
- TeleStyle: A content-preserving style transfer model for images and videos. Project Page
- Qwen3-ASR-1.7B: A state-of-the-art speech recognition model for transcription. Hugging Face
- PaperBanana: An agentic framework for automating academic illustrations. Project Page

- HunyuanImage-3.0-Instruct: A powerful model for image generation and editing with multimodal fusion. Hugging Face

🧠 Research Highlights
Ego-centric World Models (EgoWM) A video world model that simulates humanoid actions from a single first-person image. It generalizes across visual domains so well that a robot can “imagine” its movements rendered as a painting. Why it matters: Robots need internal simulators that work even when the visual world looks nothing like training data. Project Page | Paper
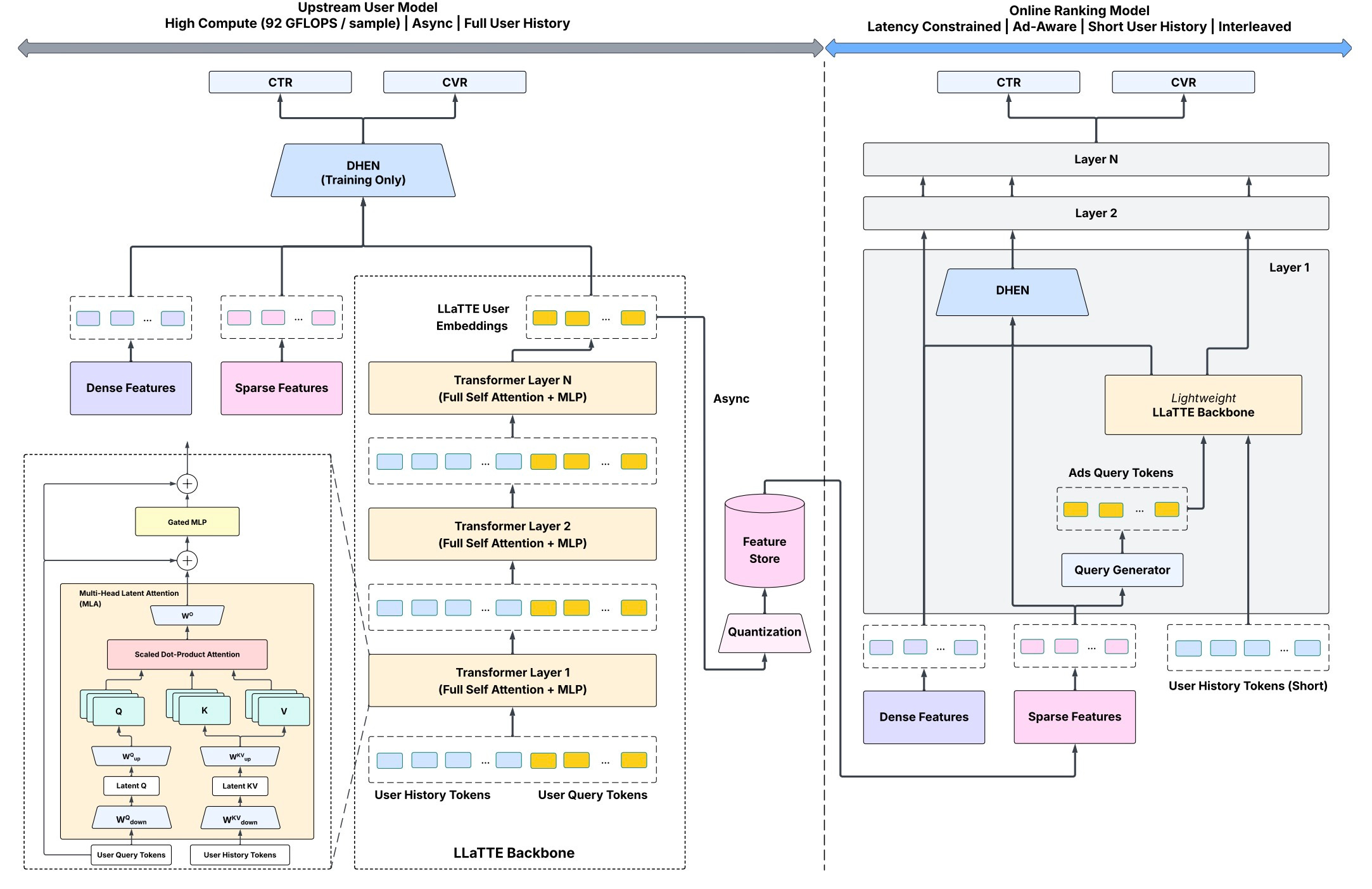
LLaTTE: Scaling Laws for Ads Meta found that recommendation systems follow the same power-law scaling as LLMs. Adding multimodal features (images, text) bends the scaling curve and makes models learn faster. Why it matters: Multimodal inputs are a fundamental efficiency gain, not just a feature checkbox. Paper
Drive-JEPA Combines Video JEPA with trajectory distillation for autonomous driving. Instead of predicting every pixel, it predicts abstract representations of what matters on the road. Why it matters: Cars don’t need to model leaves and shadows, just other vehicles and pedestrians. Hugging Face | GitHub
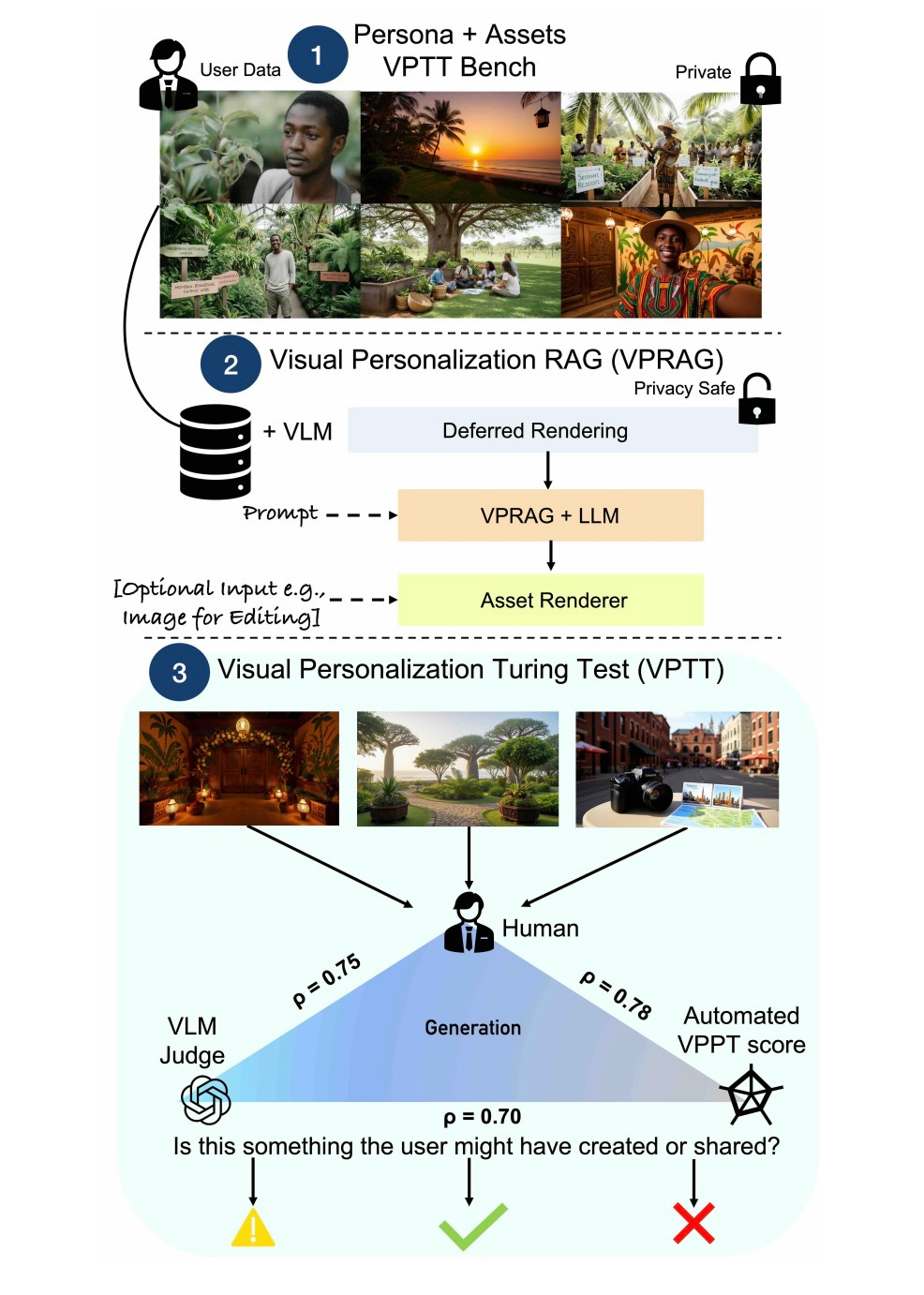
Visual Personalization Turing Test (VPTT) A benchmark that tests whether models can create content indistinguishable from what a specific person would make. It goes beyond style transfer to capture individual creative voice. Why it matters: Personalized AI tools need a way to measure whether they actually captured your taste. Hugging Face
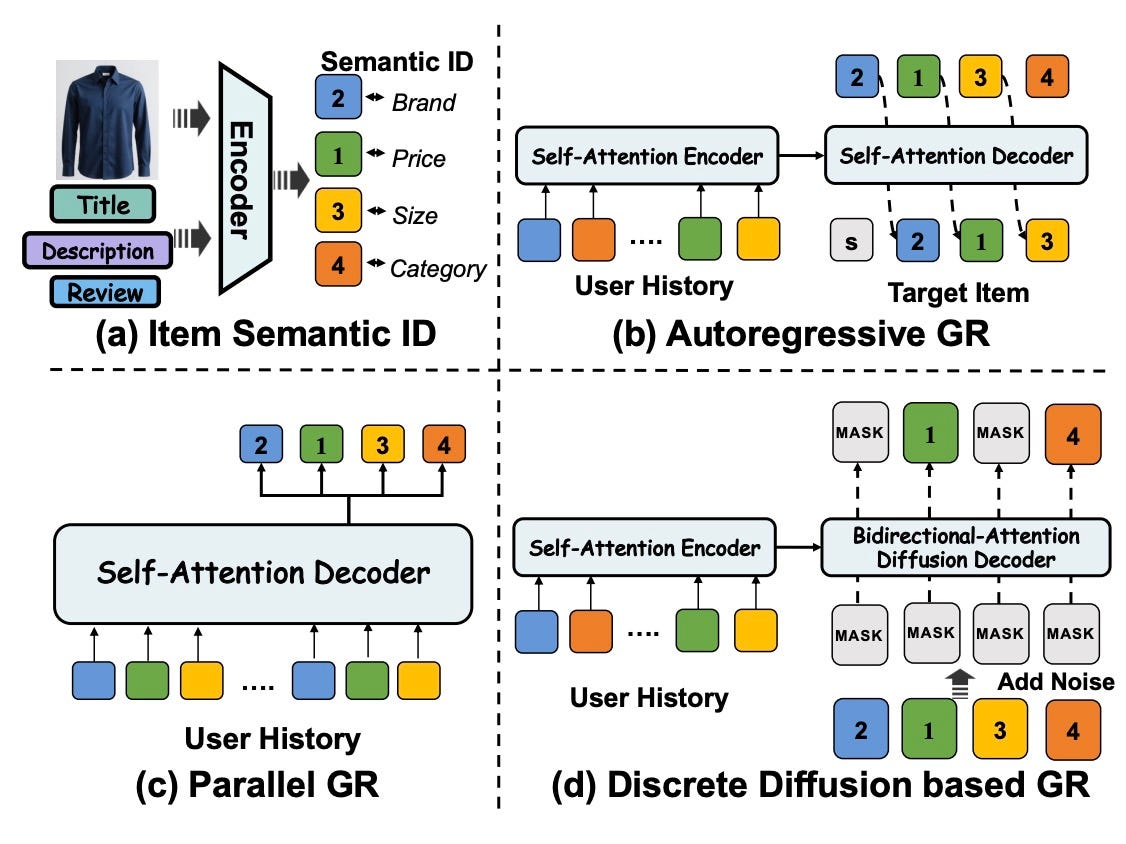
Masked Diffusion Generative Recommendation (MDGR) Alibaba reframes recommendation as masked diffusion. Instead of predicting the next item in a sequence, the model fills in blanks across your entire history at once. Why it matters: Looking at the whole picture beats the tunnel vision of autoregressive prediction. Paper
- Proving unified next-token prediction works for multimodal tasks. Nature
- ReGuLaR: Reducing chain-of-thought cost with variational latent reasoning. Hugging Face
- DreamActor-M2: Universal character animation via spatiotemporal in-context learning. Hugging Face
VibeTensor: An LLM-generated deep learning stack. Paper
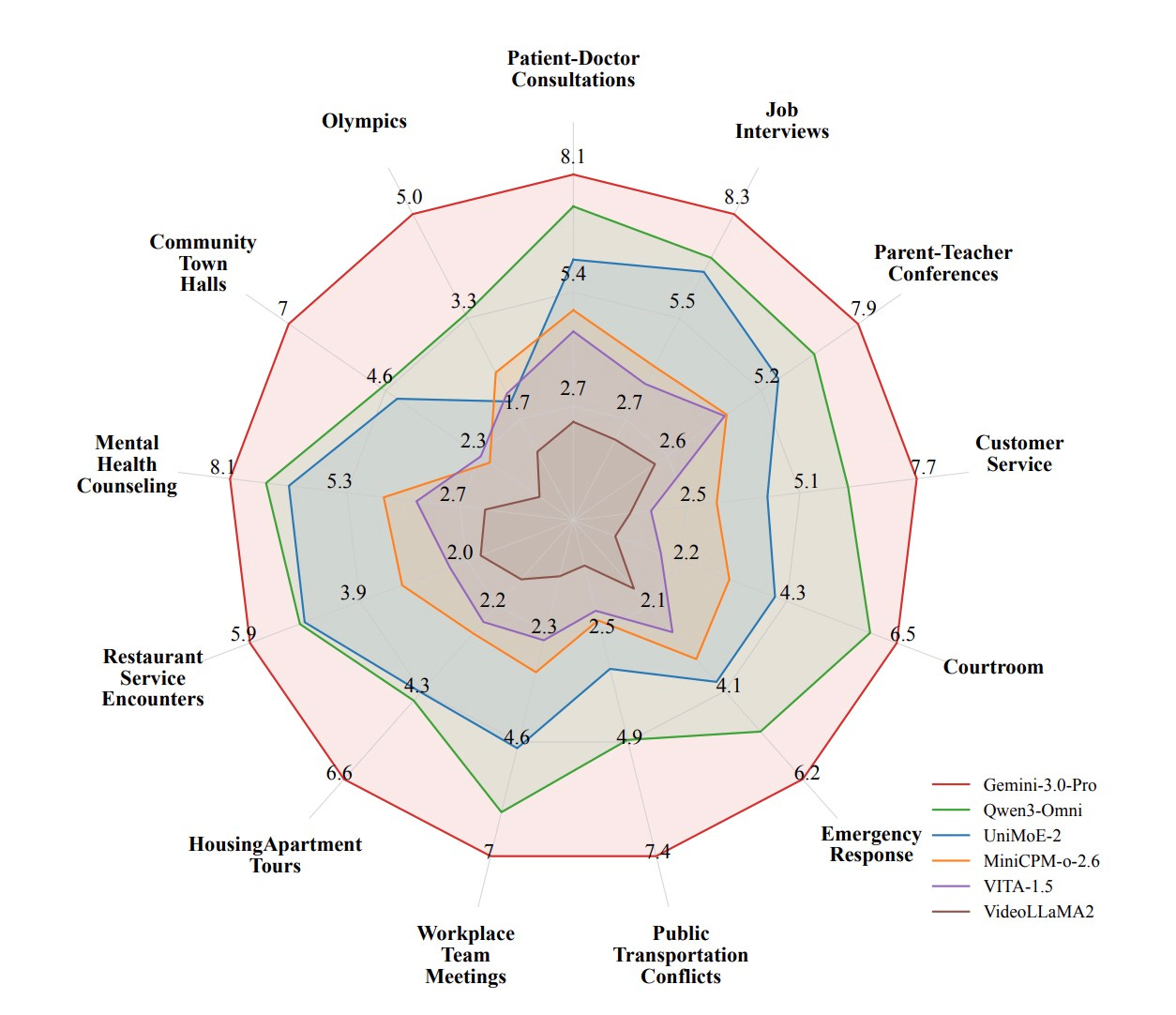
SONIC-O1: A benchmark for audio-video understanding in MLLMs. Hugging Face
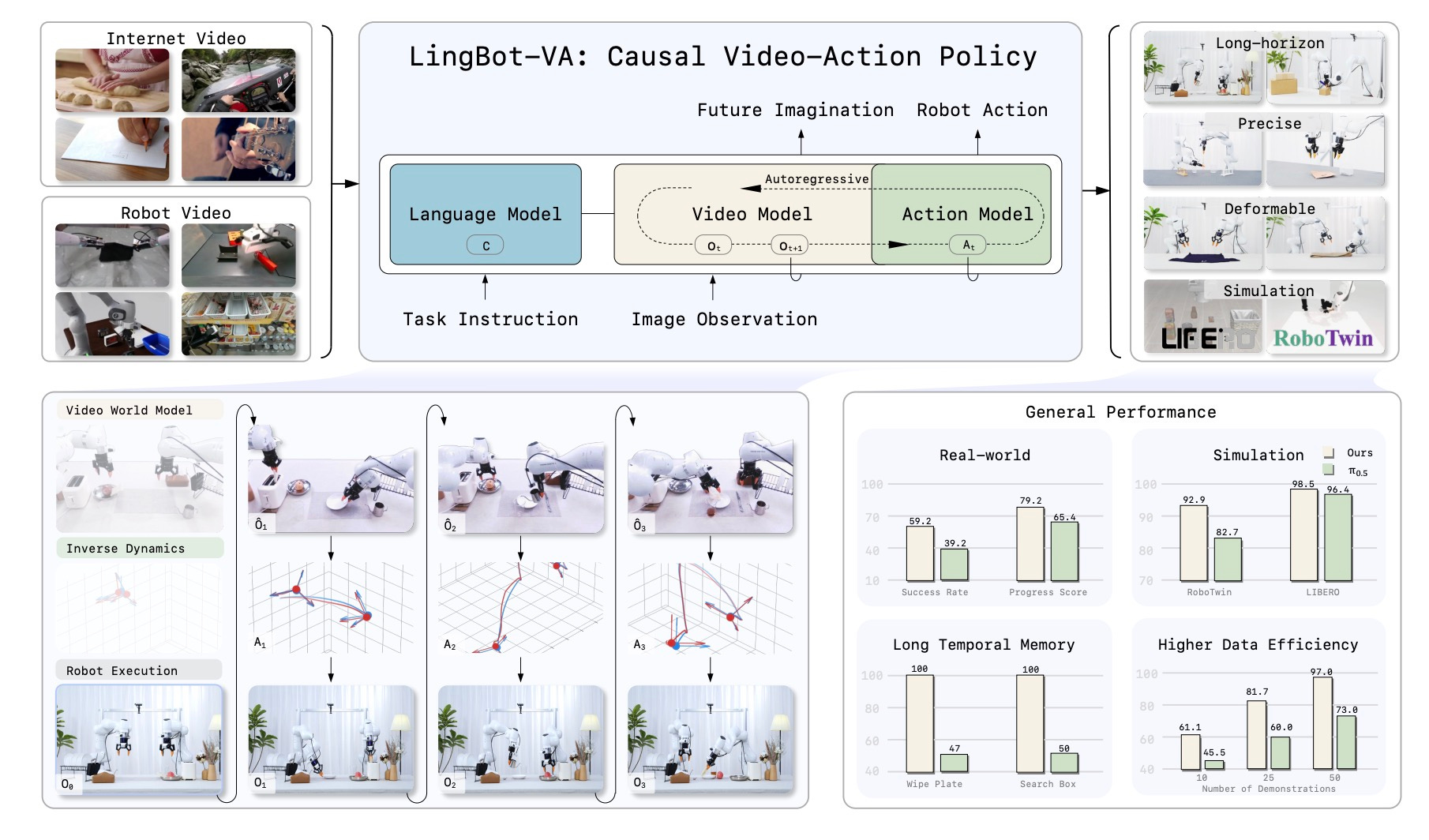
LingBot-VA: Causal world modeling for robot control. Hugging Face
📈 Trends & Predictions
Vision Becomes Active
Google’s Agentic Vision and Kimi K2.5 treat images as territory to explore. They zoom, pan, and run analysis code instead of accepting a fixed frame.
Why this matters:
- Resolution limits disappear. You can’t feed infinite pixels into a transformer. Active vision lets models look only at what’s relevant, similar to how your eyes work.
- Deep inspection becomes possible. “Find the hairline fracture in this X-ray” or “read the fine print on this contract” are now viable tasks.
- Vision is now tool use. The model learns how to look, not just what to describe.
World Models Are Becoming Simulators
EgoWM, LingBot-World, and Project Genie share a common thread: AI as simulation engine. These models don’t just generate video frames. They model physics, causality, and object permanence.
This matters for three reasons:
- Robots need infinite training gyms. Real-world training is slow and dangerous. World models provide unlimited simulated practice.
- Games adapt to players. Project Genie hints at a future where games generate their physics and rules based on what you do, not pre-authored content.
- Prediction enables safety. For autonomous systems like Drive-JEPA, a world model lets the car imagine dangerous futures and avoid them.
🧩 Community + Shoutouts
- LTX-2 LoRA: Shoutout to MachineDelusions for the open-source Image-to-Video adapter LoRA for LTX-2. Useful for experimenting with video style transfer. Hugging Face
- Genie 3 Tips: Thanks to fofr for sharing tips and a video demo for Genie 3. Good to see people stress-testing these world models. X Post
- OwlerLite: Honorable mention to the SearchSim team for OwlerLite, a browser-based RAG system with source freshness controls. A multimodal version would be interesting. GitHub

That's a wrap for Multimodal Monday #43! From Agentic Vision and Kimi K2.5 treating images as territory to explore rather than static inputs, to EgoWM and Project Genie simulating physics and consequences instead of just predicting pixels, to VibeTensor writing infrastructure code that used to require specialized engineers, this week shows multimodal AI shifting from passive perception to active intervention across every layer of the stack.
Ready to build multimodal solutions that actually work? Let's talk