See the full diagram →
Two Retrievers That Disagree On Everything
When an AI agent searches unstructured content, the searchable surface is rarely raw pixels or waveforms. It is the text a perception layer extracted: transcripts from speech, OCR from frames and documents, captions from scenes, detected labels. Over that text, two retrievers are good at different things and bad at each other's strengths.
A dense retriever embeds the query and each chunk into a vector and ranks by cosine similarity. It is strong on meaning: it matches "quarterly revenue" to "Q3 earnings" even with no shared words. It is weak on rare exact terms: a part number like "RX-4490B", a person's surname, a promo code, or an unusual acronym can be smeared into the nearest semantic neighborhood and lost.
A lexical retriever (BM25 over an inverted index) ranks by term overlap with frequency and length normalization. It is strong on exact terms: "RX-4490B" matches "RX-4490B" and nothing else. It is weak on meaning: ask for "ways to reduce churn" and a document about "improving retention" scores zero because it shares no terms.
The obvious move is to use both and merge their results. That is hybrid search, and it reliably beats either retriever alone on mixed query workloads. The non-obvious part is the merge itself. The two retrievers do not just disagree on which document is best; they report confidence on scales that have nothing to do with each other, and combining them naively produces rankings that are worse than either input.
Why You Cannot Just Add The Scores
The first instinct is to add the dense score and the lexical score per document and re-sort. This is wrong, and seeing exactly why is the whole point of this guide.
The two scores live on incompatible distributions:
dense cosine: 0.61 0.74 0.80 0.83 0.88 (narrow, bounded) BM25: 0.0 2.1 3.4 9.7 24.5 (wide, unbounded, query-dependent)
Add those raw and BM25 dominates entirely; the dense signal becomes rounding noise. The ranking is effectively pure lexical, and you have paid for two retrievers to get one. Worse, the imbalance is not even fixed: it shifts per query, because BM25's scale depends on which terms the query happens to contain. There is no single constant you can multiply one side by that fixes every query.
So fusion has exactly two honest options. Either convert both signals onto a comparable scale before combining (score normalization), or throw the raw scores away and combine only the rank positions (rank fusion). Each has a precise method and a precise failure mode.
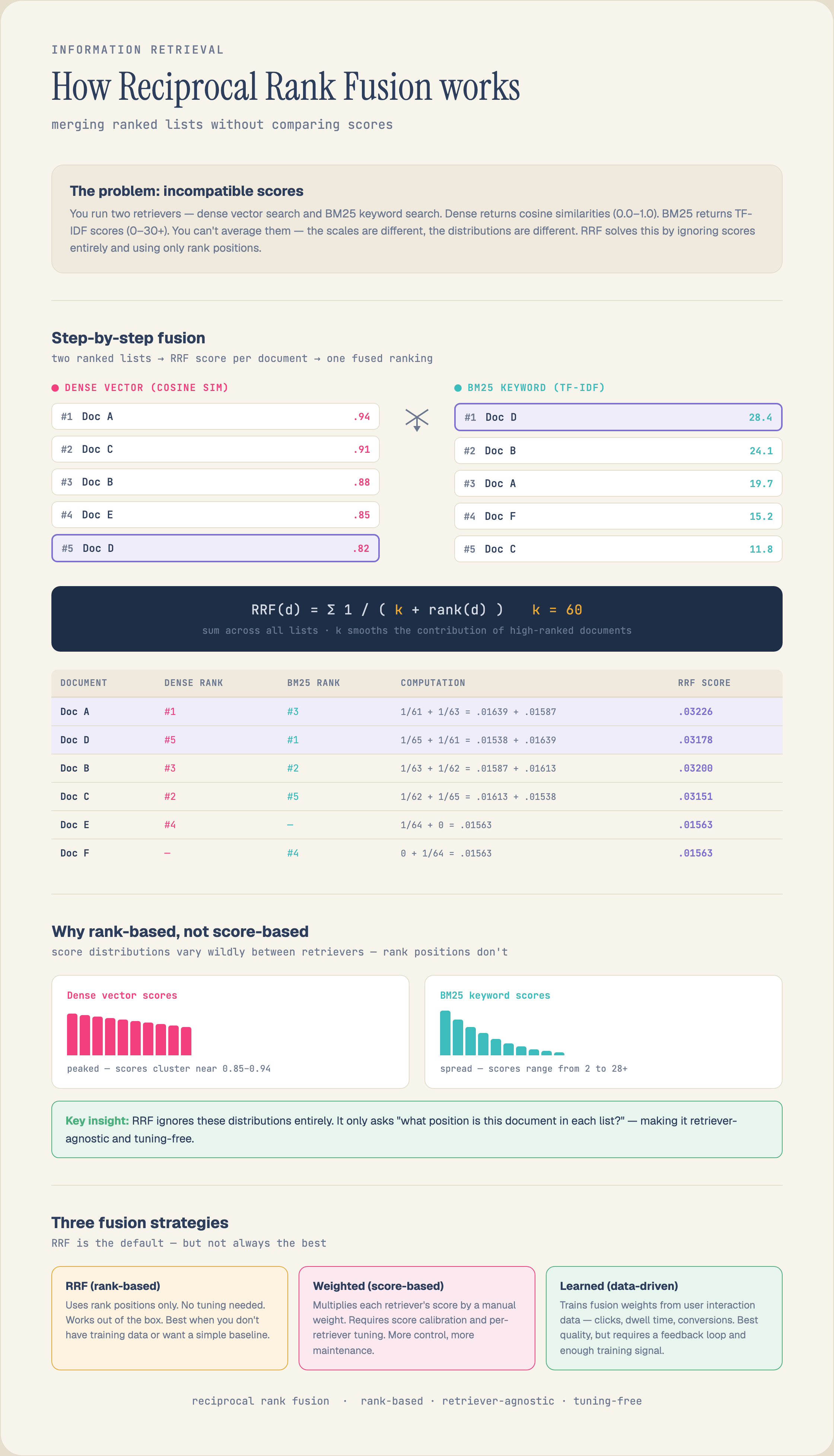
RRF sidesteps the scale problem by ignoring scores entirely and using only each document's rank position in each result list. For a document d, its fused score is the sum over every retriever of one divided by a constant k plus that retriever's rank for d.
So fusion has exactly two honest options. Either convert both signals onto a comparable scale before combining (score normalization), or throw the raw scores away and combine only the rank positions (rank fusion). Each has a precise method and a precise failure mode.
Method 1: Reciprocal Rank Fusion (RRF)
RRF sidesteps the scale problem by ignoring scores entirely and using only each document's rank position in each result list. For a document d, its fused score is the sum over every retriever of one divided by a constant k plus that retriever's rank for d.
RRF(d) = sum over retrievers r of 1 / (k + rank_r(d)) where rank_r(d) = 1 for the top hit in list r, 2 for the second, and so on. Documents missing from a list contribute nothing for that retriever.
A worked example with k = 60. A document ranked 1st by BM25 and 5th by dense:
1 / (60 + 1) = 0.01639 (BM25 contribution) 1 / (60 + 5) = 0.01538 (dense contribution) RRF score = 0.03177
A document ranked 1st by dense but absent from BM25's returned list gets only 0.01639. So a document that both retrievers rank highly beats one that a single retriever loves, which is exactly the agreement-rewarding behavior you want from a fusion rule.
The reason RRF works is that converting a score to its rank discards the incomparable magnitudes and keeps only the ordering, which is the part that is actually meaningful across different retrievers. A cosine of 0.88 and a BM25 of 24.5 are not comparable, but "this was the top result in each list" is.
k controls how steeply early ranks dominate. The contribution of rank 1 versus rank 2 is the gap between 1/(k+1) and 1/(k+2).
Small k (say 10). 1/11 = 0.0909 versus 1/12 = 0.0833. The top ranks are sharply differentiated; being first matters a lot. Good for small corpora where you trust the top of each list and want steep separation.
Large k (say 60, the value from the original RRF paper). 1/61 = 0.01639 versus 1/62 = 0.01613. The curve is flat; ranks 1 through 20 are all close, so fusion rewards broad agreement across both lists rather than letting a single retriever's number-one pin the result. Good for large corpora.
k = 60 is a tuned default, not a law. For a small candidate set (tens to low hundreds), a smaller k often ranks better because it restores the differentiation that a flat curve washes out. Treat k as a hyperparameter you tune against labels, not a constant you inherit.
RRF is unsupervised, needs no labels, and is robust to scale, which is why it is the right default in a new domain. The cost is that it is blind to margin. If dense retrieval is wildly confident the top hit is correct (0.95 versus 0.60 for the rest) and BM25 is barely above noise, RRF treats "rank 1" identically in both. It cannot know that one retriever's number-one is far more trustworthy than the other's. When you have enough labeled data to exploit that margin, a score-based method can do better.
The alternative keeps the magnitudes but fixes their scales first, then takes a weighted sum. The combination itself is simple:
The reason RRF works is that converting a score to its rank discards the incomparable magnitudes and keeps only the ordering, which is the part that is actually meaningful across different retrievers. A cosine of 0.88 and a BM25 of 24.5 are not comparable, but "this was the top result in each list" is.
The k parameter, precisely
k controls how steeply early ranks dominate. The contribution of rank 1 versus rank 2 is the gap between 1/(k+1) and 1/(k+2).
k = 60 is a tuned default, not a law. For a small candidate set (tens to low hundreds), a smaller k often ranks better because it restores the differentiation that a flat curve washes out. Treat k as a hyperparameter you tune against labels, not a constant you inherit.
What RRF gives up
RRF is unsupervised, needs no labels, and is robust to scale, which is why it is the right default in a new domain. The cost is that it is blind to margin. If dense retrieval is wildly confident the top hit is correct (0.95 versus 0.60 for the rest) and BM25 is barely above noise, RRF treats "rank 1" identically in both. It cannot know that one retriever's number-one is far more trustworthy than the other's. When you have enough labeled data to exploit that margin, a score-based method can do better.
Method 2: Score Normalization And Weighted Combination
The alternative keeps the magnitudes but fixes their scales first, then takes a weighted sum. The combination itself is simple:
final(d) = alpha * norm(dense(d)) + (1 - alpha) * norm(bm25(d))
The entire difficulty is in norm(), and the choice of normalizer is where most hybrid systems quietly go wrong.
Min-max normalization maps each list's scores to the range zero to one using that list's own min and max for the current query.
Min-max normalization maps each list's scores to the range zero to one using that list's own min and max for the current query.
norm(s) = (s - min) / (max - min)
It is intuitive and the most common choice, and it has a sharp failure mode: it is dominated by outliers. A single runaway BM25 score (the rare-term spike of 24.5) becomes 1.0 and compresses every other result toward 0, so the second-best lexical hit looks almost as bad as the worst. Min-max also forces the top of every list to exactly 1.0 and the bottom to exactly 0.0 regardless of whether that list was actually informative for this query, which manufactures false confidence on queries where a retriever returned only garbage.
Z-score (standard score) normalization recenters each list to mean zero and unit variance.
Z-score (standard score) normalization recenters each list to mean zero and unit variance.
norm(s) = (s - mean) / stddev
It is far more robust to a single outlier because one spike moves the mean and standard deviation only a little, so the rest of the list keeps its internal spacing. The trade is that z-scores are unbounded and assume a roughly symmetric distribution, which BM25's right-skewed scores violate; in practice z-score still usually beats min-max for fusion precisely because it does not let one rare-term spike flatten everything.
alpha is the dial between meaning and exact-match. alpha = 1 is pure dense, alpha = 0 is pure lexical, and the best value depends on the query mix.
Workloads heavy with conceptual, paraphrased queries ("clips about budget cuts") want higher alpha.
Workloads heavy with identifiers, names, and codes ("invoices mentioning RX-4490B") want lower alpha.
Unlike RRF's k, alpha is meaningless without normalization, because an unnormalized weighted sum just reintroduces the scale problem. And unlike RRF, weighted combination genuinely needs a labeled validation set to set alpha and pick the normalizer; tuned well on representative queries it can beat RRF, but tuned blindly it usually loses to it.
Tuning alpha
alpha is the dial between meaning and exact-match. alpha = 1 is pure dense, alpha = 0 is pure lexical, and the best value depends on the query mix.
Unlike RRF's k, alpha is meaningless without normalization, because an unnormalized weighted sum just reintroduces the scale problem. And unlike RRF, weighted combination genuinely needs a labeled validation set to set alpha and pick the normalizer; tuned well on representative queries it can beat RRF, but tuned blindly it usually loses to it.
RRF Versus Weighted: Choosing
RRF Weighted + normalization
Needs labels? No Yes (to set alpha + normalizer)
Robust to scale? Yes (ignores scores) Only after normalization
Uses score margin? No Yes
Failure mode Blind to confidence Outliers distort (min-max);
wrong alpha tanks one query type
Good default when New domain, no labels You have a labeled query setThe practical path: start with RRF because it is robust and needs nothing. Build a labeled query set (this is the expensive, valuable part, see Evaluating Multimodal Retrieval). Only once you can measure ranking quality should you try weighted fusion with z-score normalization and a tuned alpha, and keep it only if it beats RRF on held-out queries. Many production systems never leave RRF, and that is a defensible choice.
Fusion merges first-stage candidates; it does not produce the final order an agent should trust. The standard shape is three stages: each retriever returns a deep candidate list (say top 1000), fusion merges them into a single ranked list, and a cross-encoder reranks the top of that merged list with full query-document attention.
Fusion Is A Stage, Not The Finish Line
Fusion merges first-stage candidates; it does not produce the final order an agent should trust. The standard shape is three stages: each retriever returns a deep candidate list (say top 1000), fusion merges them into a single ranked list, and a cross-encoder reranks the top of that merged list with full query-document attention.
dense top-1000 ──┐
├──> fuse (RRF or weighted) ──> merged top-200 ──> cross-encoder rerank ──> top-10
BM25 top-1000 ──┘This separation of labor matters. Fusion's job is recall: make sure the right document is somewhere in the merged top-200, drawing on both retrievers so a lexical-only or semantic-only match is not dropped. The reranker's job is precision: order that short list correctly. Asking fusion to also nail the final ordering is asking the wrong stage to do the reranker's job. (The mechanics of that final stage are in Cross-Encoder Reranking, and the broader pipeline in Multi-Stage Retrieval.)
An agent does not know or care which retriever found a piece of evidence; it cares that the right evidence surfaced and is ordered sensibly. Fusion is what makes a single query draw on both meaning and exact terms so the agent does not have to issue two searches and reconcile them itself.
Both signals or silent gaps. Without lexical, an agent loses exact identifiers; without dense, it loses paraphrases. A hybrid retriever closes both gaps behind one query, so "find the clip mentioning serial RX-4490B about overheating" hits on the serial and the concept at once.
Fusion choice is a recall lever. A bad fusion rule drops correct documents before the reranker ever sees them, and a dropped document is invisible: the agent reasons over what surfaced and never knows what did not.
Tune against labels, not vibes. k, alpha, and the normalizer all change which documents reach the agent. Treat them as measured settings, not defaults you guess.
A Mixpeek retriever can run dense feature search and lexical (BM25) search as separate stages and merge them with a rank-fusion stage, so the fusion math in this guide is configuration rather than glue code an agent has to maintain.
What This Means For An Agent
An agent does not know or care which retriever found a piece of evidence; it cares that the right evidence surfaced and is ordered sensibly. Fusion is what makes a single query draw on both meaning and exact terms so the agent does not have to issue two searches and reconcile them itself.
Doing This In Mixpeek
A Mixpeek retriever can run dense feature search and lexical (BM25) search as separate stages and merge them with a rank-fusion stage, so the fusion math in this guide is configuration rather than glue code an agent has to maintain.
from mixpeek import Mixpeek
client = Mixpeek(api_key="mxp_sk_...")
# A retriever with two first-stage retrievers fused by RRF, then reranked.
client.retrievers.create(
namespace="support-video",
retriever_name="hybrid_transcript_search",
stages=[
{"stage_type": "feature_search", "stage_id": "dense",
"parameters": {"field_name": "transcript_embedding", "limit": 1000}},
{"stage_type": "feature_search", "stage_id": "lexical",
"parameters": {"field_name": "transcript_text", "method": "bm25", "limit": 1000}},
{"stage_type": "rank_fusion", "stage_id": "fuse",
"parameters": {"method": "rrf", "k": 60, "inputs": ["dense", "lexical"]}},
{"stage_type": "rerank", "stage_id": "rerank",
"parameters": {"input": "fuse", "limit": 10}},
],
)
# The agent issues one query and gets meaning + exact-term recall, fused and reranked.
results = client.retrievers.execute(
retriever_id="hybrid_transcript_search",
inputs={"text": "the clip mentioning serial RX-4490B about overheating"},
)The k = 60 in that config is the exact RRF parameter from this guide, and swapping the fusion stage to a weighted method with a tuned alpha is a configuration change once a labeled set says it wins. The agent issues one query; the retriever does the dense search, the lexical search, the fusion, and the rerank, and hands back evidence that reflects both kinds of match.
1. Dense and lexical retrieval cover each other's blind spots (meaning versus exact terms), so a hybrid of both beats either alone on mixed agent workloads.
2. You cannot add raw scores. Cosine similarity is narrow and bounded; BM25 is wide, unbounded, and query-dependent, so a naive sum collapses into pure lexical ranking.
3. RRF fuses by rank position, needs no labels, and is robust to scale; its k parameter controls how steeply top ranks dominate (small k = sharp, large k = rewards agreement).
4. Weighted combination keeps score margins but requires normalization first; prefer z-score over min-max because min-max lets a single rare-term spike flatten the rest, and tune alpha against a labeled set.
5. Fusion is a recall stage feeding a precision reranker, not the final ranking; tune k, alpha, and the normalizer with measurement, because a bad fusion rule silently drops evidence an agent never learns it missed.
Learned Sparse Retrieval: SPLADE and Dense Hybrid -- when the lexical half is a learned sparse model instead of plain BM25
Multi-Stage Retrieval: How Agents Search Unstructured Data -- the full candidate-generation-to-rerank pipeline fusion lives inside
Cross-Encoder Reranking -- the precision stage that orders the fused candidate list
Calibrating Similarity Scores -- making a single retriever's raw scores mean something before you ever fuse them
Evaluating Multimodal Retrieval -- the labeled-query methodology you need to tune k, alpha, and the normalizer
Key Takeaways
1. Dense and lexical retrieval cover each other's blind spots (meaning versus exact terms), so a hybrid of both beats either alone on mixed agent workloads.
2. You cannot add raw scores. Cosine similarity is narrow and bounded; BM25 is wide, unbounded, and query-dependent, so a naive sum collapses into pure lexical ranking.
3. RRF fuses by rank position, needs no labels, and is robust to scale; its k parameter controls how steeply top ranks dominate (small k = sharp, large k = rewards agreement).
4. Weighted combination keeps score margins but requires normalization first; prefer z-score over min-max because min-max lets a single rare-term spike flatten the rest, and tune alpha against a labeled set.
5. Fusion is a recall stage feeding a precision reranker, not the final ranking; tune k, alpha, and the normalizer with measurement, because a bad fusion rule silently drops evidence an agent never learns it missed.