Video Segmentation: Unlocking Structure for Search and Analytics
Segmentation turns raw video into searchable chunks—objects, actions, scenes—boosting precision in multimodal search. It bridges unstructured content with structured queries like “man falling in warehouse,” enabling faster, more accurate retrieval across large datasets.

How OpenCV, SAM, XMem, and transformers reshape video processing for analytics, retrieval, and intelligent applications.
What is Video Segmentation?
Video segmentation is the process of partitioning video content into meaningful components based on objects, motion, activities, or semantic meaning. It transforms unstructured video streams into structured, searchable, and analyzable data, forming a foundational layer for intelligent video understanding systems.
Why Segmentation is Crucial for Multimodal Search (and Why Embeddings Alone Aren't Enough)
A common question arises: "Why bother segmenting? Can't we just embed the whole video?" While powerful embedding models can capture the presence of objects or concepts within a video (e.g., "there's a ball," "it's a street scene"), they inherently compress information and struggle with specificity – the where, when, and how entities interact.
Embedding provides compression. Segmentation provides structure.
Segmentation breaks down video into discrete, meaningful units—objects, actions, scenes. This allows for fine-grained search and analysis. Instead of querying entire videos, users can target specific segments like "a person falling while holding a red bag" or "the moment the blue car overtakes the white van."
Consider the analogy to Natural Language Processing (NLP): you could embed an entire book, but finding the third sentence in chapter 5 referencing "helium balloons" would be nearly impossible. Tokenization breaks text into words or sub-words; similarly, segmentation breaks video into atomic, meaningful units that are:
- Time-bounded: Occurring within specific start and end times.
- Object-specific: Associated with particular instances (e.g.,
player_Avs. justplayer). - Indexable: Can be tagged, classified, embedded, and retrieved individually.
This granular structure drastically improves retrieval precision, especially when combined with multimodal inputs (text, image, audio). By isolating and indexing relevant parts, segmentation becomes the backbone for navigating noisy, high-volume visual data.
💬 The "Cup Shuffle" Clarification:
A frequent counter-argument is: "Segmentation won't help track the ball under three shuffling cups." This is correct, but it misses the point. Segmentation itself isn't designed to solve complex temporal reasoning or state-tracking problems. Its role is to identify and isolate the entities (cup_1, cup_2, cup_3, ball) that tracking or reasoning algorithms need as input.
- Without segmentation: Track a blur.
- With segmentation: Track defined objects with clear boundaries and identities.
Segmentation doesn't solve temporal logic; it enables it by providing the structured primitives required for downstream tasks.
Composability: Segmentation + Embedding + Downstream Logic
Segmentation unlocks modular and composable video processing pipelines. By identifying relevant segments first, you can:
- Reduce noise: Apply expensive embedding models only to relevant objects or time intervals, not entire frames.
- Enable targeted analysis: Extract features (embeddings, poses, actions) specifically for segmented entities.
- Improve efficiency: Avoid redundant processing of static backgrounds or irrelevant information across frames.
- Build flexible systems: Create pipelines where different modules (segmentation, tracking, embedding, action recognition) handle specific tasks and can be updated independently.
Example: Basketball Analysis
- Segment: Identify and isolate each player and the ball.
- Track: Follow each player's movement across frames.
- Embed/Analyze: Extract pose estimations for segmented players, classify actions (dribble, pass, shot), and link
player_Xto external stats. - Index: Store segments tagged with player ID, action type, and timestamp (e.g., "jump shots by Player X").
Without segmentation, you'd need computationally heavy models running on full frames, making fine-grained analysis inefficient and fuzzy.
🧩 Modular Routing: The Multimodal ETL Switchboard
Segmentation acts as an intelligent routing layer. Once video is sliced into semantic units (objects, actions), each segment can be directed to the most appropriate downstream model:
- Person Segment: Route to Face Recognition, Pose Estimation, or Gait Analysis models.
- Car Segment: Route to License Plate Recognition or Damage Detection models.
- Action Segment ("Falling"): Route to an Event Classification or Alerting system.
- Product Segment: Route to a Visual Similarity model for related product search.
This creates a flexible "multimodal ETL (Extract, Transform, Load)" switchboard where specialized models handle specific data types, rather than relying on a single, monolithic model for everything.
⚖️ End-to-End Models vs. Modular Pipelines
Some argue that modular pipelines risk compounding errors (e.g., if the segmentation model fails, subsequent steps are affected). While this is a valid concern, modular approaches offer significant advantages:
- Observability: Easier to debug and understand which part of the pipeline failed.
- Customizability: Swap or fine-tune individual components (e.g., upgrade the segmentation model) without retraining the entire system.
- Efficiency: Use specialized, potentially lighter-weight models for specific tasks.
- Error Management & Enhanced Accuracy: Later stages can potentially filter or correct errors from earlier stages. Errors are not always strictly additive.
Segmentation isn't a crutch; it's a powerful intermediate representation—a form of visual tokenization—that enhances the flexibility, interpretability, and efficiency of the entire video processing stack.
🧠 Bonus: Redundancy + Consensus in Modular Pipelines
One key benefit of modular video pipelines is the ability to apply redundancy and consensus algorithms—much like distributed systems do—to increase reliability without retraining models.
By running multiple, uncorrelated models for a single task (e.g., fall detection) and using quorum + consensus thresholds, we can reduce the chance of error to near-zero.
For example, requiring all three models to agree reduces error probability to the product of their individual error rates (e.g., 0.1 × 0.2 × 0.15 = 0.003).
This allows pipelines to optimize for both cost and accuracy: start with cheaper models, escalate only when needed, and still meet high precision requirements.
Modular = Composable + Observable + Controllable
Once your pipeline slices a video into discrete semantic units, each segment can be routed to the most appropriate model for deeper understanding:
| Segment Type | Destination Model | Purpose |
|---|---|---|
| Person’s face/head | InceptionResNetV1 (via facenet-pytorch) |
Face verification, embedding for person re-ID |
| Speech audio chunk | Wav2Vec2 |
Speech-to-text, speaker diarization |
| Scene frame | BLIP-2, GIT, GPT-V |
Captioning, visual Q&A, multimodal grounding |
| Pose estimate | OpenPose, MoveNet |
Physical action classification, ergonomics |
| Object bounding box | CLIP or ImageBind |
Embedding for similarity, search, or linking |
| Entire action span | VideoMAE, TimesFormer, MTTR |
Complex temporal modeling (e.g., “fall detection”, “goal scored”) |
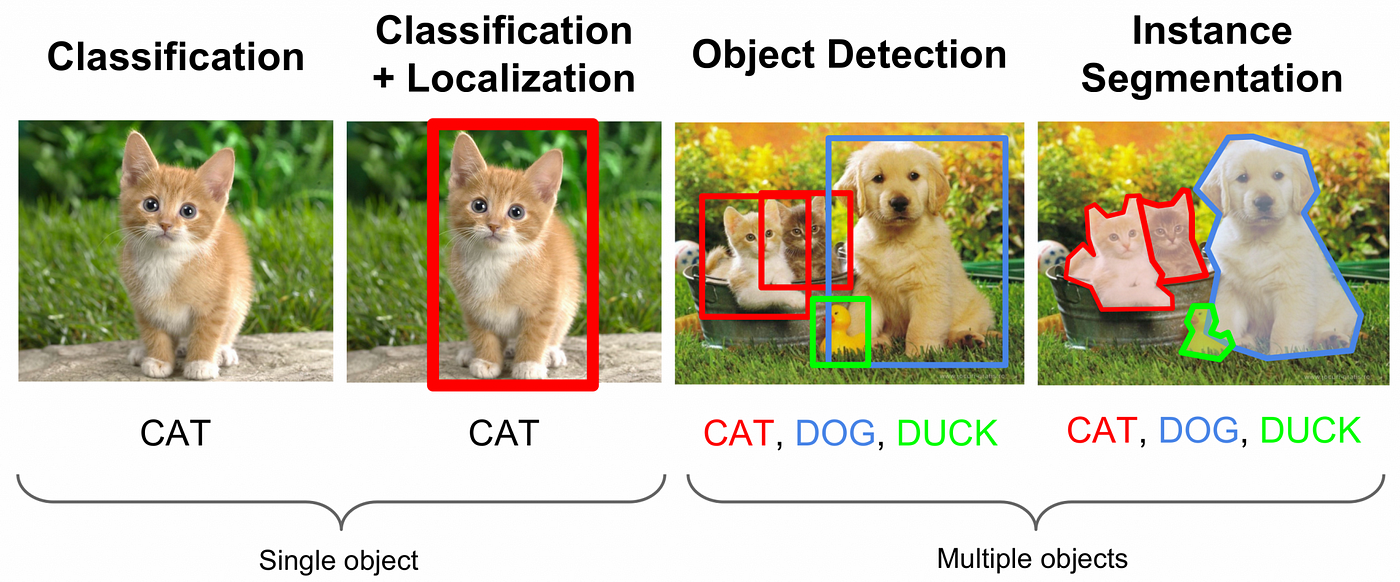
Types of Video Segmentation
Different tasks require different segmentation approaches:
- Video Object Segmentation (VOS): Tracks specific object instances across frames, maintaining identity even through occlusion or appearance changes. Essential for multi-camera surveillance, sports replays, and person re-identification.
- Video Semantic Segmentation (VSS): Assigns a semantic label (e.g., 'road', 'car', 'sky', 'person') to every pixel in each frame. Used heavily in autonomous driving, augmented reality, and environmental scene understanding.
- Video Instance Segmentation: Distinguishes and labels each individual instance within a class (e.g.,
person_1,person_2, not just 'person'). Useful for crowd analysis, multi-object tracking in sports, and retail behavior mapping.
The OpenCV Era: Classical Foundations
Before deep learning dominated, classical computer vision techniques provided the first wave of segmentation capabilities:
- 🛠️ Techniques:
- Frame Differencing: Subtracting consecutive frames to detect motion. Simple but sensitive to noise and camera movement. Best for static camera setups.
- Background Subtraction: Modeling a scene's static background over time and subtracting it to isolate moving foreground objects (e.g., OpenCV's MOG2, KNN methods).
- Optical Flow: Estimating motion vectors between frames (e.g., Lucas-Kanade, Farneback algorithms) to identify regions with coherent movement.
- 📷 Use Cases:
- Basic CCTV motion detection and alerting.
- Simple traffic monitoring (counting vehicles).
- Robotics (separating objects from static backgrounds).
- ✅ Limitations: These methods are lightweight and fast but struggle with dynamic lighting, camera motion, complex scenes, camouflage, and significant appearance changes.
Deep Learning Revolutionizes Segmentation
Deep learning models dramatically improved segmentation quality and robustness:
- 🧠 Evolution:
- Per-frame Segmentation: Early approaches applied image segmentation CNNs (like U-Net, DeepLab) to each video frame independently. This produced high-quality masks but lacked temporal consistency, leading to flickering or disjointed segments over time.
- Temporal Propagation: Models like OSVOS, STM, and MaskTrack incorporated temporal information, propagating masks from one frame to the next using optical flow or feature matching.
- Memory-based Models: Architectures like XMem introduced memory components (inspired by human cognition) to store appearance and location information over longer durations, improving handling of occlusions and reappearance.
- Transformers: Attention mechanisms, particularly in transformer architectures, enabled models to capture long-range spatial and temporal dependencies more effectively.
- 📊 Limitations Addressed:
- Temporal Inconsistency: Modern methods produce smoother, more stable masks across frames.
- Object Drift & Identity: Better handling of occlusions, scale changes, and maintaining object identity over time.
- Re-identification: Improved ability to re-associate objects after they disappear and reappear.
![Bounding box vs. instance segmentation on players and ball objects [4] | Download Scientific Diagram](https://www.researchgate.net/publication/340983355/figure/fig1/AS:885364575199232@1588098772405/Bounding-box-vs-instance-segmentation-on-players-and-ball-objects-4.jpg)
State-of-the-Art (SOTA) Video Segmentation Approaches
Several models and concepts represent the cutting edge:
- 🎯 Segment Anything Model (SAM) & SAM 2:
- Foundation Model: SAM (and its successor SAM 2) are trained on massive datasets (1B+ masks for SAM) to perform promptable image segmentation (via points, boxes, masks, or text).
- Zero-Shot Generalization: Works well out-of-the-box on diverse objects and scenes without specific training.
- Video Adaptation: SAM itself processes single images. For video, it's typically combined with tracking algorithms or temporal propagation techniques (like Track Anything) to achieve VOS.
- Note: SAM 2 aims to improve upon SAM with enhanced interactive segmentation and automatic mask generation. (SAM 2 GitHub)

 facebookresearch
facebookresearch- 🧬 XMem:
- Memory-Based VOS: Uses a hybrid short-term/long-term memory model (inspired by Atkinson-Shiffrin) to track objects robustly over long videos.
- Class-Agnostic: Can track any object given an initial mask, without needing to know its category.
- Efficiency: Optimized for speed, enabling near real-time performance. (XMem GitHub)
hkchengrexEvaluating Segmentation Performance
Key metrics used to assess video segmentation quality include:
- Jaccard Index (Intersection over Union - IoU / J): Measures the overlap between the predicted mask and the ground truth mask for a single object.
- Mean IoU (mIoU): Average IoU calculated across all objects or classes in a video or dataset.
- Boundary F-measure (F): Measures the accuracy of the predicted mask boundaries.
- MOTA (Multi-Object Tracking Accuracy): Primarily for tracking, considers false positives, false negatives (missed targets), and identity switches.
ETL with Video: Segmentation in the Data Stack
Segmentation transforms raw video into structured data suitable for standard data processing workflows (Extract, Transform, Load):
- Extract: Use segmentation models (VOS, VSS, Instance) to identify and isolate relevant segments:
- Objects: People, cars, products, animals.
- Actions/Events: Falling, jumping, specific interactions.
- Scenes: Kitchen, warehouse, operating room.
- Transform: Process these segmented chunks to enrich them with metadata:
- Extract embeddings (e.g., using CLIP, BLIP) for similarity search on segments.
- Add classifications, tags (e.g., "person wearing helmet," "product demo").
- Perform downstream analysis: face detection, pose estimation, text extraction (OCR) within segments.
- Generate textual summaries or descriptions of segment content.
- Load: Store the structured segment data and metadata into appropriate databases for querying:
- Vector Databases: For semantic similarity search on segment embeddings.
- SQL/NoSQL Databases: For filtering based on metadata (time, object class, tags).
- Graph Databases: For modeling complex temporal relationships or interactions between segmented entities.
Mixpeek: One-Click Segmentation for Real-World Pipelines
Integrating and managing state-of-the-art segmentation models can be complex. Platforms like Mixpeek provide pre-built "extractors" that plug modern segmentation capabilities directly into your data pipelines without requiring deep ML expertise.
- 🔍 Extractors:
- Object Grouping: Segments, tracks, and groups every object instance across its appearances in the video. Use case: "Find every clip showing
product_sku_123." https://mixpeek.com/extractors/object-grouping - Activity Grouping: Detects and segments temporal activities like "falls," "goals," "fights," or custom events. Use case: "Automatically flag all instances of 'near miss' incidents in safety footage." https://mixpeek.com/extractors/activity-grouping
- Object Grouping: Segments, tracks, and groups every object instance across its appearances in the video. Use case: "Find every clip showing
- 🎥 Input/Output: Feed in video, receive structured JSON output describing segments, their properties, and associated metadata.
🧠 Example Output:
{
"segment_id": "seg_12345",
"type": "object_appearance", // or "activity"
"label": "player_1", // or "jump shot"
"start_time_sec": 10.3,
"end_time_sec": 12.1,
"bounding_boxes": [ ... ], // per frame
"mask_pointers": [ ... ], // optional, pointers to mask data
"embedding": [0.15, -0.32, ...], // embedding of the segment
"confidence": 0.92,
"attributes": {
"track_id": "track_abc"
}
}
Industry Applications Powered by Segmentation
Segmentation unlocks value across numerous domains:
- 🔐 Surveillance & Security:
- Track individuals across multiple camera views (re-identification).
- Set up alerts for restricted zone entry or policy violations (e.g., missing safety gear).
- Enable forensic search: "Show me everywhere person X went between 2 PM and 3 PM."

- ⚽ Sports Analytics:
- Automatically segment and tag key events (goals, fouls, assists).
- Track player movements for generating heatmaps, possession statistics, and tactical analysis.
- Train classifiers on segmented actions to find highlights or specific plays.
- 🛍️ E-commerce & Retail:
- Segment products within influencer videos or user-generated content.
- Identify moments when a product is actively used or demonstrated.
- Power visual search: "Find other videos featuring jackets similar to this one."
- Analyze in-store shopper behavior by tracking paths and interactions.
- 🎬 Media & Entertainment:
- Automate rotoscoping for visual effects by segmenting actors or objects.
- Break down raw footage into scenes or shots for easier editing and logging.
- Detect and index recurring characters, logos, or locations across large archives.
- 🚗 Autonomous Driving & Robotics:
- Real-time segmentation of lanes, vehicles, pedestrians, and obstacles for navigation.
- Fuse data from multiple sensors (LIDAR, RGB cameras) using segmentation.
- Automate the annotation of large datasets for training perception models.
Future Trends
The field continues to evolve rapidly:
- Temporal SAM: Research focuses on extending foundation models like SAM with temporal consistency and memory for true video segmentation capabilities out-of-the-box.
- Multimodal Segmentation: Integrating audio cues (speaker diarization, sound events), text (subtitles, scene descriptions), and motion patterns for more context-aware segmentation.
- Efficiency & Real-time Performance: Development of lightweight architectures (e.g., MobileSAM, FastViT adaptations) for on-device deployment on phones, drones, AR/VR headsets.
- Interactive & Refinable Segmentation: Tools allowing users to easily correct or refine segmentation masks interactively, improving data quality for training and analysis.
The Takeaway: Structure is Key
Video segmentation has matured from a niche academic problem into a core enabling technology for understanding and interacting with video data at scale. It provides the essential structure needed to bridge the gap between raw pixels and actionable insights.
Whether building systems for legal discovery ("Who was holding the product?"), construction site safety ("Where are the workers without hardhats?"), media archiving ("Find every scene with actor Y speaking"), or any other domain dealing with video, segmentation provides the necessary temporal and object-level granularity.
Platforms like Mixpeek abstract the underlying complexity, allowing developers and data teams to leverage powerful segmentation capabilities through simple APIs, much like using a SQL filter on structured data.
Ultimately, if you need to search, analyze, or reason about specific things happening at specific times within video, you need segmentation.
Next Steps
- Explore Mixpeek's segmentation extractors: https://mixpeek.com/extractors
- Watch demos and tutorials: https://mixpeek.com/education/videos
- Learn about building video pipelines: https://mixpeek.com/recipes
👋 Want help integrating video segmentation into your product?
- Book a demo: https://mixpeek.com/demo