See the full diagram →
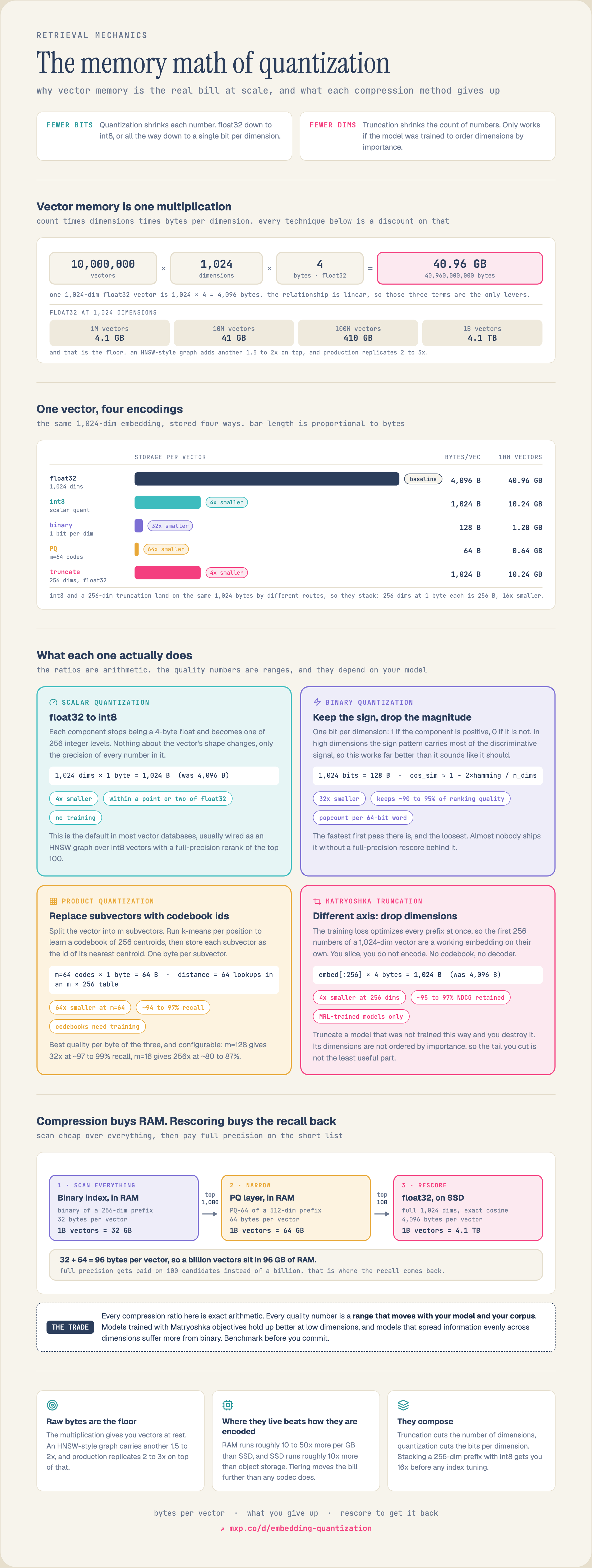
The Scale Problem
A single 1024-dimensional float32 embedding occupies 4 KB. That's nothing: until you multiply it:
| Scale | Raw Size | RAM (float32) | Annual Storage Cost |
| 1M vectors | 4 GB | 4 GB | ~$50 |
| 100M vectors | 400 GB | 400 GB | ~$5,000 |
| 1B vectors | 4 TB | 4 TB | ~$50,000 |
| 10B vectors | 40 TB | 40 TB | ~$500,000 |
The three techniques in this guide (Matryoshka embeddings, binary quantization, and Product Quantization) attack different parts of this problem. They are not mutually exclusive; production systems often stack two or three together.
Technique 1: Matryoshka Representation Learning (MRL)
The Idea
Named after Russian nesting dolls, Matryoshka embeddings are trained so that the first
d dimensions of an n-dimensional vector are themselves a valid, useful embedding. You can truncate a 1024-dim vector to 256, 128, or even 64 dimensions and still get meaningful similarity scores.This isn't post-hoc dimensionality reduction (like PCA). The training loss explicitly optimizes for quality at every truncation point simultaneously.
How It Works
During training, the loss function is a weighted sum across multiple dimensionalities:
L_total = sum(w_d * L_contrastive(embed[:d], ...) for d in [64, 128, 256, 512, 1024])
Each prefix
Matryoshka models retain surprising quality even at aggressive truncation:
The quality degradation is non-linear: the first 256 dimensions capture most of the signal. This is because the training objective forces the model to encode information by importance: dimension 1 is more important than dimension 500.
Matryoshka is now standard in modern embedding models:
Qwen3-Embedding: supports truncation down to 128d
Jina Embeddings v5: Matryoshka-native with 32-1024d range
nomic-embed-text-v2: MoE architecture with Matryoshka support
BGE-M3: multi-granularity with Matryoshka dimensions
Granite Embedding: 384d with Matryoshka support
Models without native Matryoshka support (like older CLIP variants) lose significantly more quality when truncated, because their dimensions aren't ordered by importance.
Best for: Reducing memory and compute proportionally, especially when you can tolerate 2-5% quality loss. Excellent as a first-stage retriever at 128d, followed by full-dimension reranking.
Not ideal for: Cases where you need both maximum compression AND maximum quality. At 64d, quality starts to visibly degrade for fine-grained tasks.
Replace every float32 component with a single bit: 1 if positive, 0 if negative. A 1024-dimensional float32 vector (4,096 bytes) becomes a 1024-bit binary vector (128 bytes): a 32x compression ratio.
Similarity between binary vectors is computed using the Hamming distance (count of differing bits), which can be executed in a single CPU instruction (
The relationship between cosine similarity and Hamming distance for binary-quantized vectors is:
embed[:d] must independently produce useful similarity rankings. The weights w_d are typically uniform or slightly favor larger dimensions. The effect is that the model front-loads the most important information into the first dimensions: a natural information-theoretic ordering.Quality vs. Compression
Matryoshka models retain surprising quality even at aggressive truncation:
| Dimensions | Size per Vector | Relative to 1024d | Typical NDCG Retention |
| 1024 (full) | 4,096 bytes | 1.0x | 100% |
| 512 | 2,048 bytes | 0.5x | ~98-99% |
| 256 | 1,024 bytes | 0.25x | ~95-97% |
| 128 | 512 bytes | 0.125x | ~90-94% |
| 64 | 256 bytes | 0.0625x | ~82-88% |
Which Models Support It
Matryoshka is now standard in modern embedding models:
Models without native Matryoshka support (like older CLIP variants) lose significantly more quality when truncated, because their dimensions aren't ordered by importance.
When to Use Matryoshka
Best for: Reducing memory and compute proportionally, especially when you can tolerate 2-5% quality loss. Excellent as a first-stage retriever at 128d, followed by full-dimension reranking.
Not ideal for: Cases where you need both maximum compression AND maximum quality. At 64d, quality starts to visibly degrade for fine-grained tasks.
Technique 2: Binary Quantization
The Idea
Replace every float32 component with a single bit: 1 if positive, 0 if negative. A 1024-dimensional float32 vector (4,096 bytes) becomes a 1024-bit binary vector (128 bytes): a 32x compression ratio.
Similarity between binary vectors is computed using the Hamming distance (count of differing bits), which can be executed in a single CPU instruction (
popcount) per 64-bit word. This makes binary search phenomenally fast.The Math
The relationship between cosine similarity and Hamming distance for binary-quantized vectors is:
cos_sim ≈ 1 - 2 * hamming_distance / n_dims
This approximation holds well when the original vectors are roughly unit-normalized and the signs of dimensions carry most of the discriminative information. In practice, binary quantization preserves ~90-95% of ranking quality for retrieval tasks.
The key insight: for high-dimensional vectors, the sign of each component carries far more information than its magnitude. Two vectors with the same sign pattern in 900 out of 1024 dimensions are almost certainly similar, regardless of the magnitudes.
The key insight: for high-dimensional vectors, the sign of each component carries far more information than its magnitude. Two vectors with the same sign pattern in 900 out of 1024 dimensions are almost certainly similar, regardless of the magnitudes.
Implementation
import numpy as np
def binary_quantize(embedding: np.ndarray) -> np.ndarray:
"""Convert float32 embedding to binary (packed bits)."""
binary = (embedding > 0).astype(np.uint8)
# Pack 8 bits into each byte
return np.packbits(binary)
def hamming_similarity(a: np.ndarray, b: np.ndarray) -> float:
"""Compute similarity from Hamming distance."""
xor = np.bitwise_xor(a, b)
hamming_dist = sum(bin(byte).count('1') for byte in xor)
return 1.0 - 2.0 * hamming_dist / (len(a) * 8)
# Example: 1024-dim float32 → 128 bytes
embedding = np.random.randn(1024).astype(np.float32) # 4,096 bytes
binary = binary_quantize(embedding) # 128 bytes
print(f"Compression: {embedding.nbytes} → {binary.nbytes} bytes ({embedding.nbytes / binary.nbytes:.0f}x)")
# Compression: 4096 → 128 bytes (32x)Rescoring for Quality Recovery
Binary search is fast but lossy. The standard pattern is a two-phase search:
1. Phase 1 (binary): Search the binary index for top-k candidates (e.g., k=100). This is extremely fast: millions of Hamming distance computations per second. 2. Phase 2 (rescore): Retrieve the full float32 vectors for only the top-k candidates and compute exact cosine similarity. Rerank to get the final top-n.
This gives you the speed of binary search with the quality of full-precision scoring. The overhead of phase 2 is negligible because you only rescore ~100 vectors instead of millions.
Storage Architecture
Binary index (in RAM): 128 bytes/vector → 128 GB for 1B vectors Full vectors (on disk): 4,096 bytes/vector → 4 TB for 1B vectors (SSD)
The binary index fits in RAM for fast search. Full vectors live on SSD and are only loaded for the rescore phase. This is a 32x reduction in RAM requirements.
Best for: Maximum speed on first-stage retrieval. Ideal when you have a rescore step. Works with any embedding model: no special training required.
Not ideal for: Final-stage similarity scoring without rescoring. The ~5-10% quality loss matters when precision is critical and you can't afford a second pass.
Split the vector into
This is more sophisticated than binary quantization: it preserves finer-grained distance information at the cost of more complex encoding and search.
1. Training: For each of the
2. Encoding: To encode a vector, split it into
3. Search (ADC): To compute the distance between a query and a PQ-encoded document: - Pre-compute the distance from each query sub-vector to all 256 centroids in each codebook (a
When to Use Binary Quantization
Best for: Maximum speed on first-stage retrieval. Ideal when you have a rescore step. Works with any embedding model: no special training required.
Not ideal for: Final-stage similarity scoring without rescoring. The ~5-10% quality loss matters when precision is critical and you can't afford a second pass.
Technique 3: Product Quantization (PQ)
The Idea
Split the vector into
m sub-vectors, then quantize each sub-vector independently using a small codebook of k centroids (typically k=256, representable as a single byte). A 1024-dim vector becomes m bytes instead of 4,096 bytes.This is more sophisticated than binary quantization: it preserves finer-grained distance information at the cost of more complex encoding and search.
How It Works
1. Training: For each of the
m sub-vector positions, run k-means clustering on all training vectors' sub-vectors to build a codebook of 256 centroids.2. Encoding: To encode a vector, split it into
m sub-vectors. For each sub-vector, find the nearest centroid in its codebook. Store the centroid index (1 byte) instead of the sub-vector.3. Search (ADC): To compute the distance between a query and a PQ-encoded document: - Pre-compute the distance from each query sub-vector to all 256 centroids in each codebook (a
m × 256 lookup table)
- For each encoded document, sum the looked-up distances across all m sub-vectorsd(query, doc) ≈ sum(lookup_table[i][doc_code[i]] for i in range(m))
Compression Ratios
| Config | Bytes per Vector | Compression vs float32 | Quality |
| PQ-128 (m=128) | 128 bytes | 32x | ~97-99% recall |
| PQ-64 (m=64) | 64 bytes | 64x | ~94-97% recall |
| PQ-32 (m=32) | 32 bytes | 128x | ~88-93% recall |
| PQ-16 (m=16) | 16 bytes | 256x | ~80-87% recall |
PQ vs. Binary Quantization
| Aspect | Binary Quantization | Product Quantization |
| Compression ratio | 32x (fixed) | 32-256x (configurable) |
| Search speed | Fastest (popcount) | Fast (table lookup + addition) |
| Quality at 32x | ~90-95% | ~97-99% |
| Requires training | No | Yes (codebook k-means) |
| Works with any model | Yes | Yes |
| Memory per vector (1024d) | 128 bytes | 16-128 bytes |
Combining Techniques: The Production Stack
In practice, the highest-performing systems stack these techniques:
Architecture: Matryoshka + Binary + PQ
Layer 1: Binary quantization of Matryoshka-256d (32 bytes/vector, in RAM)
→ Scan billions of vectors in milliseconds using Hamming distance
Layer 2: PQ-64 of Matryoshka-512d (64 bytes/vector, in RAM)
→ Rescore top-1000 from Layer 1 with better distance approximation
Layer 3: Full float32 at 1024d (4,096 bytes/vector, on SSD)
→ Rescore top-100 from Layer 2 with exact cosine similarityThis gives you:
Compare to naive float32 in RAM: 4 TB of RAM, upwards of $280K/year in cloud costs on the same basis used in the ANN algorithms guide (~$5,900 per TB per month on-demand). The compressed stack costs <$5K/year in cloud RAM.
FAISS and most vector databases support HNSW (Hierarchical Navigable Small World graphs) combined with PQ. The graph structure provides sub-linear search time, and PQ reduces the memory footprint of the graph nodes:
| Metric | Value |
| RAM per 1B vectors | ~96 GB (32 + 64 bytes/vector) |
| SSD per 1B vectors | 4 TB |
| Query latency | <50ms p99 |
| Recall@10 | >98% |
HNSW with Quantization
FAISS and most vector databases support HNSW (Hierarchical Navigable Small World graphs) combined with PQ. The graph structure provides sub-linear search time, and PQ reduces the memory footprint of the graph nodes:
import faiss # HNSW with PQ compression d = 1024 # dimension m = 64 # PQ sub-vectors M = 32 # HNSW connections per node index = faiss.IndexHNSWPQ(d, m, M) index.hnsw.efConstruction = 200 # build quality index.hnsw.efSearch = 64 # search quality vs speed # Train the PQ codebooks index.train(training_vectors) index.add(all_vectors) # Search distances, indices = index.search(query_vectors, k=10)
When Each Technique Matters Most
For AI Agent Perception
AI agents processing visual, audio, or document content at scale face a specific version of the cost problem: they need to embed and search content in real-time, during reasoning, with strict latency budgets.
| Agent Task | Recommended Stack | Why |
| Image search (<10M) | Full float32 + HNSW | Small enough to skip quantization |
| Video library (100M clips) | Matryoshka-256d + PQ-64 | 64x memory reduction vs 1024d float32 (4,096 -> 64 bytes); 16x from the PQ step alone, <5% quality loss |
| Document retrieval (1B pages) | Binary first-pass + PQ rescore | Needs billions in RAM, binary makes it feasible |
| Cross-modal search (mixed media) | Matryoshka-128d + binary rescore | Fast cross-modal matching, quality-sensitive rescore |
| Real-time agent tool use | Matryoshka-128d (truncated) | Minimize latency, accept quality trade-off |
Model-Specific Considerations
Not all embedding models quantize equally well. Models trained with Matryoshka objectives quantize better at lower dimensions. Models with higher intrinsic dimensionality (where information is spread evenly across all dimensions) suffer more from binary quantization.
Test your specific model before committing to a quantization strategy. A quick benchmark:
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer("BAAI/bge-m3")
# Encode your evaluation set
embeddings = model.encode(eval_texts)
# Test Matryoshka truncation
for dim in [768, 512, 256, 128, 64]:
truncated = embeddings[:, :dim]
# Run your retrieval evaluation with truncated embeddings
recall = evaluate_recall(truncated, eval_queries, eval_labels)
print(f" {dim}d: Recall@10 = {recall:.3f}")
# Test binary quantization
binary = (embeddings > 0).astype(np.float32)
recall_binary = evaluate_recall(binary, eval_queries, eval_labels)
print(f" Binary: Recall@10 = {recall_binary:.3f}")Mixpeek Implementation
Mixpeek's vector store supports all three compression techniques natively:
from mixpeek import Mixpeek
mx = Mixpeek(api_key="YOUR_KEY")
# Create a collection with quantization config
mx.collections.create(
name="video_library",
features=[{
"name": "visual_embedding",
"model": "openai/clip-vit-large-patch14",
"quantization": {
"matryoshka_dim": 256, # truncate from 768 to 256
"binary_index": True, # binary first-pass index
"pq_subvectors": 64, # PQ rescore layer
"store_full_precision": True # keep originals for final rescore
}
}]
)
# Ingest: quantization happens automatically
mx.ingest.videos(
source="s3://media/video-library/",
collection="video_library",
feature_extractors=[{
"name": "visual_embedding",
"model": "openai/clip-vit-large-patch14"
}]
)
# Search: multi-layer quantization is transparent
results = mx.retrievers.execute(
collection="video_library",
query="product unboxing with warm lighting",
features=["visual_embedding"],
top_k=10
# Internally: binary scan → PQ rescore → full-precision final rank
)The quantization pipeline is fully transparent: you configure it once at collection creation, and all ingestion and search operations use the optimal compression stack automatically.
1. Matryoshka is free compression if your model supports it. Truncating from 1024d to 256d saves 75% of memory with only 3-5% quality loss. Always check if your embedding model supports it before reaching for other techniques.
2. Binary quantization is the speed champion. 32x compression, hardware-accelerated Hamming distance, works with any model. Pair it with a rescore step for production quality.
3. Product Quantization offers the best quality-per-byte. More complex to set up (requires training codebooks), but PQ-64 achieves 64x compression with <5% quality loss.
4. Stack them. The production playbook is Matryoshka truncation → binary first-pass → PQ rescore → full-precision final rank. Each layer trades a small amount of quality for a large reduction in cost.
5. Always benchmark with your data. Quantization quality varies by model, data distribution, and task. A 15-minute benchmark saves months of production regret.
Vector Storage Tiering -- hot/warm/cold architecture for vector data
Omnimodal Embeddings -- unified embedding models that benefit from Matryoshka
Multi-Stage Retrieval -- the retrieval pipeline where quantization fits
Late Interaction Retrieval -- per-token retrieval that has different quantization needs
Contrastive Learning -- how the embedding models are trained
Models -- browse embedding models with Matryoshka support
Key Takeaways
1. Matryoshka is free compression if your model supports it. Truncating from 1024d to 256d saves 75% of memory with only 3-5% quality loss. Always check if your embedding model supports it before reaching for other techniques.
2. Binary quantization is the speed champion. 32x compression, hardware-accelerated Hamming distance, works with any model. Pair it with a rescore step for production quality.
3. Product Quantization offers the best quality-per-byte. More complex to set up (requires training codebooks), but PQ-64 achieves 64x compression with <5% quality loss.
4. Stack them. The production playbook is Matryoshka truncation → binary first-pass → PQ rescore → full-precision final rank. Each layer trades a small amount of quality for a large reduction in cost.
5. Always benchmark with your data. Quantization quality varies by model, data distribution, and task. A 15-minute benchmark saves months of production regret.