Scaling Video Processing with Celery and Render
Build a scalable, distributed video processing pipeline using celery and render with fastapi

At Mixpeek, we've develoed a highly scalable and fault-tolerant video understanding pipeline capable of processing thousands of videos concurrently. Our system leverages Celery workers, FastAPI, AWS S3, AWS Sagemaker, and Render for deployment to create a distributed processing architecture that ensures reliability and efficiency. This article will dive into the technical details of our implementation, providing insights and code snippets to help you replicate our setup.
System Architecture Overview
Our video processing pipeline consists of the following key components:
- FastAPI endpoint for video upload
- S3 storage for uploaded videos
- Celery tasks for distributed processing
- Custom video chunking and embedding services
- Database storage for processed video segments
- Render for deployment and scaling
- Redis for caching and as a message broker
Here's a visual representation of our system architecture:
This architecture allows us to efficiently handle video uploads, process them in a distributed manner, and store the results for further use.
Deployment Stack on Render
Our production deployment on Render consists of the following components:
Redis Cache: Serves as a message broker for Celery and provides caching capabilities.
API Service: Handles API requests, including the video upload endpoint.
Celery Workers: Two separate background worker services for processing tasks.
This setup allows us to scale our video processing pipeline horizontally by adding more Celery workers as needed.
FastAPI Upload Endpoint
The entry point of our pipeline is a FastAPI route that handles video uploads:
@router.post("/upload")
async def index_upload(
request: Request,
file: UploadFile = File(...),
collection: str = Form(...),
metadata: str = Form(default=None)
):
# ... (file handling and metadata extraction)
s3_response = upload_file_to_s3(content_io, file_id, request.index_id, collection)
input_data = ProcessInputData(**{
"index_id": request.index_id,
"source": "upload",
"file_id": file_id,
"file_ext": file_extension,
"s3_response": {
**s3_response.dict()
},
"collection": collection,
"metadata": metadata_dict
})
task = process_file.delay(input_data.dict())
return {"message": "File upload processing started", "task_id": task.id}
This endpoint:
- Accepts video uploads and metadata
- Uploads the video to S3
- Creates a ProcessInputData object with relevant information
- Queues a Celery task for processing
Celery Task Definition
We use a shared Celery task to process the uploaded videos:
@shared_task(
bind=True,
name="managed.tasks.process_file",
max_retries=3,
default_retry_delay=5,
)
def process_file(self, input_data: dict):
processor = FileProcessor(input_data)
processor.task_id = self.request.id
processor.process()
The @shared_task decorator offers several advantages over @task:
- It allows the task to be used by multiple Celery apps
- It provides better integration with Django (if used)
- It offers more flexibility in task registration and discovery
The task is configured with:
max_retries=3: Automatically retries the task up to 3 times in case of failuredefault_retry_delay=5: Waits 5 seconds between retry attempts
Video Processing Pipeline
The core of our video processing is handled by the FileProcessor class:
class FileProcessor:
def process(self):
try:
self.initialize_file()
self.handle_file_source()
self.process_file()
self.finalize_file()
except Exception as e:
self.handle_error(e)
raise
This class orchestrates the entire processing pipeline, including error handling and cleanup.
Video Chunking and Embedding
The heart of our video understanding pipeline lies in the process_video function:
def process_video(tmp_file_path, s3_url: AnyUrl, input_data: ProcessInputData):
video_chunker = ChunkService(
file_path=tmp_file_path,
target_size_mb=5,
auto_adjust=False
)
embed_service = VideoEmbedService(model="vuse-generic-v1")
video_segments_db = VideoSegmentsDBService(input_data.index_id)
batch_size = 10 # Process 10 chunks at a time
temp_dir = tempfile.mkdtemp()
try:
batch = []
for i, video_chunk in enumerate(video_chunker.process_video()):
# Process each chunk (embedding, metadata extraction, etc.)
# ...
if len(batch) >= batch_size:
process_batch(batch, video_segments_db, temp_dir, i // batch_size)
batch = []
# Process any remaining chunks
if batch:
process_batch(batch, video_segments_db, temp_dir, (i + 1) // batch_size)
finally:
# Clean up temporary files
# ...
Key components:
ChunkService: Splits videos into manageable chunksVideoEmbedService: Generates embeddings for each chunk, using our vuse-generic-v1 embedding model hosted on AWS SagemakerVideoSegmentsDBService: Stores processed video segments- Batch processing: Processes chunks in batches for efficiency
The ChunkService is responsible for splitting the video into smaller, processable chunks:
def process_video(self):
self.initialize_video()
chunk_count = 0
while True:
temp_video_path = os.path.join(self.temp_dir, f"chunk_{chunk_count}.mp4")
frames_written = self._write_chunk_to_disk(temp_video_path)
if frames_written == 0:
break
base64_string = self._create_base64_from_file(temp_video_path)
start_time, end_time = self._calculate_time_intervals(frames_written)
chunk_object = {
"base64": base64_string,
"start_time": start_time,
"end_time": end_time
}
yield chunk_object
os.remove(temp_video_path)
chunk_count += 1
self.cap.release()
This generator-based approach allows for efficient memory usage when processing large videos.
Scaling with Celery on Render
To scale our video processing pipeline, we use Celery workers deployed on Render. Here's how we've set up and run our Celery workers:
-A db.service.celery_app: Specifies the Celery app instance--loglevel=info: Sets the logging level-n worker1@%h: Names the worker (replaceworker1with a unique name for each worker)-c 4: Sets the number of concurrent worker processes to 4- Redis as Message Broker and Result Backend:
We use a Redis instance on Render as both the message broker and result backend for Celery. This setup ensures efficient task distribution and result storage. - Additional Disk Space:
Our Celery workers are configured with additional disk space on Render to handle temporary storage of video chunks and processing artifacts. - Scaling Workers:
By using multiple Celery worker instances (celery_1 and celery_2), we can easily scale our processing capacity. We can add more worker instances on Render as needed to handle increased load. - Monitoring:
Our dashboard service, also deployed on Render, allows us to monitor the performance and status of our Celery workers and overall pipeline.
Celery Worker Configuration:
We've deployed two Celery worker instances (celery_1 and celery_2) as Background Worker services on Render. Each worker is configured with the following command:
celery -A db.service.celery_app worker --loglevel=info -n worker1@%h -c 4
Key components of this command:
Celery Configuration
To use Redis as the message broker and result backend, our Celery configuration (celeryconfig.py) looks like this:
broker_url = 'redis://your-redis-url:6379/0'
result_backend = 'redis://your-redis-url:6379/0'
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
timezone = 'UTC'
enable_utc = True
End Result: Video Understanding Demo for Advertisers
The true power of Mixpeek's video processing pipeline becomes evident when we look at its practical applications. Let's explore how our system processes thousands of social media videos for scene understanding, particularly benefiting the advertising sector.
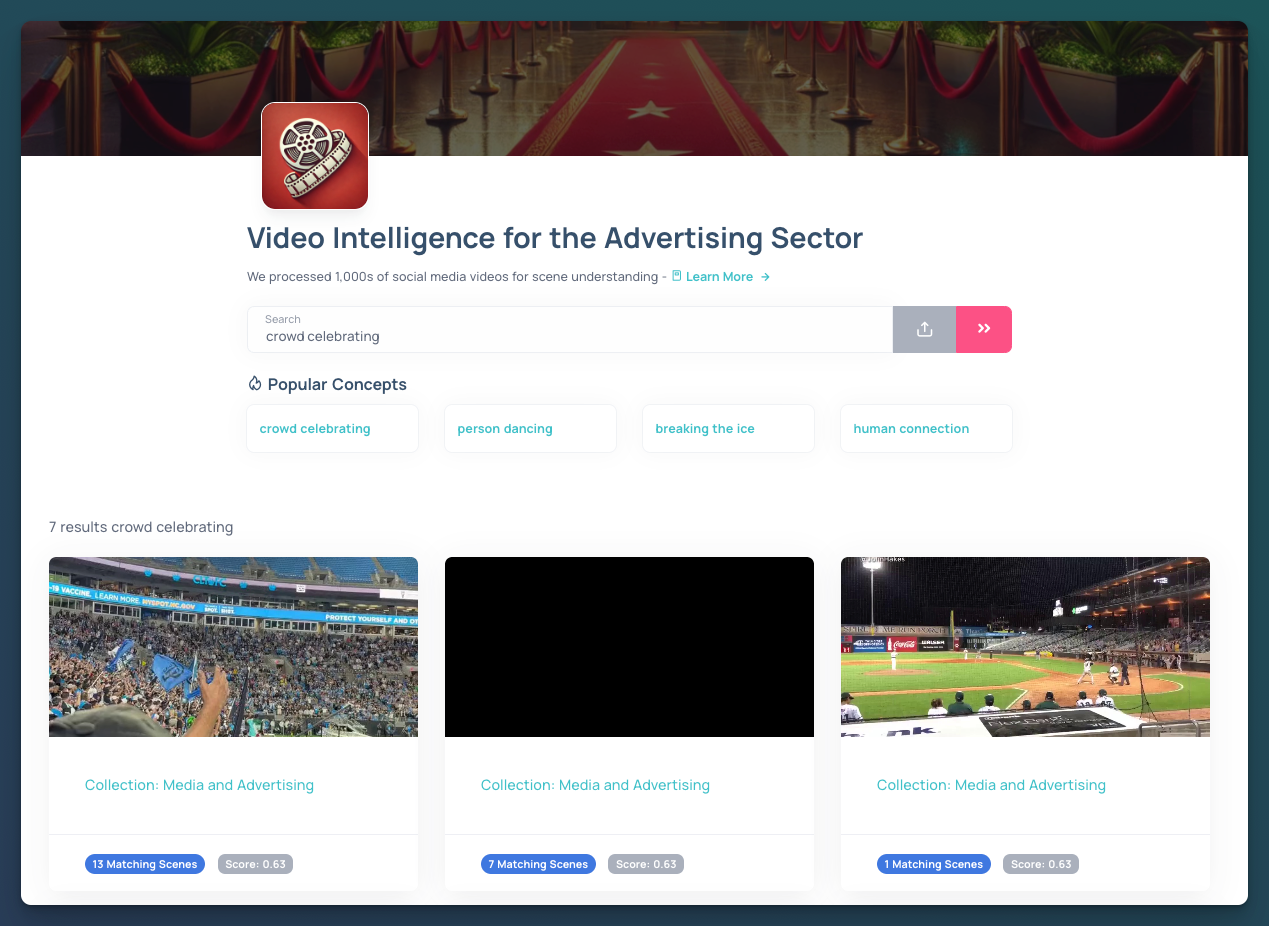
Video Intelligence for Advertising
Our demo showcases the processing of numerous social media videos, extracting key concepts and scenes that are valuable for advertisers.
Here's what the end result looks like:
- Concept Extraction: The system identifies popular concepts within videos, such as:
- Crowd celebrating
- Person dancing
- Breaking the ice
- Human connection
- Scene Matching: For each concept, the system provides:
- The number of matching scenes
- A relevance score (e.g., Score: 0.63)
- The collection the video belongs to (e.g., Media and Advertising)
Integration and Accessibility
Advertisers can easily integrate this video intelligence into their existing workflows:
- One-Line Integration: Integrate your S3 bucket directly or bake the Mixpeek SDK into your code
- Real-Time Updates: The system keeps embeddings fresh by syncing with the client's database, ensuring up-to-date video understanding.
- Exploration Interface: A user-friendly interface allows advertisers to explore processed videos, search for concepts, and visualize matches.
Conclusion
Mixpeek's video processing pipeline demonstrates how to leverage Celery, FastAPI, and custom services to create a scalable and robust system for handling thousands of videos. Our deployment on Render, utilizing multiple Celery workers and a Redis cache, allows for efficient scaling and management of the processing load.
Key takeaways:
- Use FastAPI for efficient upload handling
- Leverage Celery for distributed task processing
- Implement custom services for video chunking and embedding
- Process videos in batches for improved efficiency
- Use S3 for reliable storage of uploaded videos
- Implement proper error handling and retries
- Deploy on a scalable platform like Render
- Utilize Redis for efficient task queuing and result storage
- Scale horizontally by adding more Celery workers as needed
By following these principles and adapting the provided architecture and code snippets, you can build a similar system capable of processing large volumes of video content without failure or droppage, while maintaining the flexibility to scale as your processing needs grow.